Linux项目设计:ALSA库安装(声卡)、语音识别、文字转语音、语音转文字
文章目录一、ALSA库的安装使用(一)基本概念(二)交叉编译 ALSA 库及其工具集(三)ALSA程序模块二、科大讯飞语音识别(一)下载语音识别包(二)语音转文字包使用 (三)语音转文字包使用一、ALSA库的安装使用(一)基本概念Linux内核本身具备专门的音频模块,叫ALSA(Advanced Linux Sound Architecture,高级Linux声音架构)。ALSA是Linux处理音
文章目录
QQ交流群1:981140834
QQ交流群2:473982062
QQ交流群3:718245727
QQ交流群4:598455837
一、ALSA库的安装使用
(一)基本概念
Linux内核本身具备专门的音频模块,叫ALSA(Advanced Linux Sound Architecture,高级Linux声音架构)。ALSA是Linux处理音频的基本接口,但ALSA只提供基层的接口,操作较为繁复,一般情况下可以直接使用其附带提供的 utils 工具集,utils 工具集是一些封装好了的功能模块,直接以命令的方式提供,用户只需要敲入相关命令和参数即可实现音频操作功能。
另外,如果做类似语音控制、声音识别等深度定制的语音模块,就需要进一步了解 ALSA 的 C语言 API了。
(二)交叉编译 ALSA 库及其工具集
所需源码:
官网:https://www.alsa-project.org/wiki/Main_Page
已下载好:alsa-1.2.4.rar
alsa-lib-1.2.4.tar.bz2(ALSA库源码)
alsa-utils-1.2.4.tar.bz2(配套 utils 工具集)
① 制作 ALSA 库
解压:
gec@ubuntu:~$ tar xjvf alsa-lib-1.2.4.tar.bz2
执行配置:
gec@ubuntu:~$ cd alsa-lib-1.2.4/
gec@ubuntu:~/alsa-lib-1.2.4$ ./configure \
--prefix=/home/gec/tools \
--host=arm-none-linux-gnueabi \
--disable-python
gec@ubuntu:~/alsa-lib-1.2.4$
–prefix=/home/gec/tools :安装目录,确保要你的开发板与ubuntu都要有这个目录
–host=arm-none-linux-gnueabi 编译器
–disable-python 不使能python
编译并安装:
gec@ubuntu:~/alsa-lib-1.2.4$ make
gec@ubuntu:~/alsa-lib-1.2.4$ make install
编译完成后把生成的 /home/gec/tools 里的文件拷贝到与开发板一样的目录下!!!
② 制作 utils 工具集
解压:
gec@ubuntu:~$ tar xjvf alsa-utils-1.2.4.tar.bz2
执行配置:
gec@ubuntu:~$ cd alsa-utils-1.2.4/
gec@ubuntu:~/alsa-utils-1.2.4$ ./configure \
--host=arm-none-linux-gnueabi \
--prefix=/home/gec/tools \
--with-alsa-prefix=/home/gec/tools/lib/ \
--with-alsa-inc-prefix=/home/gec/tools/include/ \
--disable-alsamixer \
--disable-xmlto
gec@ubuntu:~/alsa-utils-1.2.4$
编译并安装:
gec@ubuntu:~/alsa-utils-1.2.4$ make
gec@ubuntu:~/alsa-utils-1.2.4$ make install
编译完成后把生成的 /home/gec/tools 里的文件拷贝到与开发板一样的目录下!!!
utils 工具集的使用
录音:
[root@GEC6818:~]# arecord -d3 -c1 -r16000 -twav -fS16_LE a.wav
说明:
-d:录音时长(duration)
-c:音轨(channels)
-r:采样频率(rate)
-t:封装格式(type)
-f:量化位数(format)
播放:
[root@GEC6818:~]# aplay a.wav
(三)ALSA程序模块
ALSA 的工具集虽然简单易用,但是无法满足个性化定制需求,比如需要在嵌入式环境下实现语音动态获取,进而进一步处理语音数据,录制声音之前不确定要录制多长时间,这时就无法使用工具集提供的建议命令了。
ALSA 提供了丰富的C-API,根据这些 API 可以创建更具创新性的程序。点击进入 C-API 官网。
下面是基于 ALSA 的 C-API 各种功能模块源码。
① WAV 格式标准(文件头)
wav 是微软公司制定的音频文件格式,跟 bmp 类似,wav只是对原始音频数据 pcm 的简单封装,一般不涉及压缩编码。操作 wav 文件,实质就是操作其头部的44个字节,这44个字节的细节规定了整个音频文件的各种参数。
wav 标准格式头实际上就是三个结构体,它们分别是:
wav_info:RIFF 段
wav_fmt:FMT 段
wav_data:DATA 段
具体细节如下:
// 1: RIFF段,大小为12字节
struct wav_info
{
uint32_t id; // 固定为'RIFF'
uint32_t size; // 除了id和size之外,整个WAV文件的大小
uint32_t format;// fmt chunk的格式,此处为'WAVE'
};
// 2: fmt段,大小为24字节
struct wav_fmt
{
uint32_t fmt_id; // 固定为'fmt '
uint32_t fmt_size; // 固定为16
uint16_t fmt; // data chunk中数据的格式代码,PCM的代码是0x0001
uint16_t channels; // 声道数目,由用户设置:1为单声道,2为立体声
uint32_t sample_rate; // 采样频率:典型值是11025Hz、22050Hz和44100Hz
uint32_t byte_rate; // 码率 = 采样率 * 帧大小
uint16_t frame_size; // 帧大小 = 声道数 * 量化级/8
uint16_t bits_per_sample; // 量化位数,由用户设置:典型值是8、16、32
};
// 3: data段,大小为8字节
struct wav_data
{
uint32_t data_id; // 固定为'data'
uint32_t data_size; // 除了WAV格式头之外的音频数据大小
};
② 字节序转换(选读)
WAV 文件需要通过互联网在各种各样的平台中使用,而各种平台的字节序是不一致的,因此想要在各种平台中畅行,就要求标准头格式中的各个字段有固定的字节序。具体约定如下:
上图中,最上面三个蓝色的区块对应头格式中的RIFF,中间绿色的区块对应头格式中的 FMT 段,下面白色的区块对应头格式中的 DATA 段。最末的“资料”实际上就是 PCM 音频数据正文了。
格式头字段及其字节序
为了确保在操作 WAV 格式数据的时候,使用正确的字节序,可以使用如下代码模块来自动根据当前平台的实际字节序调整:
#if __BYTE_ORDER == __LITTLE_ENDIAN // 判断当前平台的字节序
#define RIFF ('F'<<24 | 'F'<<16 | 'I'<<8 | 'R'<<0)
#define WAVE ('E'<<24 | 'V'<<16 | 'A'<<8 | 'W'<<0)
#define FMT (' '<<24 | 't'<<16 | 'm'<<8 | 'f'<<0)
#define DATA ('a'<<24 | 't'<<16 | 'a'<<8 | 'd'<<0)
#define LE_SHORT(val) (val)
#define LE_INT(val) (val)
#elif __BYTE_ORDER == __BIG_ENDIAN // 判断当前平台的字节序
#define RIFF ('R'<<24 | 'I'<<16 | 'F'<<8 | 'F'<<0)
#define WAVE ('W'<<24 | 'A'<<16 | 'V'<<8 | 'E'<<0)
#define FMT ('f'<<24 | 'm'<<16 | 't'<<8 | ' '<<0)
#define DATA ('d'<<24 | 'a'<<16 | 't'<<8 | 'a'<<0)
#define LE_SHORT(val) bswap_16(val)
#define LE_INT(val) bswap_32(val)
#endif
③ 硬件参数设定(选读)
音频数据涉及的参数很多,包括:
采样频率:声音的频率,一般取值:11025Hz、22050Hz和44100Hz
量化级别:一个采样点所包含的位数,一般取值:8位、16位、32位,类似于图像的色深
声道音轨:可以是单声道、双声道(立体声)、环绕声等
存储模式:对多声道音频而言,可以交错存储(帧连续)、非交错模式(音轨连续)
硬件参数一览
这些参数都必须在启动硬件设备之前,预先一一设定,详细代码实现如下:
// 0:以捕获数据模式(麦克风)打开 PCM 设备
snd_pcm_t *handle;
snd_pcm_open(&handle, “default”, SND_PCM_STREAM_CAPTRUE, 0);
// 1:定义并分配一个硬件参数变量 hwparams
snd_pcm_hw_params_t *hwparams;
snd_pcm_hw_params_alloca(&hwparams);
// 2:初始化硬件参数空间
snd_pcm_hw_params_any(handle, hwparams);
// 3:设置访问模式为交错模式(即帧连续模式)
snd_pcm_hw_params_set_access(handle,
hwparams,
SND_PCM_ACCESS_RW_INTERLEAVED);
// 4:设置量化参数,例如设置为16位
snd_pcm_format_t pcm_format = SND_PCM_FORMAT_S16_LE;
snd_pcm_hw_params_set_format(handle, hwparams, pcm_format);
// 5:设置声道数目,例如设置为单声道
snd_pcm_hw_params_set_channels(handle,hwparams, LE_SHORT(1));
// 6:设置采样频率,最终被设置的频率被存放在来 exact_rate 中
uint32_t exact_rate = LE_INT(44100);
snd_pcm_hw_params_set_rate_near(handle, hwparams, &exact_rate, 0);
// 7:设置声卡缓存为其支持的最大值
snd_pcm_uframes_t buffer_size;
snd_pcm_hw_params_get_buffer_size_max(hwparams, &buffer_size);
snd_pcm_hw_params_set_buffer_size_near(handle, hwparams, &buffer_size);
// 8:设置周期大小为声卡缓存的1/4
snd_pcm_uframes_t period_size = buffer_size / 4;
snd_pcm_hw_params_set_period_size_near(handle, hwparams, &period_size, 0);
// 9:安装以上所有的 PCM 设备参数
snd_pcm_hw_params(handle, hwparams);
// 10:获取buffer size和period size
// 注意:他们均以 frame 为单位 (一帧的大小 = 声道数 * 量化级/8)
snd_pcm_uframes_t frames_per_period; // 一个周期的帧个数
snd_pcm_uframes_t frames_per_buffer; // 声卡缓存的帧个数
snd_pcm_hw_params_get_buffer_size(hwparams,&frames_per_buffer);
snd_pcm_hw_params_get_period_size(hwparams,&frames_per_period, 0);
④ 读取音频数据(录音)(选读)
所谓录音,就是从 PCM 设备中读取数据,并妥善放入文件存储起来的过程。值得注意的是,读取音频数据以数据帧为单位,读取的模式可以是交错模式或者非交错模式。
uint8_t *p = calloc(period_size);
// 参数:
// handle: PCM 设备
// p:存放 PCM 数据的内存空间
// n:想要读取 n 帧数据
// m:真正读取 m 帧数据
snd_pcm_uframes_t m = snd_pcm_readi(handle, p, n); // 以交错模式读取
snd_pcm_uframes_t m = snd_pcm_readn(handle, p, n); // 以非交错模式读取
⑤ 写出音频数据(播放)(选读)
所谓播放,就是将音频数据写入 PCM 设备中。值得注意的是,写出音频数据以数据帧为单位,写出的模式可以是交错模式或者非交错模式。
// 参数:
// handle: PCM 设备
// data:存放 PCM 数据的内存空间
// n:想要写出 n 帧数据
// m:真正写出 m 帧数据
snd_pcm_uframes_t m = snd_pcm_writei(handle, data, n); // 以交错模式写出
snd_pcm_uframes_t m = snd_pcm_writen(handle, data, n); // 以非交错模式写出
⑥ 释放资源(选读)
snd_pcm_drain(handle);
snd_pcm_close(handle);
二、科大讯飞语音识别
(一)下载语音识别包
科大讯飞官网:https://editor.csdn.net/md?not_checkout=1&articleId=113179224
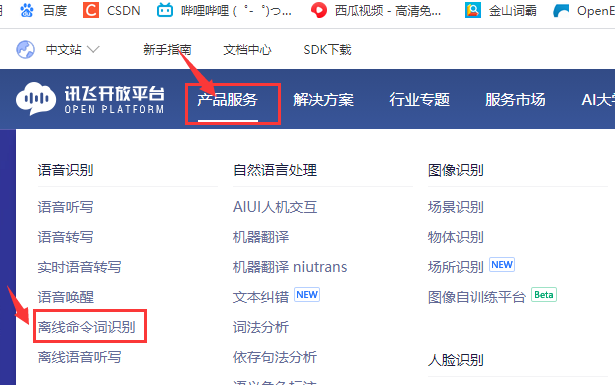
1、进入产品服务->离线命令词识别
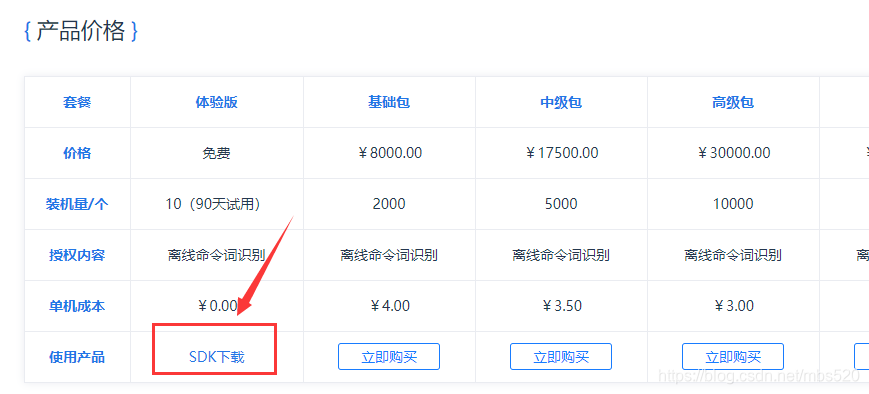
2、点击SDK下载
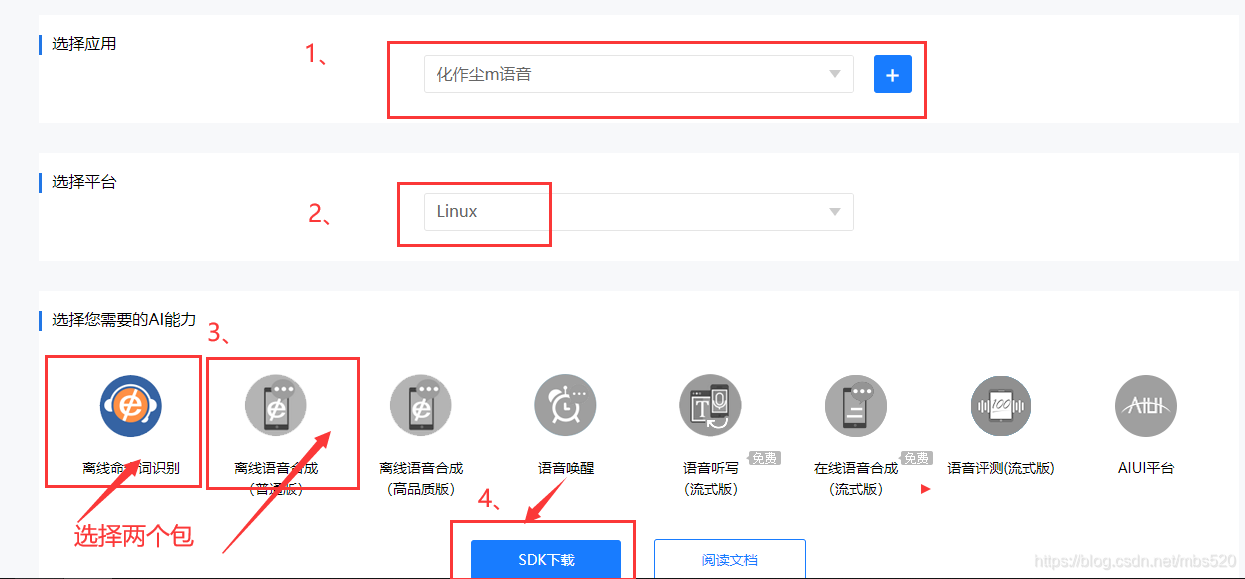
3、选择参数,下载
4、提示我已经过期,因为之前已经注册过了

这个是两个已经下载好的离线包:
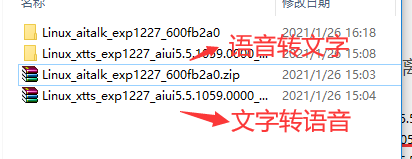
(二)文字转语音包使用
1、解压到ubuntu
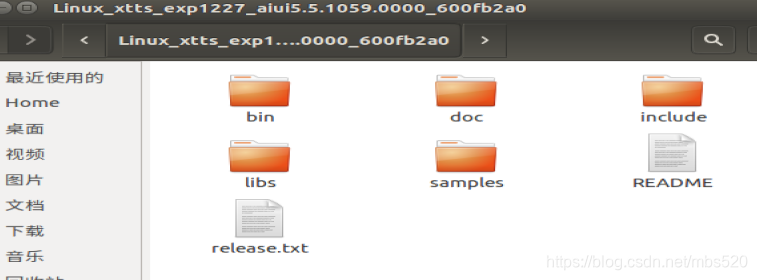
2、进入目录Linux_xtts_exp1227_aiui5.5.1059.0000_600fb2a0/samples/xtts_offline_sample
查看 tts_sample.c:要转换的文字在main函数中的151行,我们可以改变这句的文字,生成想要的语音文件
const char* text = "亲爱的用户,您好,这是一个语音合成示例,感谢您对科大讯飞语音技术的支持!科大讯飞是亚太地区最大的语音上市公司,股票代码:002230"; //合成文本
3、执行64位脚本文件生成Makefile
$ ./64bit_make.sh
4、执行Makefile
$ make
5、进入Linux_xtts_exp1227_aiui5.5.1059.0000_600fb2a0/bin,执行可执行文件
$ ./xtts_offline_sample
6、执行完毕,生成音频文件 tts_sample.wav
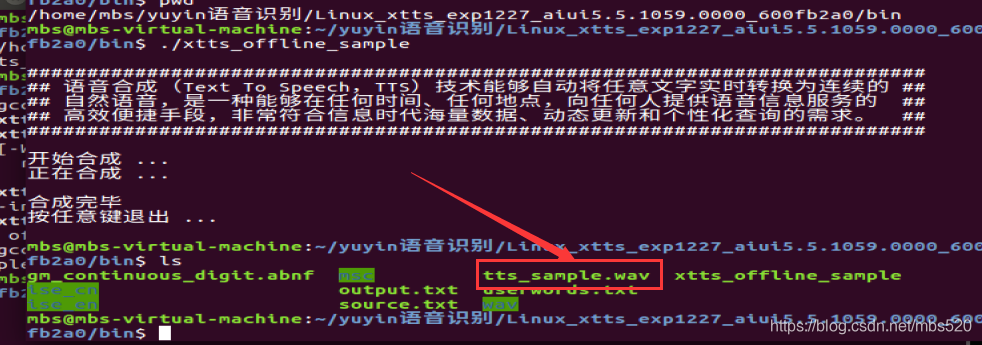
7、播放刚刚合成的语音,你将会听到可爱女声:
$ aplay tts_sample.wav
“亲爱的用户,您好,这是一个语音合成示例,感谢您对科大讯飞语音技术的支持!科大讯飞是亚太地区最大的语音上市公司,股票代码:002230”
(三)语音转文字包使用
1、解压到ubuntu,同上,先进入samples例子查看示例代码
2、查看示例代码:路径Linux_aitalk_exp1227_600fb2a0/samples/asr_offline_sample/asr_offline_sample.c
3、编译
$ ./64bit_make.sh && make
4、运行bin文件
$ cd ../../bin
$ ./asr_offline_sample
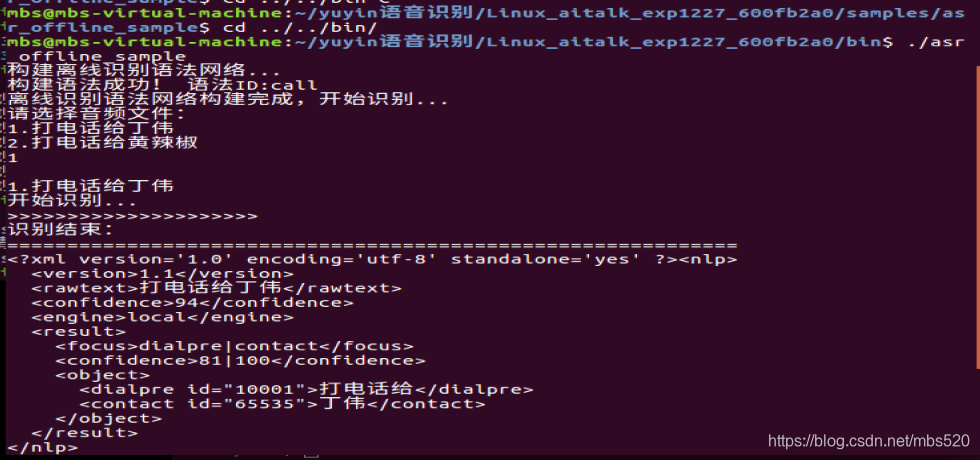
5、命令词编辑
打开bin/路径下的call.bnf配置命令词
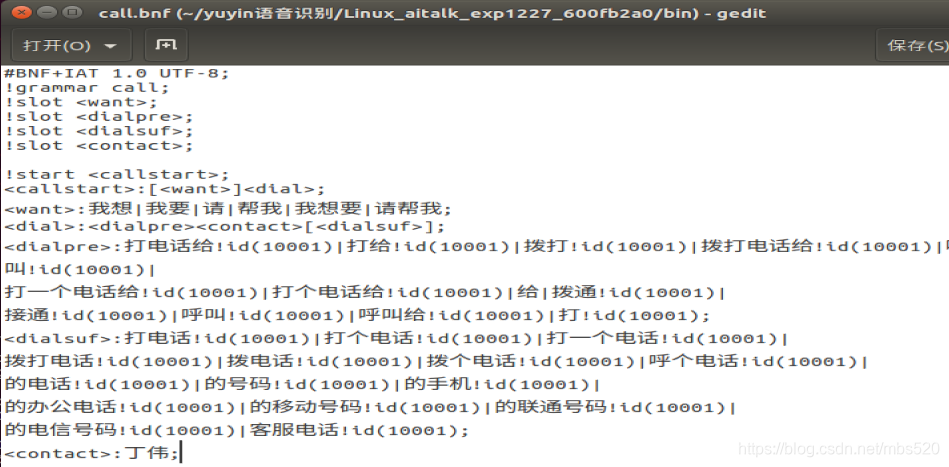
6、修改示例代码

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)