无监督学习-实战
在无监督学习中聚类分析占据很大的比例,所以本章主要介绍几种聚类分析的算法和字典学习。聚类分许是统计、分析数据的一门技术。应用领域有:机器学习、数据挖掘、模式识别、图像分析以及生物信息等领域。常见的聚类分析算法有系聚类、K-均值聚类、基于密度的聚类、MeanShift聚类。字典学习既可以用来进行有监督问题的解决(如图像分类),也能用于无监督问题的解决(如使用字典学习对图像去噪等)1、系统聚类系统聚类
在无监督学习中聚类分析占据很大的比例,所以本章主要介绍几种聚类分析的算法和字典学习。
聚类分许是统计、分析数据的一门技术。应用领域有:机器学习、数据挖掘、模式识别、图像分析
以及生物信息等领域。
常见的聚类分析算法有系聚类、K-均值聚类、基于密度的聚类、MeanShift聚类。
字典学习既可以用来进行有监督问题的解决(如图像分类),也能用于无监督问题的解决(如使用字典学习对图像去噪等)
1、系统聚类
系统聚类又叫层次聚类,根据层次分解为自底向上(合并)和自顶向下(分裂)两种方式,即凝聚与分裂。
凝聚的层次聚类方法使用自底向上策略,即开始时令每一个对象形成自己的簇,并且迭代地把簇合并成越来越大的簇
直到所有对象都在一个簇中,或满足某个终止条件。在合并的过程中,根据指定的距离度量方式,首先找到两个最接近的
簇,然后合并它们形成一个簇,这样的过程会重复多次,直到聚类结束。分裂的层次聚类算法使用自顶向下的策略。即开始
将所有的对象看作一个簇,然后将簇划分为多个较小的簇,并且迭代把这些簇划分为更小的簇,在划分的过程中,直到最底层的簇
都足够凝聚或仅包含一个对象,或者簇内对象彼此足够相似。系统聚类的结果常用可视化方式绘制系统聚类树
2、K-均值聚类:目的是把n个点(可以是样本的一次观察或一个实例)划分到K个簇中,K是指定的簇的数目,使得每个点都属于离他最近的
均值(即聚类中心)对应簇,且类内样本尽可能地相似,而类和类之间尽可能的远离,以此作为聚类的标准。使用不同的计算簇中心
的方法,能得到K-均值聚类的其他变体,如球体K-均值聚类和K-中心点算法等。
3、基于密度的聚类
密度聚类:也称基于密度的聚类,该算法假设聚类结构能通过样本分布密度的紧密程度确定。基于密度的聚类算法主要目标是寻找被
低密度区域分离的高密度区域。与基于距离的聚类算法不同的是,基于距离的聚类算法的聚类结果是球状的簇,而基于密度的聚类算法
可以发现任意形状的聚类,这对于有噪声点的数据聚类起着重要作用。
DBSCAN是一种典型的基于密度的聚类算法,也是科学文章中最常引用的算法。这类密度聚类算法一般假定类别可以通过样本分布的紧密程度
决定。同一类别的样本,它们之间是紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在。通过将紧密相连的样本划为
一类,这样就得到了一个聚类类别。用过将各组紧密相连的样本划分为不同的类别,就得到了最终的所有聚类类别结果。
4、Mean Shift聚类
Mean Shift算法,一般是指先算出当前点的偏移均值,然后以此为新的起始点,继续移动,直到满足一定的结束条件的算法。该算法是一种无参密度
估计算法或称核密度估计算法。Mean Shift是一个向量,其方向指向当前点上概率密度梯度的方向。Mean Shift算法在很多领域都有成功的应用,例如图像平滑
、图像分割、物体跟踪等,这些均属于人工智能领域内的模式识别或计算机视觉的部分,另外也包括常规的聚类应用。
使用Python进行聚类分析和字典学习图像去噪
系统聚类:
在这里插入代码片import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy as sp
%matplotlib inline
%config InlinebBackend.figure_format="retina"
from matplotlib.font_manager import FontProperties
fonts=FontProperties(fname="/Windows/Fonts/SIMYOU.TTF/",size=15)#打开控制面板查看字体找到自带的字体
from matplotlib import cm
import matplotlib as mpl
from sklearn import cluster,datasets
from sklearn.decomposition import PCA
Iris=datasets.load_iris()
Irisdf=pd.DataFrame(data=Iris.data,columns=Iris.feature_names)
Irisdf["species"]=Iris.target
pca=PCA(n_components=3)
IrisNew=pca.fit_transform(Iris.data)
print("",pca.explained_variance_ratio_)
print("",np.sum(pca.explained_variance_ratio_))
代码进行了主成分分析后保留了三个主成分,保留了数据集99.5%的信息。下面使用sklearn库中的cluster模块的 函数进行系统聚类
#观测之间使用欧里几德距离,类间使用ward距离进行聚类分析
hicl=cluster.AgglomerativeClustering(n_clusters=3,#聚类数目
affinity='euclidean',#欧里几德距离
connectivity=None,#系统聚类
linkage='ward'#使用类间方差度量
)
hicl_pre=hicl.fit_predict(IrisNew)#预测新数据的类别
IrisNew[Iris.target==0,0]
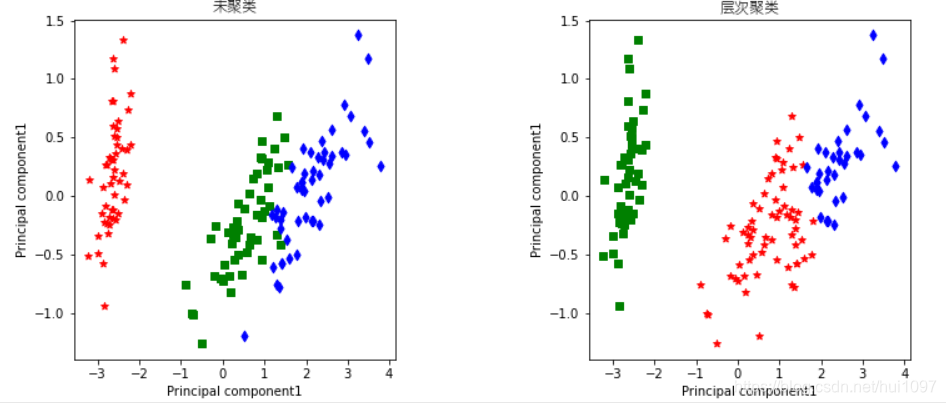
fig=plt.figure(figsize=(12,5))#在二维空间中查看聚类的结果
ax1=fig.add_subplot(121)
ax1.scatter(IrisNew[Iris.target==0,0],IrisNew[Iris.target==0,1],c="r",alpha=1,marker="*")
ax1.scatter(IrisNew[Iris.target==1,0],IrisNew[Iris.target==1,1],c="g",alpha=1,marker="s")
ax1.scatter(IrisNew[Iris.target==2,0],IrisNew[Iris.target==2,1],c="b",alpha=1,marker="d")
ax1.set_xlabel("Principal component1")
ax1.set_ylabel("Principal component1")
ax1.set_title("未聚类",fontproperties=fonts,size=12)
ax1=fig.add_subplot(122)
ax1.scatter(IrisNew[hicl_pre==0,0],IrisNew[hicl_pre==0,1],c="r",alpha=1,marker="*")
ax1.scatter(IrisNew[hicl_pre==1,0],IrisNew[hicl_pre==1,1],c="g",alpha=1,marker="s")
ax1.scatter(IrisNew[hicl_pre==2,0],IrisNew[hicl_pre==2,1],c="b",alpha=1,marker="d")
ax1.set_xlabel("Principal component1")
ax1.set_ylabel("Principal component1")
ax1.set_title("层次聚类",fontproperties=fonts,size=12)
plt.subplots_adjust(wspace=0.6)#两张图表之间的距离
plt.show()
```
系统聚类树也是查看系统聚类的一种方式,而且将数据分为几类可以根据系统聚类树的形状数量确定,这样聚类的结果更具有说服力。
下面使用scipy库中的cluster模块下的hierarchy进行系统聚类,并绘制系统聚类树。
```bash
from scipy.cluster.hierarchy import dendrogram,linkage
Z=linkage(IrisNew,method='ward',metric='euclidean')
fig=plt.figure(figsize=(12,8))
Irisdn=dendrogram(Z)
plt.axhline(y=10,color="k",linestyle="solid",label="three class")
plt.axhline(y=20,color="g",linestyle="dashdot",label="two class")
plt.title("层次聚类",fontproperties=fonts,size=12)
plt.xlabel("Sample ID",fontproperties=fonts)
plt.ylabel("Distance",fontproperties=fonts)
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False
plt.legend(loc=1)
plt.show()

(看标准线(标准线是自己画的,如上图中的绿色虚线和黑色实线)经过几个线就可以分成几类)
代码解释:
上面的程序中首先导入所需要引用的函数dendrogram(树状图),linkage(连锁),使用linkage来计算聚类结果,
聚类的数据集为IrisNew系统聚类仍然使用欧几里得距离metric='euclidean’和类间方差的度量方式method=‘ward’,
得到聚类结果为Z,接着使用dendrogram函数将linkage函数得到的系统结果转化为聚类树的形式。plt.axhline()是在
指定的位置画一条水平的直线。
从图可以看出该数据可以分成3类(以黑色实线为阈值)或2类(以绿色虚线为阈值)
K-均值聚类
首先从sklearn库中加载数据然后使用主成分分析进行数据降维,仅保留5个主成分:
wine=datasets.load_wine(return_X_y=True)
wineX=wine[0]
print(wineX.shape)
pca=PCA(n_components=5)#数据主成分降维
wineNew=pca.fit_transform(wineX)
print("累计方差贡献率",np.sum(pca.explained_variance_ratio_))
从wineX.shape的输出中,可见数据有178个样本13个特征,PCA降维保留5个特征后,仍然保留了原始数据99.9%的数据信息。K-均值聚类算法的关键在于K的取值
针对K取值,我们可以计算出不同K下类内误差平方和,然后根据数据曲线的变化合理分析K的取值,即用肘方法确定K的合适值。下面的程序将得到类内误差平方和
变化曲线
K=np.arange(1,20)
ser=[]#类内误差平方和
for ii in K:
kmean=cluster.KMeans(n_clusters=ii,random_state=1)
kmean.fit(wineNew)
ser.append(kmean.inertia_)#计算类内误差平方和
plt.figure(figsize=(12,8))
plt.plot(K,ser,"r-o")
plt.xlabel("聚类数目",fontproperties=fonts)
plt.ylabel("类内误差平方和",fontproperties=fonts)
plt.title("K-means聚类",fontproperties=fonts,size=12)
plt.xticks(np.arange(1,20,2))
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False
plt.grid()
plt.show()

程序使用cluster.KMeans()对数据进行聚类,其中参数n_clusters表示数据需要聚集的类数目,使用kmean.fit(wineNew)作用于响应的数据集,聚类后输出的
inertia_属性值即为类内误差平方和,最后绘制出曲线
当类别为3之后,类内误差平方和的变化非常平缓,说明K=3为较合理的取值(该点可以作为类内误差平方和的拐点)。接下来将数据聚为3类,并将聚类的结果
在二维直角平面坐标图上绘制出来。
kmean=cluster.KMeans(n_clusters=3,random_state=1)
k_pre=kmean.fit_predict(wineNew)
fig=plt.figure(figsize=(6,5))#在二维空间中查看聚类的结果
ax1=fig.add_subplot(111)
ax1.scatter(wineNew[k_pre==0,0],wineNew[k_pre==0,1],c="r",alpha=1,marker="*")
ax1.scatter(wineNew[k_pre==1,0],wineNew[k_pre==1,1],c="g",alpha=1,marker="s")
ax1.scatter(wineNew[k_pre==2,0],wineNew[k_pre==2,1],c="b",alpha=1,marker="d")
#绘制聚类中心
ax1.scatter(kmean.cluster_centers_[:,0],kmean.cluster_centers_[:,1],c="white",marker="o",s=80,
edgecolors='k')
ax1.scatter(kmean.cluster_centers_[:,0],kmean.cluster_centers_[:,1],c="white",marker="o",s=80,
edgecolors='k')
ax1.set_xlabel("Principal component1")
ax1.set_ylabel("Principal component1")
ax1.set_title("K-means聚类为3类",fontproperties=fonts,size=12)
plt.subplots_adjust(wspace=0.6)#两张图表之间的距离
plt.show()

from sklearn.metrics import silhouette_score,silhouette_samples
sil_score=silhouette_score(wineNew,k_pre)
sil_samp_val=silhouette_samples(wineNew,k_pre)#计算每个样本的silhouette值
plt.figure(figsize=(8,5))##绘制silhouette图
y_lower=10
n_clu=len(np.unique(k_pre))
for ii in np.arange(n_clu):#聚类为3类
##将第ii类样本的silhouette(轮廓)值放在一块排序
iiclu_sil_samp_sort=np.sort(sil_samp_val[k_pre==ii])
#计算第ii类的数量
iisize=len(iiclu_sil_samp_sort)
y_upper=y_lower+iisize
##设置ii类图像的颜色
color=cm.Spectral(ii/n_clu)#cmap = plt.cm.Spectral实现的功能是给label为1的点一种颜色,给label为0的点另一种颜色
plt.fill_betweenx(np.arange(y_lower,y_upper),0,iiclu_sil_samp_sort,facecolor=color,alpha=0.7)
plt.text(-0.05,y_lower+0.5*iisize,str(ii))
#更新
y_lower=y_upper+5
plt.axvline(x=sil_score,color='red',label="mean:"+str(np.round(sil_score,3)))
plt.xlim([-0.1,1])
plt.yticks([])
plt.legend(loc=1)
plt.xlabel("Silhouette Coefficient value")
plt.ylabel("Cluster label")
plt.title("Silhouette value for Kmeans cluster")
plt.show()

可以看出平均轮廓值为0.571,并且各类中每个样本的轮廓值均大于0,可以说明该数据聚类为3类的效果比较好。轮廓值的取值范围在-1和1之间
而且越接近1,说明距聚类的效果越好。如果一个实例的轮廓值小于0,说明该实例不适合归为相应的簇,反之则表示适合归为相应的簇
密度聚类
密度聚类是一种无需指定聚类数目的一种聚类方法,可以根据领域阈值合理地将数据聚类,甚至可以识别出噪声数据。
1.使用skimage库中的io模块的imread()函数读取图像数据集,该函数读取后输出的结果为numpy数组,图像读取后需要对图像数据做进一步的预处理
操作。
from skimage.io import imread #从skimage库中引入读取图片的函数
im=imread("辣椒2.tiff")
# print(im[:,:,0])
red=im[:,:,0]
green=im[:,:,1]
blue=im[:,:,2]
orginal_shape=red.shape#图像的大小
#将每个像素点作为样本
samples=np.column_stack([red.flatten(),green.flatten(),blue.flatten()])
#像素点的个数
size=samples.shape[0]
#随机抽取1000个点计算他们的欧氏距离的均值
index=np.random.permutation(size)[0:1000]
dist=sp.spatial.distance_matrix(samples[index,:],samples[index,:])
print(dist.mean())
cdb=cluster.DBSCAN(eps=50, min_samples=4000, metric="euclidean")
labels=cdb.fit_predict(samples).reshape(orginal_shape)
print(labels)
plt.figure(figsize=(10,5))
plt.subplot(121)
plt.imshow(im)
plt.axis("off")
plt.title("原始图像",fontproperties=fonts)
plt.subplot(122)
cmap=mpl.colors.ListedColormap(["black","yellow","green","red"])
plt.imshow(labels,cmap=cmap)
plt.colorbar(fraction=0.046,pad=0.03,ticks=np.unique(labels))
plt.axis("off")
plt.title("DBSCAN分割结果",fontproperties=fonts,size=12)
plt.show()

im=imread("辣椒.tiff")
# print(im[:,:,0])
red=im[:,:,0]
green=im[:,:,1]
blue=im[:,:,2]
orginal_shape=red.shape#图像的大小
#将每个像素点作为样本
samples=np.column_stack([red.flatten(),green.flatten(),blue.flatten()])
#像素点的个数
size=samples.shape[0]
#随机抽取1000个点计算他们的欧氏距离的均值
index=np.random.permutation(size)[0:10000]
dist=sp.spatial.distance_matrix(samples[index,:],samples[index,:])
print(dist.mean())
bandwidth=cluster.estimate_bandwidth(samples,quantile=0.2,n_samples=1000)
cms=cluster.MeanShift(bandwidth=bandwidth,bin_seeding=True)
cms.fit(samples)
cluster_centers=cms.cluster_centers_
cluster_centers
labels=cms.labels_.reshape(orginal_shape)
labels
plt.figure(figsize=(10,5))
plt.subplot(121)
plt.imshow(im)
plt.axis("off")
plt.title("原始图像",fontproperties=fonts)
plt.subplot(122)
cmap=mpl.colors.ListedColormap(["green","red","black","yellow","m"])
plt.imshow(labels,cmap=cmap)
plt.colorbar(fraction=0.046,pad=0.03,ticks=np.unique(labels))
plt.axis("off")
plt.title("Mean Shift聚类分割结果",fontproperties=fonts,size=12)
plt.show()
字典学习图像去噪(**)
字典学习在图像和信号处理中是一种重要的算法,常用于图像去噪,分类等。
import sklearn.decomposition as skd
#将2D图像转化为块的集合
from sklearn.feature_extraction.image import extract_patches_2d
#从所有的块中重构图像
from sklearn.feature_extraction.image import reconstruct_from_patches_2d
from skimage.color import rgb2gray
from skimage.util import random_noise
im=imread("莱娜.tiff")
# plt.imshow(im)
orimga=rgb2gray(im)#变成灰度图
mode='gaussian'#图像添加噪声
sigma=30#噪声的标准差
sigma2=sigma**2/(255**2)
noimga=random_noise(orimga,mode=mode,var=sigma2,seed=1243,clip=True)
print("noimga",noimga.min(),"~",noimga.max())
#将图像转化为图像块样本
patch_size=(10,10)
##使用带噪声图像训练字典
noimgadata=extract_patches_2d(noimga,patch_size)
noimgadata=noimgadata.reshape(noimgadata.shape[0],-1)
noimgadata=noimgadata.T
iterp=noimgadata.mean(axis=0)#计算每个图像块的均值
print(iterp.shape)
noimgadata=noimgadata-iterp#图像块减去相应的均值
noimgadata=noimgadata.T#再次转置
print("训练模型数据 shape is",noimgadata.shape)
print("带噪声图像取值为",noimgadata.min(),"~",noimgadata.max())
print("noimgadata.shape",noimgadata.shape)
def DCTdict(m,n):#使用DCT字典作为初始化字典
"""
构造一个二维可分离的DTC字典,该字典为DCT字典,大小为(m*2,n*2)(m,n)为一维DCT矩阵的大小
return:我们得到一个二维的DTC字典矩阵
use:DCTdict(8,16)
"""
dictionary=np.zeros((m,n))
for k in range(n):
V=np.cos(np.arange(0,m)*np.pi*k/n)
if k>0:
V=V-np.mean(V)
dictionary[:,k]=V/np.linalg.norm(V)
dictionary=np.kron(dictionary,dictionary)
dictionary=dictionary.dot(np.diag(np.sum((dictionary*dictionary),axis=0)))
return dictionary
m=16#字典原子数目为m**2
n=patch_size[0]
dctdictionary=DCTdict(m,n)#初始化DTC字典
n_components=m**2#字典原子数目
n_iter=100#迭代次数
code,dictionary=skd.dict_learning_online(noimgadata,n_components=n_components,alpha=0.2,n_iter=n_iter,return_code=True,method='lars',n_jobs=6,
dict_init=dctdictionary,random_state=1234)
print("dictionary shape=",dictionary.shape)
print("sparse code shape=",code.shape)
denoimgadata=np.dot(code,dictionary)
denoimgadata=denoimgadata.T
denoimgadata=denoimgadata+interp
denoimgadata=denoimgadata.T
patch=denoimgadata.reshape(len(denoimgadata),*patch_size)
denoimga=reconstruct_from_patches_2d(patch,orimga.shape)
print("denoimga.shape",denoimga.shape)
position=[100,100]#图片位置
size=40#图像大小
##图像块的位置索引
xx=np.linspace(position[0],position[0]+size,num=size+1)
yy=np.linspace(position[1],position[1]+size,num=size+1)
index1,index2=np.uint8(np.meshgrid(xx,yy))
#提取三个图像块
orimpatch=orimga[index1,index2]
noimpatch=noimga[index1,index2]
denoimpatch=denoimga[index1,index2]
#查看6幅图像
plt.figure(figsize=(18,12))
plt.subplot(231)
plt.imshow(orimga,cmap=plt.cm.gray)
#绘制图像块的位置
plt.vlines(x=position[0],ymin=position[1],ymax=position[1]+size,colors='red')
plt.vlines(x=position[0]+size,ymin=position[1],ymax=position[1]+size,colors='red')
plt.hlines(y=position[1],xmin=position[0],xmax=position[0]+size,colors='red')
plt.hlines(y=position[1]+size,xmin=position[0],xmax=position[0]+size,colors='red')
plt.axis("off")
plt.title("Original Image")
plt.subplot(232)
plt.imshow(noimga,cmap=plt.cm.gray)
plt.vlines(x=position[0],ymin=position[1],ymax=position[1]+size,colors='red')
plt.vlines(x=position[0]+size,ymin=position[1],ymax=position[1]+size,colors='red')
plt.hlines(y=position[1],xmin=position[0],xmax=position[0]+size,colors='red')
plt.hlines(y=position[1]+size,xmin=position[0],xmax=position[0]+size,colors='red')
plt.axis("off")
plt.title("Noisy Image $\sigma=30$")
plt.subplot(233)
plt.imshow(denoimga,cmap=plt.cm.gray)
plt.vlines(x=position[0],ymin=position[1],ymax=position[1]+size,colors='red')
plt.vlines(x=position[0]+size,ymin=position[1],ymax=position[1]+size,colors='red')
plt.hlines(y=position[1],xmin=position[0],xmax=position[0]+size,colors='red')
plt.hlines(y=position[1]+size,xmin=position[0],xmax=position[0]+size,colors='red')
plt.axis("off")
plt.title("Denoisy Image")
#绘制三个图像块
plt.subplot(234)##原始图像块
plt.imshow(orimpatch,cmap=plt.cm.gray)
plt.axis("off")
plt.title("Original Image patch")
plt.subplot(235)##噪声图像块
plt.imshow(noimpatch,cmap=plt.cm.gray)
plt.axis("off")
plt.title("Noisy Image patch")
plt.subplot(236)##去噪图像图像块
plt.imshow(denoimpatch,cmap=plt.cm.gray)
plt.axis("off")
plt.title("Denoisy Image patch")
plt.subplots_adjust(wspace=0.08,hspace=0.08)
plt.show()


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)