Auto-tunning调研(1):TVM
引用的文献:TVM: An Automated End-to-End Optimizing Compiler for Deep LearningTVM: End-to-End Optimization Stack for Deep LearningTVM是什么?深度学习需求非常火热,而已有的、处理深度学习作业的后端存在多样性。主流的深度学习框架将作业抽象成图的结构,来描述输入矩阵经过一系列算子(图
引用的文献:
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
TVM: End-to-End Optimization Stack for Deep Learning
TVM是什么?
深度学习需求非常火热,而已有的、处理深度学习作业的后端存在多样性。主流的深度学习框架将作业抽象成图的结构,来描述输入矩阵经过一系列算子(图节点)进行处理的workflow,这种基于计算图的方式给优化异构后端的优化带来了困难,针对新的算子优化也需要更多的人力。TVM所做的工作就是将顶层的机器学习业务逻辑跟底层的硬件优化相解耦。TVM立志于解决两个问题:1)现有的深度学习计算设备日新月异,包含很多新的、独家的特性,如果在编译器层面将这些特性利用起来。2)针对优化存在巨量的搜索空间,以CPU为例,循环展开、重排、平铺的组合就存在巨大的搜索空间。
TVM一共有两个层次的优化,一个是针对计算图结构的优化,一个是针对计算图中一个节点(算子)的自动优化。为了方便编程TVM提出了一种领域编程语言来定义一个算子的内容。从总体上来说,TVM本质是一个更接近编译器类型的工作,包含了:1)DSL代码编译;2)基于规则的优化,有计算图层面的,也有单个算子层面的;3)单个算子层面的自动调优;自动调优只占一部分。
概述
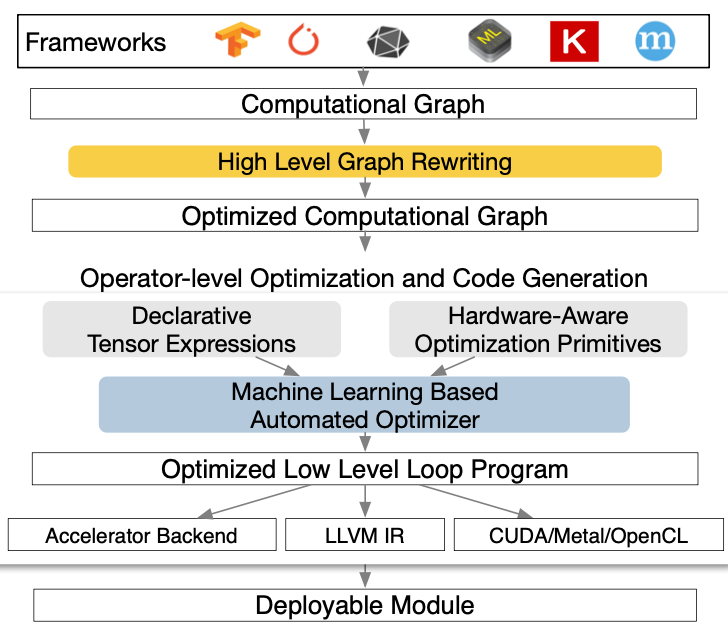
上图是TVM的架构,TVM立志于兼容已有主流的深度学习框架前端,通过获取深度学习程序的执行图,并重写执行图结构来生成经过优化的执行图。对于执行图的重写是第一个工作。针对单个算子,TVM提出做了3点工作:1)一个是算子的定义原语,包含了矩阵的计算逻辑;2)一个和硬件特点紧耦合的优化原语,用户可以定义优化手段;3)自动调优。
Graph-level的优化

如上图,用计算图(节点为算子,边为数据)作为一种手段描述执行逻辑是很常见的一种方式,无论从早期的LLVM和当今的人工智能框架。TVM可以通过修改图的结构,获得四种优化手段:1)节点(算子)融合,将多个小算子融合为一个大算子,2)常量折叠,将图中可以在运行前计算出的部分提前算出来,在运行时作为静态变量;3)静态内存分配,在计算之前为图执行产生的中间临时数据申请内存;4)数据布局转换,在数据格式转化为适合某个硬件后端的版本。
算子融合需要对算子的类型提前进行标注,要融合的两个算子需要符合特定类型才能融合。
数据布局转换主要根据硬件的特点(存储层次等)选择最合适的内部数据布局。
生成一个算子
TVM在单个算子层面的设计继承了Halide的思路,将业务的描述和优化调度解耦。

上图顶部是Tensor计算的DSL,表达了矩阵乘法的操作。这段代码的首要特点就是所有矩阵的长和宽都需要显式声明出来。在用户声明出业务逻辑之后,TVM会用户**事先声明的优化策略(schedule primitives)**来执行增量的代码转换,在将代码转化为后端具体硬件的代码的同时进行优化。上图剩下的部分展现的是典型的代码转化过程,纵向的箭头代表代码转换和优化手段的叠加,横向的过程代表了将当前经过优化的代码转换到特定硬件上。这里的优化手段是循环平铺,实际上还能有利用多层次缓存等优化手段。在工程上,继承了Halid。
TVM在单个算子层面实现了有合作的嵌套并行。主要用于数据并行的任务分配,在以往fork-join模式的并行中,fork阶段会有一个主线程准备好所有数据分配,然后子线程利用已有的数据分配来执行任务,在执行的过程中,线程之间没有交流。为了适应GPU等设备的运行模式,TVM会让不同线程合作执行数据的加载,如下图所示,这里所有线程将数据合作加载到共享内存中,按照一定步长,每个线程负责一部分:

此外,这里还引入了缓存标记来表示不同的内存层次(AS、BS表示shared memory)。此外,要计算依赖,并且给出适当的同步来保证一致性。
单个算子层面的优化还包含张量化,即可以直接在顶层DSL中直接加入硬件原语来支持硬件SIMD。下面的例子是在CPU中直接支持硬件级8*8张量计算:

TVM还为调度能力差的硬件加速器提供了显式内存延迟隐藏,也就是将计算和访存overlap起来(访问和计算的指令集并行),这在CPU这类的计算设备中很常见,主要通过硬件级调度实现。但是一些加速器比如TPU没有这样的功能,甚至TPU连线程这样的视图都没有。所以TVM需要在软件层面做好指令的调度,支持“虚拟线程”和“双流水线”。
“虚拟内存”的实现主要通过将两个指令流在加入低级别同步之后合并为一条指令流,合并之后这个问题就收敛为单个指令流的调度问题,如下图所示:

为了解决单个指令流的调度问题,引入两个流水线:访存指令流水线和计算指令流水线。通过两种指令的输入输出,可以得到两个流水线之间的指令依赖关系。然后在考虑这些依赖关系的基础上将两个流水线之间的内容穿插起来:

从上图可以看出调度的效果是显而易见的,从右边ld指令和ex指令扎堆放置的指令流变成了,左上ld和ex穿插起来的指令流。
自动调优
用户提前定义的优化规则特别多,那么什么样的优化手段以及优化中的参数组合是最优,这需要自动找出。TVM提供了两个组件解决这个问题:1)一个调度探索器用来不断产生新的优化配置,2)一个基于机器学习的代价模型来预测优化的效果。
自动优化的搜索空间是巨大的。用户对于优化手段的预定义并不是完整的,会留有很多的参数(循环展开次数,循环平铺结构)。这些参数的数量是无限的,即便执行网格化的参数搜索也有数亿大小的空间。为了降低训练的开销,TVM并不会去真正预测不同优化手段的执行时间,而是不同优化手段的优化效果的排名。使用的模型是梯度树提升模型(gradient tree boosting model)。这个模型不是神经网络的路数,需要对每一层循环进行特征提取:针对各级内存的访问量,以及针对循环的指令方法类型(向量化,并行,循环展开)。因为搜索空间非常巨大,所以不会用代价模型一个个去把所有的优化配置的最终性能预测出来,而是采用并行退火算法,从多个随机的位置开始尝试,然后从随机位置附近一步一步向优化效果好的方向寻找。
测试
TVM在GPU,嵌入式CPU和FPGA上进行了测试,获得了比一些现成的机器学习库更好数倍的性能。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)