2021-04-03
机器学习与模式识别(WHUer专属,水平有限,要是没看书就急着赶作业作业的话看看没问题的)第1讲-绪论-课后作业1、(1)对一位去医院做疾病诊断的病人而言,诊断技术的查全率重要还是查准率更重要?给出理由。(2)对不断向你推荐商品的网站,该网站的商品推荐系统的查全率还是查准率你更关注?给出理由。(1)查准率重要,查全率是先验概率,查准率是后验概率。查全率:预测正确疾病数/总的疾病数;查准率:准确预测
机器学习与模式识别
(WHUer专属,水平有限,要是没看书就急着赶作业作业的话看看没问题的)
第1讲-绪论-课后作业
1、(1)对一位去医院做疾病诊断的病人而言,诊断技术的查全率重要还是查准率更重要?给出理由。(2)对不断向你推荐商品的网站,该网站的商品推荐系统的查全率还是查准率你更关注?给出理由。
(1)查准率重要,查全率是先验概率,查准率是后验概率。查全率:预测正确疾病数/总的疾病数;
查准率:准确预测数/所有预测个数。总疾病数未知,查准率更重要。
(2)查全率更重要,预测更多的心仪商品数越好,更受人关注。
2、(1)简述数据模型的泛化能力与过拟合现象这两个概念;说明两者之间存在的一般性关系。(2)借助模型的过拟合和泛化能力背后的原理,分析个人的专业学习与职业发展前景之间的关系(可以结合自己的经验)。
(1)概括地说,泛化能力是指机器学习算法对新鲜样本的适应能力,简而言之是在原有的数据集上添加新的数据集,通过训练输出一个合理的结果。学习的目的是学到隐含在数据背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力。过拟合:模型对数据学习过度,把局部特征、噪音当成一个很明显的特征并赋予一个较大的权重。
一般关系:过拟合导致泛化能力差。
(2)人生就像最优化,别陷入局部最优解而忘了全局最优解。
生活哲理就像算法,时而过拟合,时而欠拟合。鸡汤文欠拟合,实践经验过拟合。
思考就像神经网络,多加几层,抽象能力倍增。
第2讲-线性判别分类-课后作业
1、线性回归与逻辑回归在模型设定、目标函数和求解算法上,有何相似和不同之处?
线性回归主要用来做预测,逻辑回归用来做分类;线性回归拟合函数,逻辑回归预测函数;线性回归求参用最小二乘法,逻辑回归求参采用梯度下降。
2、如果你想将图片分类为户外/室内以及白天/黑夜。你应该实现两个逻辑回归分类器还是一个Softmax 回归分类器?
2个逻辑回归分类器,因为这些特征不是互斥的。
3、(1)逻辑回归实际上是用样本点的回归函数值的logistic变换值来拟合样本点属于正类的概率。简要说明这种建模方法的合理性和不合理之处。(2)能否用正态随机变量的累积分布函数来替换logistic函数,作为逻辑回归中的概率变换函数?为什么?还能想到其他的可用于逻辑回归的变换函数吗?
合理性:
(1)训练速度较快,分类的时候,计算量仅仅只和特征的数目相关;
(2)简单易理解,模型的可解释性非常好,从特征的权重可以看到不同的特征对最后结果的影响;
(3)适合二分类问题,不需要缩放输入特征;
(4)内存资源占用小,因为只需要存储各个维度的特征值;
不合理性:
(1)不能用Logistic回归去解决非线性问题,因为Logistic的决策面试线性的;
(2)对多重共线性数据较为敏感;
(3)很难处理数据不平衡的问题;
(4)准确率并不是很高,因为形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布;
(5)逻辑回归本身无法筛选特征,有时会用gbdt来筛选特征,然后再上逻辑回归
(2)理论上可以,Sigmoid函数和正态分布函数的积分形式形状非常类似。但计算正态分布的积分函数,计算代价非常大,而Sigmoid的形式跟它相似,却由于其公式简单,计算量非常的小,因此被选为替代函数。
4、一个三类问题,其判别函数为
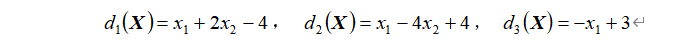
(1) 设这些函数是在多类情况1条件下确定的,绘出判别界面及每一模式类别的区域。

(2) 设为多类情况2,并使d12(x) = d1(x) ,d13(x)= d2(x) ,d23(x) = d3(x) ,绘出判别界面及每一模式类别的区域。

(3) 设d1(x) ,d2(x) 和d3(x) 是在多类情况3的条件下确定的,绘出其判别界面及每一模式类别的区域。
d1(x) – d2(x) = 6x2 – 8
d2(x) – d3(x) = 2x1 – 4x2 + 1
d1(x) – d3(x) = 2x1 + 2x2 – 7

第3、4讲-概率分类-课后作业
1、就分类而言,在模型训练前,对一个样本所来自的总体的类别变量分布的先验知识,与在模型训练后对该类别变量分布的后验知识,主要区别是什么?在什么意义下,两种是一致的?
先验知识是指根据以往经验和分析得到的,它往往作为"由因求果"问题中的"因;
后验知识是指在得到“结果”的信息后重新修正的,是“执果寻因”问题中的"果"。
2、朴素贝叶斯分类方法的基本假设是什么?试举一例说明该假设的合理性。
朴素贝叶斯算法是假设各个特征之间相互独立。
超市的数据分析显示,有些人经常同时买啤酒和尿布,但肯定不能认为买啤酒和买尿布存在什么依赖关系,实际情况可能是:一个刚刚有小孩、而且很忙的年轻父亲!
因此,在一些合适的情况下,可以认为:如果一组特征都依赖于某个目标变量(类别变量),这时可以认为:在已知产生对象特征的目标变量之值(类别)时,作为随机变量,对象的各个特征在概率意义上可认为是条件独立的。这种条件独立性,可以用来大幅减少联合条件概率分布的参数个数.
3、


4、
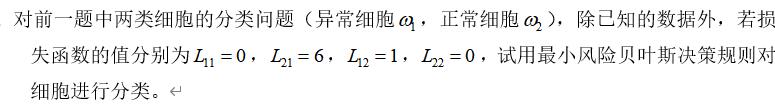

5、考虑下表中的数据集。
样本序号 A B C 类别

(1)估计以下条件概率
“P(A=1|+),P(B=1|+),P(C=1|+),P(A=1|”-"),P(B=1|"-"),P(C=1|"-")。"
(2)根据估计的条件概率,使用朴素贝叶斯方法预测样本"(A=1,B=1,C=1)" 的类别。
(3)比较"P(A=1),P(B=1)和P(A=1,B=1)," 陈述变量A、B之间的统计关系。
(4)比较"P(A=1|+),P(B=1|+)和P(A=1,B=1|+)" ,给定类+,变量A、B条件独立吗?


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)