【论文翻译】Meta Relational Learning for Few-Shot Link Prediction in Knowledge Graphs
【论文翻译】Meta Relational Learning for Few-Shot Link Prediction in Knowledge Graphs(基于元关系学习的小样本知识图谱链接预测) 2019年EMNLP摘要关系预测是一种重要的知识图谱补全,基于嵌入的方法对于知识图谱关系预测很有用,但对于只有少量的有效三元组来说效果甚微。本文采取了一种元学习框架(Mate-R)来实现常见缺富有
【论文翻译】Meta Relational Learning for Few-Shot Link Prediction in Knowledge Graphs
(基于元关系学习的小样本知识图谱链接预测 ) 2019年 EMNLP
摘要
关系预测是一种重要的知识图谱补全,基于嵌入的方法对于知识图谱关系预测很有用,但对于只有少量的有效三元组来说效果甚微。本文采取了一种元学习框架(Mate-R)来实现常见缺富有挑战性的小样本知识图谱关系预测。也就是说,通过观察少数几个有效三元组来预测一个新三元组的关系。我们通过传递特定关系元信息在小样本知识图谱关系链接上,来使模型学习最重要的知识并且学习的更快,特定关系元信息分别对应于Meta-R模型中的关系元和梯度元。从经验上来说,我们的模型实现了最好的结果在小样本知识图谱链接预测基点上。
1.介绍
一个知识图谱是由大量的三元组(头实体、关系、尾实体)组成用来编码世界上的知识和事实。许多知识图谱被用于各种各样的程序。
尽管拥有大量的实体、关系和三元组,但大量的知识图谱仍然不完全,因此知识图谱补全对于知识图谱的发展来说至关重要。知识图谱补全任务之一就是链接预测,基于存在的三元组预测新的三元组。对于链接预测来说,知识图谱嵌入是有效的方法。他们学习连续向量空间中实体和关系的潜在表示(称为嵌入),并通过计算和嵌入来完成链接预测。
知识图谱嵌入的有效性是在足够的训练样本之下的,因此在小样本实例中,结果会表现的很糟糕。然而小样本问题广泛存在于知识图谱中。例如在WiKi数据中大约有10%的关系少于10个三元组。只有少部分实例的关系被称之为小样本关系。在这篇论文中,我们致力于解决知识图谱当中小样本链接预测问题,在给予K个关于关系r的三元组后,通过头实体h和关系r预测尾实体t,通常来说k很小。图片1描述了一个三个样本的知识图谱链接预测。

**【图片(1)】**一个三个样本的小样本知识图谱链接预测例子。一个任务代表仅观察一个特定关系的三个实例,并对该关系进行链接预测。我们的模型专注于通过一种关系学习器来提取特定关系的元信息,并用来跨任务共享,并传输此元信息以在一个任务内进行链接预测)
为了做小样本链接预测,第一个实验和提议的是GMatching,该模型通过考虑嵌入向量和单图结构(one-hot编码)来学习匹配度量标准,当我们试图通过另一个基于直觉的观点完成小样本链接预测,该观点为:在一个任务(task)中,从一些已经存在的实例中获得的最重要的信息到不完全的三元组中应该是共通和共享的知识。我们称之为特定关系元信息(relation-specific meta information ),并通过该信息开发了元关系学习(MetaR)模型用来实现小样本链接预测。例如,在图片1 CEOof 和 CountryCapital 中的特定关系元信息将会被提取出来并通过MetaR转移,从一些存在的实例转移到不完全的三元组中。
特定关系元信息在下面的两个观点中是很有帮助的:
-
从被观测的三元组中公共关系信息到不完全的三元组中
-
仅通过观测少量实例来加速一个任务(task)中的学习过程
因此,我们准备了两种特定关系元信息:关系元和梯度元,分别对应上诉两个观点。在我们的框架MetaR中,关系元是连接头和尾实体的关系的高阶表示。在链接预测期间,在将关系元转移到不完整的三元组之前,梯度元是关系元的损失梯度,将用于进行快速更新。
与依赖背景知识图谱的GMatching相比较,我们的MetaR模型是独立于他们的,因此会更强健广泛,因为背景知识图谱在实际情况下的小样本链接预测并不容易获得。
我们采用不同的数据库来评估MetaR模型。MetaR实现了SOTA的结果,表明转移特定关系元信息在小样本链接预测任务中的成功。总的来说,我们工作的主要三个贡献如下:
- 首先我们提出了一种新颖的元关系学习框架(MetaR)来解决知识图谱中小样本链接预测问题
- 其次我们着重指出了特定关系元信息在小样本链接预测中的重要作用,并且提出了两种特定关系元信息:关系元和梯度元。实验表明这两个的贡献都相当显著。
- 然后我们的MetaR模型在小样本链接预测任务中实现了SOTA,并且我们同时分析了影响MetaR模型表现的因素。
2.相关工作
MetaR模型的任务之一是学习适合小样本链接预测任务的实体表征,并且该学习框架是受知识图谱嵌入方法的启发。此外,使用损失梯度作为一种元信息是受到MetaNet和MAML框架的启发,这两个框架是通过元学习探索小样本学习的模型。通过这两种观点,我们将知识图谱嵌入和元学习作为两个相关工作。
2.1知识图谱嵌入
知识图谱嵌入模型将实体和关系映射到连续向量空间当中去。该模型使用得分函数来确保每一个三元组的正确嵌入。和知识图谱嵌入一样,我们的MetaR模型同样需要一个得分函数,并且和嵌入模型有着主要的区别,关系r的表现形式在MetaR模型中是关系元,在嵌入模型中是嵌入编码。
一种形式是通过TransE和距离分数函数(distance score function)。TransH和TransR是两种典型使用不同模型连接头、尾和关系的模型。DistMult和ComplEx是由RESCAL模型演变而来的模型,试图使用不同方法挖掘潜在语义。还有一些其他使用卷积结构来计算三元组的模型或者使用额外信息例如实体类型和关系路径的模型,例如ConvE。以上全面总结了当前流行的知识图谱嵌入方法。
传统嵌入模型严重依赖大量的训练实例;因此被限制用来进行小样本的链接预测。而MetaR模型被设计用来填满已经存在的嵌入模型的缺点。
2.2元学习
元学习在相同的概念下仅通过少量实例快速寻找学习能力,并且不断的适应更多的概念,而这正是人类擅长的快速而持续的学习。
最近提出了几种元学习模型。通常来说,有三种元学习模型:
-
基于度量的元学习(Metric-based meta-learning),该模型学习匹配查询集和支持集的度量标准在所有任务任务上,同时这个匹配和最近邻居算法比较相似。Siamese Neural Network是一个典型的使用对称双胞胎网络计算两个输入的度量。GMatching是第一个进行知识图谱小样本链接预测的模型,该模型基于实体嵌入和局部图结构学习匹配度量,可以被视为基于度量的元学习模型。
-
基于模型的模型(Model-based method),该模型使用特殊的精心设计的部分(如记忆)来实现少样本实例的快速学习。MetaNet是一种记忆增强神经网络(memory augmented neural network (MANN) ),该模型获得元信息通过损失梯度和通过快速的参数化快速概括。
-
基于优化的方法(Optimization-based approach),该模型通过更改优化算法获得更快学习的主意。Model-Agnostic Meta-Learning 缩写为MAML是一个与模型无关的算法。该模型首先更新特定任务学习器的参数,然后通过使用上述更新的参数,可以对参数执行跨任务的元优化,就像“通过梯度的梯度”。
据我所知,One-shot relational learning for knowledge graphs 是第一个提出小样本学习知识图谱的论文。该模型是基于度量的模型,考虑使用了邻居编码器(neighbor encoder)和匹配处理器(matching processor)。邻居编码器通过一跳邻居来提高实体嵌入,匹配处理器通过LSTM块进行多步匹配。
3.任务规划
在该部分,我们提出知识图谱小样本链接预测任务的正式定义。
3.1定义:知识图谱
头实体集合、尾实体集合、三元组集合
3.2定义:知识图谱小样本链接预测任务
支持集、关系r、定义了K-shot链接预测
3.3查询集
正如定义的一样,一个小样本链接预测总是为特定关系定义的。在预测期间,通常有不止一个三元组通过支持集被预测,我们称这些被预测的三元组为查询集。
小样本链接预测的目的是通过观察少量关系r的三元组来获得预测关系r的新三元组的能力。因此训练过程是基于训练集,每一个训练集都有一个自己单独的支持集和查询集。测试集是一个单独的集合,和训练集十分相似,测试集中的关系在训练集中不应该出现。

【图片2】:概述MetaR模型,R与R~代表关系元和更新关系元,G代表梯度元

表格1 展示了具体的数据例子,在学习和测试小样本链接预测中。
个人理解:这里训练集有M个task,一个task里有一个支持集和一个查询集,都是关于一个特定关系 R i R_i Ri的三元组,所以训练集一共训练了M个关系。在测试集中有N个task,每一个task里有一个支持集和一个查询集,都是关于一个特定关系 R i R_i Ri的三元组,但测试集中的关系不能和训练集中M个关系重合。*
4.方法
为了制作一个能够获取小样本链接预测能力的模型,最重要的就是从支持集将信息转移到查询集,这里有两个问题徐要我们思考:
- 什么是在支持集和查询集中可转让的和共同的信息。
- 在一个任务中只通过少量实例如何快速学习该信息。
对于问题1,在一个任务中,所有支持集和查询集的所有三元组都是拥有相同的关系,因此,通常假设关系就是支持集和查询集中公共部分的关键。对于问题2,学习过程通常是通过梯度下降来最小化损失函数,因此梯度表明了模型的参数该如何变化。凭直觉来说,我们相信梯度对于加速学习过程来说是有价值的。
-
关系元代表了在支持集和查询集中连接头实体和尾实体的关系,并且我们在没有给任务中都抽取出关系元,用一个向量表示,并从支持集转移到查询集。
-
梯度元是关系元在支持集中的损失梯度。因为梯度元展示了关系元如何被改变来达到损失最小,因此,在转移到查询集之前,关系元是通过梯度元加速学习过程。此次更新可以看成是关系元的快速学习。
为了抽取关系元和梯度元,并且用知识图谱嵌入合并他们来解决小样本链接预测,我们建议MetaR主要包含以下两个模组:
-
关系元学习器在支持集中通过头实体和尾实体的嵌入来产生关系元。
-
嵌入学习器计算支持集和查询集中三元组的真实值,通过实体嵌入和关系元。基于嵌入学习器的损失函数,梯度元被计算且对于关系元来说是快速更新器,在转移关系元到查询集之前梯度元将被应用。
以上关于MetaR的概论和算法被展示与图片2和算法1,接下来,我们将介绍每一个模组,通过小样本预测链接任务。
4.1关系元学习器

为了从支持集中提取出关系元,我们设计了一个关系元学习器来学习在支持集中的头尾实体到关系元的匹配。关系元学习器的结构可以视为一个简单的神经网络。
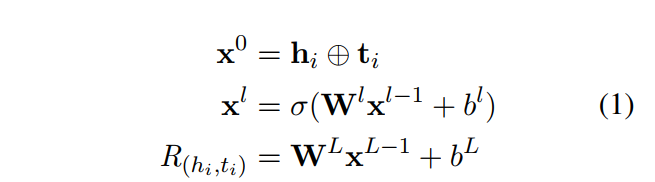
【公式1】 L层全连接的神经网络
在任务中,关系元学习器的输入是在支持集中的头尾实体对。我们首先通过L层的全连接神经网络来抽取实体对特定关系元,
h
i
h_i
hi是d维向量,
t
i
t_i
ti也是d维向量。L是神经网络的层数。
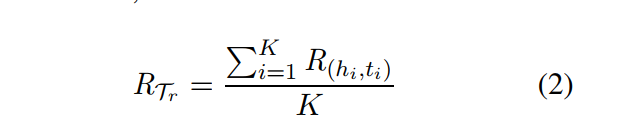
【公式2】 将K个关系元加权
4.2嵌入学习器
当我们想要得到梯度元来快速更新关系元时,我们需要一个得分函数来计算特定关系实体对的真实值,同时需要当前任务的损失函数。在我们的嵌入学习器中,采用了知识图谱嵌入模型的关键思想,因为他们被证明在知识图谱中计算三元组真实值的有效性。在任务
T
r
T_r
Tr中,我们首先计算支持集中每一个实体对的分数如下:
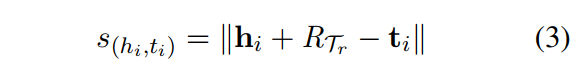
【公式(3)】 头实体加上关系元减去尾实体,其中||X||表示X的L2范数
我们设计这个分数函数受到TransE启发,TransE假设对于一个真实三元组(h,r,t)头实体的嵌入h,关系嵌入r和尾实体嵌入t, h + r = t h+r=t h+r=t是真实三元组的表达式。因此,这个得分函数是根据 h + r h+r h+r与 t t t的距离来定义的。为了转移到我们的小样本链接预测,我们将用关系元取代了关系嵌入,因为在我们的任务中并没有直接的关系嵌入,但关系元可以被视为关系嵌入。
对每一个三元组使用得分函数,可以得到如下的损失函数:
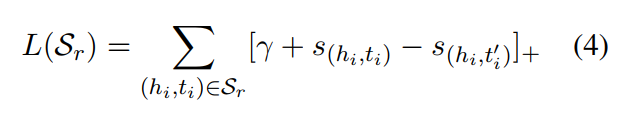
【公式(4)】 间距 + 正样本分数 - 负样本分数
所以分数越小代表效果越好。
该损失函数的值越小,就代表当前模型可以编码三元组的真实值。因此,梯度参数表明该参数如何被更新的。因此,我们将基于损失函数【公式(4)】得到的关系元作为梯度元。

【公式(5)】 梯度元 == 对损失函数进行求偏导,梯度下降后得到的关系元
接下来是梯度元更新规则,我们进行快速迭代关系元:
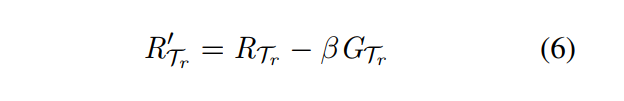
【公式(6)】 不难理解,看一下就懂了, β \beta β代表迭代步数。
当通过嵌入学习器计算查询集的时候,我们使用已经更新好的关系元。在得到已经更新好的关系元后,我们将其转移到查询集的样本中去,然后计算查询集的得分函数。

【公式(7)】 在查询集中计算得分函数,头实体加上关系元(更新后的关系元)减去尾实体,其中||X||表示X的L2范数
【公式(8)】 在查询集中计算损失函数,与公式(4)基本没区别
公式(8)就是我们的最小化训练目标。我们使用该损失函数来更新全部模型。

【表格(2)】 统计数据库,Fit表示是否将背景知识图谱放入训练任务,# Train, # Dev和# Test 分别表示在训练集中的关系数量、在确认集中关系数量、在测试集中关系数量
4.3训练目标
在训练期间,我们的训练目标就是最小化以下损失函数L,该损失函数是将所有查询集的损失函数累计在一起。
【公式(9)】 累计查询集的所有损失函数
5.实验



关于MetaR,我们需要弄清楚一下问题:
-
MetaR模型可以完成小样本链接预测任务,甚至比之前的模型做的更好吗?
-
特定关系元信息对小样本链接预测有多大的贡献?
-
MetaR模型在使用时有什么要求吗?
为了弄清楚这些问题,我们准备了两个小样本链接预测的数据集,并且深入分析了实验结果。
5.1数据集和评估标准
我们使用了两个数据集,NELL-one和WiKi-one,NELL-one和WiKi-one分别由NELL和WiKi衍生而来。并且因为这样两个数据集是也是首先被用在GMatching中作为基准。
不像GMatching一样用背景知识图谱来预训练增加嵌入表达,我们的MetaR不使用背景知识图谱进行训练。对于拥有背景知识图谱的两个数据集,我们可以将之用在训练任务、训练嵌入初始化实体。总的来说,我们有三种数据库的设定,在表格3中已经展示。对于设定BG:In-Train,为了让背景知识图谱包含着训练任务中,我们从背景知识图谱中的三元组抽取任务和原始训练集,而不是仅仅从原始数据集中抽取。
需要指出的是以上三种设定没有损害小样本链接预测的任务规定。NELL-one和WiKi-one的数据被展示在表格2。
我们使用两个传统指标来统计不同模型在这些数据集上表现,MRR和Hit@N。MRR是平均平均倒数排名(mean reciprocal rank ),Hit@N是正确实体比例排名在前N个排名中。
5.2实现参数
在训练期间,NELL和WiKi的一批数量梯度下降分别被设置为64和128。我们使用Adam梯度下降算法,初始学习率为0.001来更新参数。设置 r = 1 , β = 1 r = 1,\beta=1 r=1,β=1.正样本和负样本的三元组数量设置为3和10分别对应NELL和WiKi。每1000次训练模型会进行一次验证任务,并且当前模型参数和详细的表现将会被记录下来,在停止之后,该模型中拥有最好表现的参数会作为最终的模型参数。对于训练模型次数,我们使用30次命中来提前结束,这意味着,当在Hit@10持续命中30次的话我们就会停止。而GMatching模型,嵌入尺寸是100和50分别对应NELL-one和WiKi-one。在关系元学习器中,两个隐藏层的尺寸为500,200和250,100分别对应NELL-one和WiKi-one。
5.3结果
两个小样本链接预测的结果包含1个样本和5个样本将会被展示在表格4。我们实验的基准是GMatching,是唯一一个我们能找到的基准。在表格里,GMatching使用不同嵌入初始化的结果被誊抄上去。在表格3,我们的MetaR被测试用不同的数据集。
本段落是介绍数据,没啥好写的。
因此,第一个问题我想表示,MetaR的结果不比GMatching差,表明MetaR有能力实现小样本链接预测。同样的,一GMatching相比,这令人印象深刻的提高是来源于MetaR的中心思想,将特定关系元信息从支持集转换到查询集。
进一步,与GMatching相比,我们的MetaR模型不需要背景知识图谱。我们在1-shot上测试MetaR并取消背景知识图谱,然后得到结果。这个结果表明与GMatching任然是可比的。
5.4消融实验
我们已经证明了特定关系的元信息是MetaR的重点,关系元和梯度元。因此,我们进行了消融实验,第一个实验是标准,第二个是取消梯度元,叫-g。第三个实验是取消关系元,然后使用TransE代替,叫-g-r。实验结果如表5。
5.5影响MetaR模型的事实
我们已经证明了关系元和梯度元对本文都有巨大的贡献,但是还有其他的方面影响该实验了吗?我们从结果分析出以下两点,其中一个是实体稀疏性,另一个是训练任务task的数量。
实体稀疏性我们了解到两个数据集在不同方面各有特点,NELL-one在BG:In-Train上表现优秀,WiKi-one在BG:Pre-Train上表现优秀。
大部分数据集在小样本链接预测方面都和这两个数据集的表现一样,但是实体稀疏性在本实验的两个实体集上也有不同。仅出现一次的三元组WiKi有82.8%,而NELL只有37.1%。仅有一个三元组会让实验在训练期间不能学习到好的表征。仅依靠一个三元组,学习的实体嵌入会有大量的偏差。在这个方面,知识图谱嵌入方法表现的要比MetaR要好,因为知识图谱嵌入方可可以通过连接的关系来修正。这就是为什么WiKi-one数据集最好的表现是在BG:Pre-Train,预训练实体嵌入帮助MetaR战胜了低质量的one-shot三元组。
task任务的数量,通过实验我们发现task任务的数量也会影响MetaR的表现,NELL-One 的 BG:In-Train 有321个task时准确率是0. 401,但党没有背景知识图谱时,只有51个task,准确率只有0.279。这这合理的解释了为什么 NELL-One在BG:In-Train取得了最好的结果。
因此,我们得出结论,实体的稀疏性和任务数量都会影响MetaR的性能。 通常,通过执行更多的训练任务,MetaR的性能会更好,并且对于极度稀疏的数据集,训练前实体嵌入是首选。
6.总结
我们提出了一种元关系学习框架来实现小样本知识图谱链接预测,并且我们设计我们的模型来转移特定关系的元信息从支持集到查询集。特别地,用关系元来转移公共而且重要的信息,用梯度元来加速学习。与GMatching比较,GMatching在任务中仅有一个模型,我们的模型MetaR取得了更好的表现,并且与背景知识图谱无关。根据实验结果,我们分析到MetaR模型的表现受到训练任务数量和实体稀疏性的影响。我们考虑获得更多的在小样本知识图谱链接预测方面,有关稀疏实体有价值的信息

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)