python基础——apply(),applymap(),map()方法的区别
import pandas as pdimport numpy as npfrom pandas import DataFramefrom pandas import Seriesdf= DataFrame({"a":[-1,2,3],"b":[3,-5,7],})输出:df.apply(lambda x:x+1)输出:df.applymap(lambda x:x+1).
·
在Python中要对数据使用函数,可以借助apply(),applymap(),map() 来应用函数,括号里面可以是直接函数式,或者自定义函数(def)或者匿名函数(lambad)。
下面,我们定义个一个DataFrame,进行案例说明:
import pandas as pd
import numpy as np
from pandas import DataFrame
from pandas import Series
df= DataFrame({
"a":[-1,2,3],
"b":[3,-5,7],
})输出:

1、apply()函数
当我们要对数据框(DataFrame)的数据进行按行或按列操作时用apply()函数。
df.apply(lambda x:x.max()-x.min(),axis=1) #按照行取极差。输出:
0 4
1 7
2 4
dtype: int64有些时候,我们发现,不用指定行/列也可以,这个时候就和applymap的用法类似了。如下:
df.apply(lambda x:x+1)输出:

2、applymap()函数
当我们要对数据框(DataFrame)的每一个数据进行操作时用applymap()函数,返回结果是DataFrame格式。
df.applymap(lambda x : 1 if x>0 else 0)输出:

以下和apply的用法类似。
df.applymap(lambda x:x+1)输出:
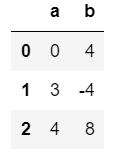
如以下我们就不能使用applymap,applymap是对df中的每个元素(int)进行计算的,int是没有max()函数的。如下:
df.applymap(lambda x:x.max()-x.min())输出:
AttributeError: 'int' object has no attribute 'max'同样,因为applymap是对df中的每个元素(int)进行计算的,没有通过axis指定行列这一说。如下:
df.applymap(lambda x:x.max()-x.min(),axis=1)输出:
TypeError: applymap() got an unexpected keyword argument 'axis'3、map()函数
当我们要对Series的每一个数据进行操作时用map()函数。
df['a'].map(lambda x :x+ 1)输出:
0 0
1 3
2 4
Name: a, dtype: int64同样,map是对Series的每一个数据进行操作的。所以无法直接对df进行操作,如下:
df.map(lambda x :x+ 1)输出:
AttributeError: 'DataFrame' object has no attribute 'map'

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)