Flink之JobManager和 TaskManager
1.什么是FlinkFlink是由Apache开发的开源分布式流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink可以执行批处理和流处理程序,Flink 将批处理(即处理有限的静态数据)视作一种特殊的流处理。2.流处理在自然环境中,数据的产生原本就是流式的。无论是来自 Web 服务器的事件数据,证券交易所的交易数据,还是来自工厂车间机器上的传感器数据,其数据都是流式的。但
1.什么是Flink
Flink是由Apache开发的开源分布式流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink可以执行批处理和流处理程序,Flink 将批处理(即处理有限的静态数据)视作一种特殊的流处理。
2.流处理
在自然环境中,数据的产生原本就是流式的。无论是来自 Web 服务器的事件数据,证券交易所的交易数据,还是来自工厂车间机器上的传感器数据,其数据都是流式的。但是当你分析数据时,可以围绕 有界流(bounded)或 无界流(unbounded)两种模型来组织处理数据,当然,选择不同的模型,程序的执行和处理方式也都会不同。
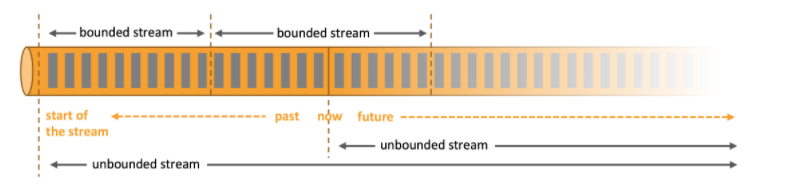
- 批处理是有界数据流处理的范例。在这种模式下,你可以选择在计算结果输出之前输入整个数据集,这也就意味着你可以对整个数据集的数据进行排序、统计或汇总计算后再输出结果。
- 流处理正相反,其涉及无界数据流。至少理论上来说,它的数据输入永远不会结束,因此程序必须持续不断地对到达的数据进行处理。
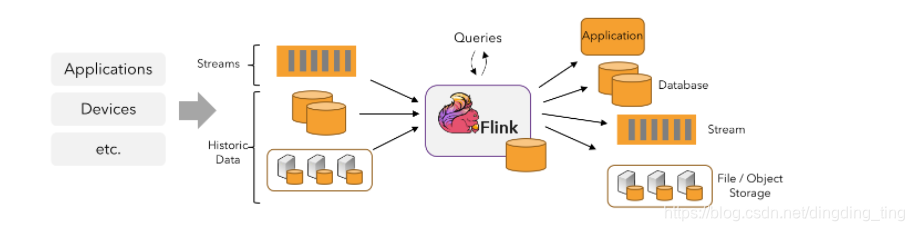
Flink 应用程序可以消费来自消息队列或分布式日志这类流式数据源(例如 Apache Kafka 或 Kinesis)的实时数据,也可以从各种的数据源中消费有界的历史数据。同样,Flink 应用程序生成的结果流也可以发送到各种数据汇中。
3.Flink集群
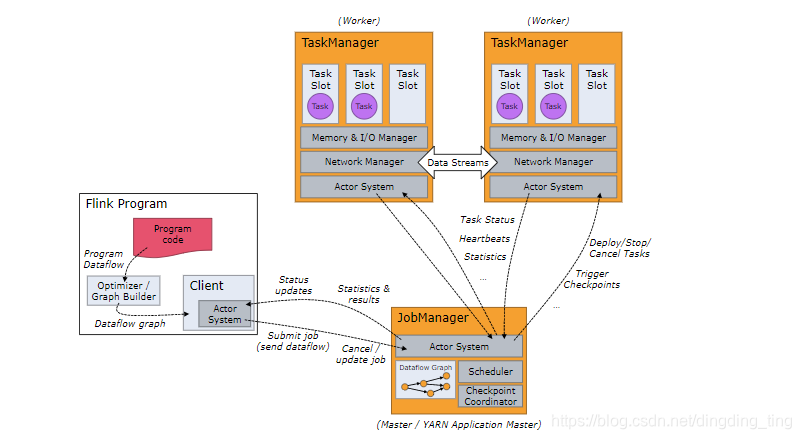
Flink 运行时由两种类型的进程组成:至少一个 JobManager 和一个或者多个 TaskManager。 在高可用(HA)模式中,可能有多个 JobManager,其中一个始终是 leader,其他的则是 standby。
Flink集群启动方式:
- 直接在机器上作为standalone 集群启动
- 在容器中启动
- 通过YARN或Kubernetes等资源框架管理并启动
(1)JobManager
JobManager :协调 Flink 应用程序的分布式执行。它决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等等。这个进程由三个不同的组件组成:
- ResourceManager: 负责 Flink 集群中的资源提供、回收、分配 。 它管理 task
slots,这是 Flink 集群中资源调度的单位。Flink 为不同的环境和资源提供者(例如
YARN、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。 - Dispatcher:提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。
- JobMaster:负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
(2)TaskManager
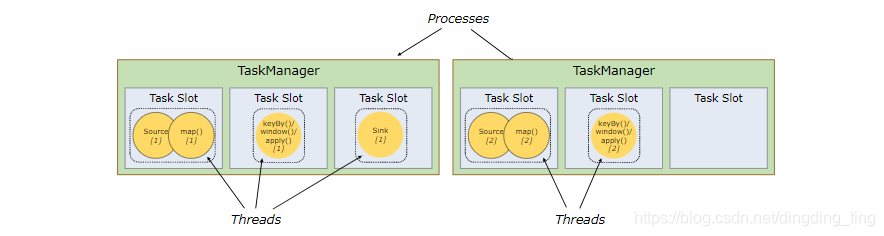
TaskManager:执行作业流的 task,并且缓存和交换数据流。在 TaskManager 中资源调度的最小单位是 task slot。TaskManager 中 task slot 的数量表示并发处理 task 的数量。
对于分布式执行,Flink 将算子的 subtasks 链接成 tasks。每个 task 由一个线程执行。将算子链接成 task 是个有用的优化:它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量。
每个 task slot 代表 TaskManager 中资源的固定子集。例如,具有 3 个 slot 的 TaskManager,会将其托管内存 1/3 用于每个 slot。分配资源意味着 subtask 不会与其他作业的 subtask 竞争托管内存,而是具有一定数量的保留托管内存。注意此处没有 CPU 隔离;当前 slot 仅分离 task 的托管内存。
通过调整 task slot 的数量,用户可以定义 subtask 如何互相隔离。每个 TaskManager 有一个 slot,这意味着每个 task 组都在单独的 JVM 中运行。具有多个 slot 意味着更多 subtask 共享同一 JVM。同一 JVM 中的 task 共享 TCP 连接(通过多路复用)和心跳信息。它们还可以共享数据集和数据结构,从而减少了每个 task 的开销。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)