pod卡住terminating排查记录
背景线上某环境,遇到pod删除时一直卡在terminating的问题,之前通过kubectl delete pod --force --grace-period=0强制删除过2次,但问题反复多次出现,需要调查下详细原因。kubernetes版本为v1.16.6,docker版本18.09.9,containerd版本v1.2.6.排查调查terminating的pod所在节点的message日志,
背景
线上某环境,遇到pod删除时一直卡在terminating的问题,之前通过kubectl delete pod --force --grace-period=0强制删除过2次,但问题反复多次出现,需要调查下详细原因。kubernetes版本为v1.16.6,docker版本18.09.9,containerd版本v1.2.6.

排查
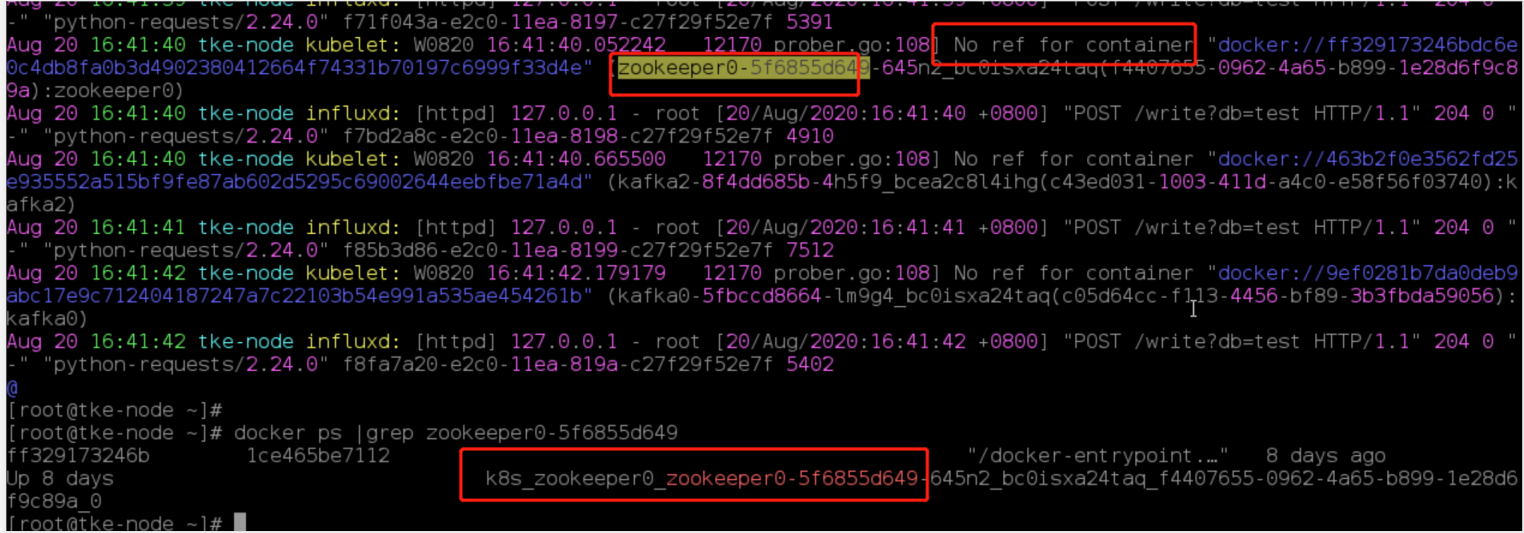
- 调查terminating的pod所在节点的message日志,发现kubelet对这个状态的pod提示“prober.go:103] No ref for container "docker:xxx“的报错。 但是docker ps 显示pod对应的容器是存在的。
-
同时检索message日志,发现kubelet对一个卡住terminating的pod,有如下报错
ff3291732为名为zookeeper0-xxx的pod对应的容器的ID
Aug 20 10:25:54 tke-node kubelet: E0820 10:25:54.561334 12170 remote_runtime.go:243] StopContainer "ff329173246bdc6e0c4db8fa0b3d4902380412664f74331b70197c6999f33d4e" from runtime service failed: rpc error: code = Unknown desc = operation timeout: context deadline exceeded
Aug 20 10:25:54 tke-node kubelet: E0820 10:25:54.562667 12170 kuberuntime_container.go:590] Container "docker://ff329173246bdc6e0c4db8fa0b3d4902380412664f74331b70197c6999f33d4e" termination failed with gracePeriod 30: rpc error: code = Unknown desc = operation timeout: context deadline exceeded
从kubelet日志大致可以看出,kubelet通过调用runtime(环境为docker),进行StopContainer操作时,runtime没有正常返回,导致调用超时退出,进而使pod一直卡在了terminating状态,问题在docker本身的可能性很高,下一步,应该查找docker日志分析为何docker没有响应StopContainer的操作。
-
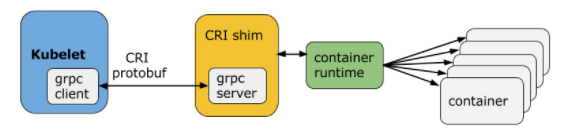
查找节点的docker日志,确发现没有任何信息。只能调查kubelet对runtime的调用链。在 v1.6.0 后, Kubernetes 开始默认启用 CRI(容器运行时接口)。
CRI 为 kubelet 提供一套抽象的容器调度的接口,主要定义了两个 grpc interface.
RuntimeService:容器(container) 和 (Pod)Sandbox 运行时管理ImageService:拉取、查看、和移除镜像
Kubelet 使用 gRPC 框架利用 Unix socket 同容器运行时(或者是 CRI 代理)进行通信,这一过程中 Kubelet 是客户端,CRI 代理是服务端。
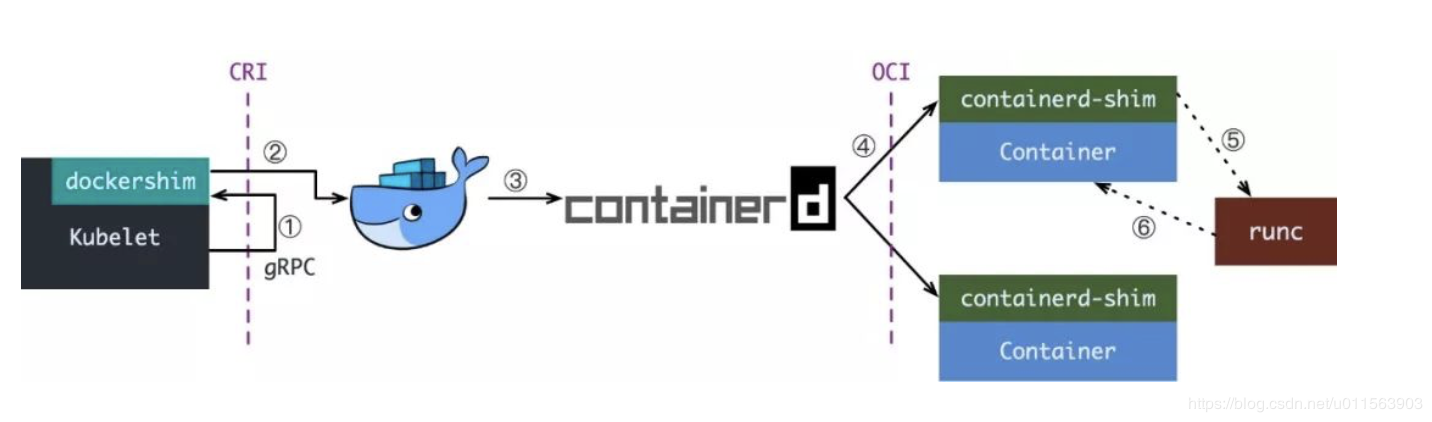
CRI 是K8S 定义的一套容器运行时接口,基于gRPC通讯,但是docker不是基于CRI的,因此 kubelet 又把docker 封装了一层,搞了一个所谓的shim,也即是dockershim的东西,dockershim 作为一个实现了CRI 接口的gRPC服务器,供 kubelet 使用。这样的过程其实就是,kubelet作为客户端 通过gRPC调用dockershim服务器,dockershim 内部又通过docker客户端走 http 调用 docker daemon api,多走了一次通讯的开销。下图是目前默认使用docker作为容器引擎的时候,调用过程。
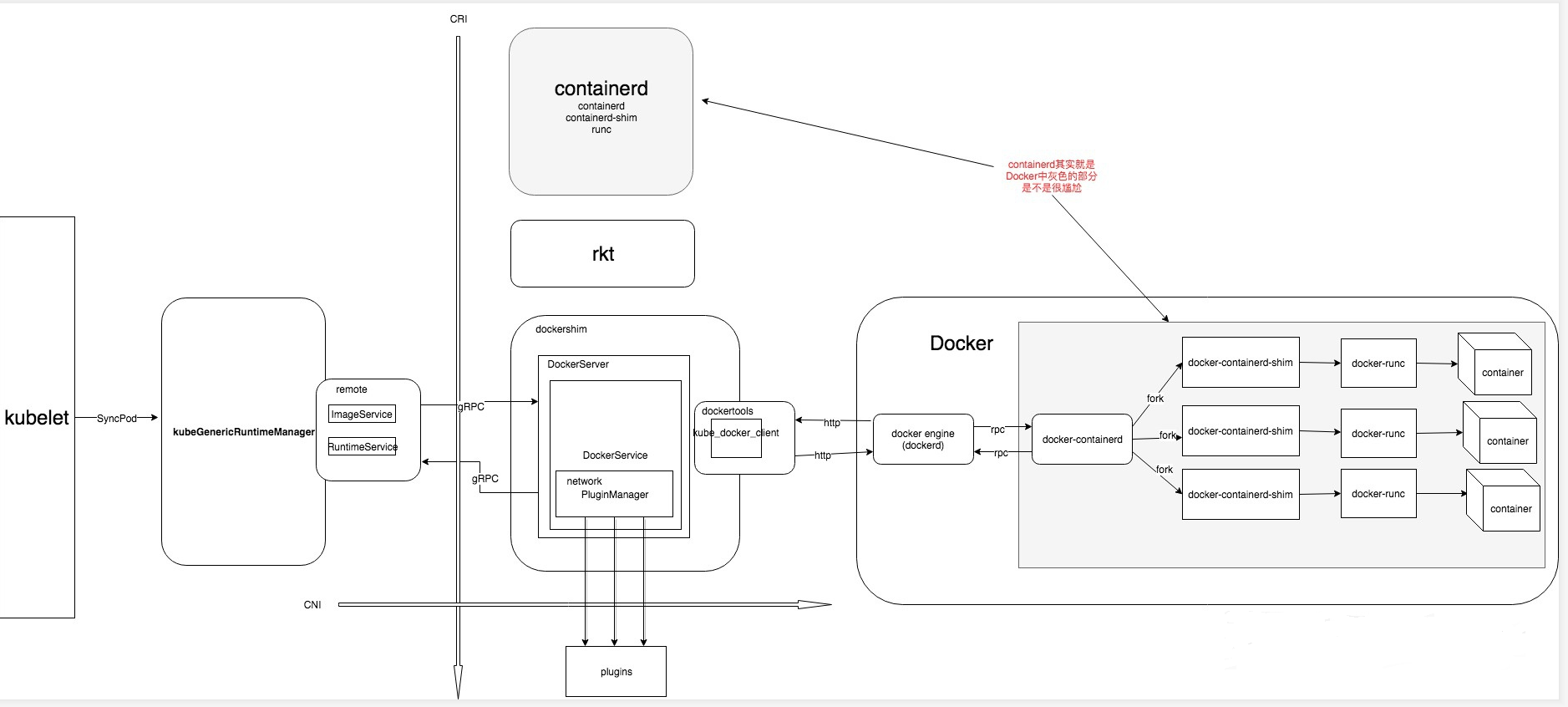
换个视角, dockershim -> containerd 的流程 (称为 docker cri)如下
-
Kubelet 通过 CRI 接口(gRPC)调用 dockershim,请求创建一个容器。CRI 即容器运行时接口(Container Runtime Interface),这一步中,Kubelet 可以视作一个简单的 CRI Client,而 dockershim 就是接收请求的 Server。目前 dockershim 的代码其实是内嵌在 Kubelet 中的,所以接收调用的凑巧就是 Kubelet 进程 -
dockershim 收到请求后,转化成 Docker Daemon 能听懂的请求,发到 Docker Daemon 上请求创建一个容器。 -
Docker Daemon 早在 1.12 版本中就已经将针对容器的操作移到另一个守护进程——containerd 中了,因此 Docker Daemon 仍然不能帮我们创建容器,而是要请求 containerd 创建一个容器; -
containerd 收到请求后,并不会自己直接去操作容器,而是创建一个叫做 containerd-shim 的进程,让 containerd-shim 去操作容器。这是因为容器进程需要一个父进程来做诸如收集状态,维持 stdin 等 fd 打开等工作。而假如这个父进程就是 containerd,那每次 containerd 挂掉或升级,整个宿主机上所有的容器都得退出了。而引入了 containerd-shim 就规避了这个问题(containerd 和 shim 并不是父子进程关系),这样最大的好处就是可以方便的实现live-restore能力,也就是即使containerd重启也不会影响到容器进程; -
我们知道创建容器需要做一些设置 namespaces 和 cgroups,挂载 root filesystem 等等操作,而这些事该怎么做已经有了公开的规范了,那就是 OCI(Open Container Initiative,开放容器标准)。它的一个参考实现叫做 runC。于是,containerd-shim 在这一步需要调用 runC 这个命令行工具,来启动容器; -
runC 启动完容器后本身会直接退出,containerd-shim 则会成为容器进程的父进程,负责收集容器进程的状态,上报给 containerd,并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理,确保不会出现僵尸进程。
-
可以看出上面的kubelet到docker runtime的调用链很长。在腾讯云原生的一篇文章-《Pod Terminating原因追踪系列之一containerd中被漏掉的runc错误信息》(https://blog.csdn.net/yunxiao6/article/details/108120909),提到了kubelet的pod删除流程,虽然文章里面使用的环境直接使用的containerd,没有使用docker,结合上面CRI的分析,大体类似。
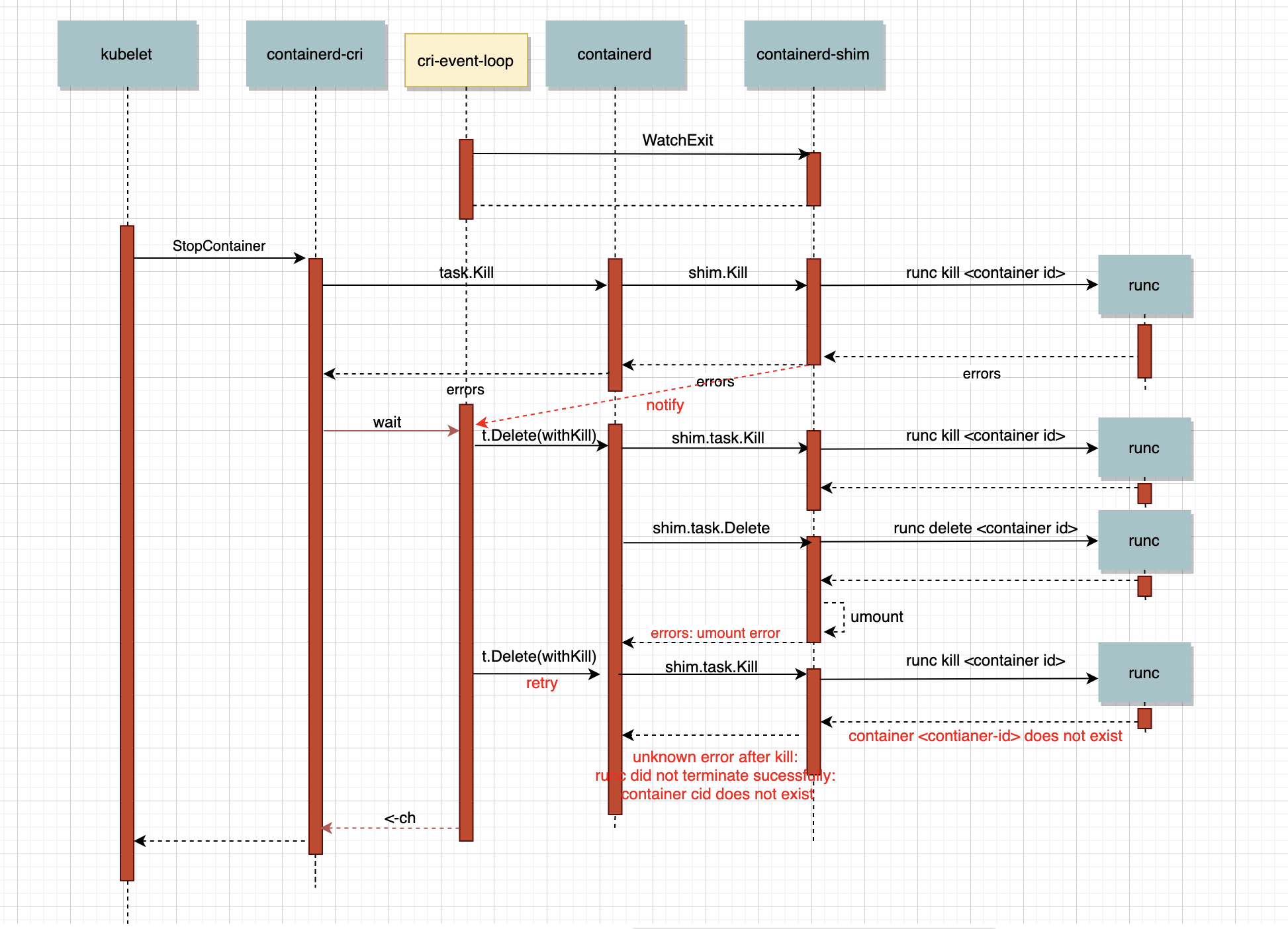
CRI插件中存在一个eventloop专门处理从containerd中获取的event。比如当容器删除后,会收到TaskExit事件,这是cri会做清理工作;比如当容器oom时,会收到OOMKill事件,cri除了清理还会更新Reason。文章也提到,过长调用链容易经常出现的docker和containerd数据不一致问题。
-
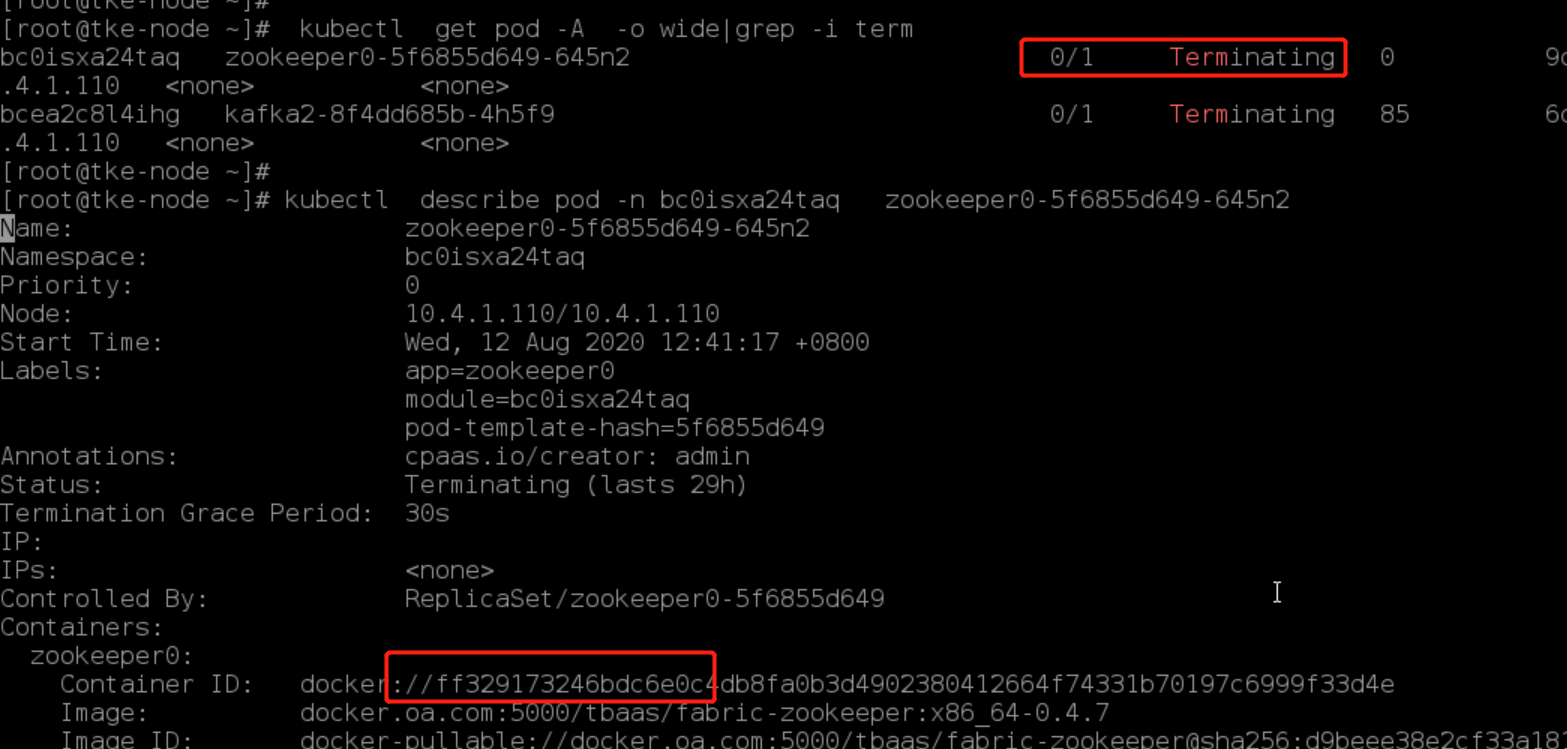
于是检查容器在docker和containerd状态,确实发现不一致。
# xxx为容器的ID,可通过kubectl describe pod获得 ctr --namespace moby --address /var/run/docker/containerd/containerd.sock task list|grep xxx docker ps |grep xxx

如上图,名为zookeeper0-xxx的pod,容器IDff3291732,通过containerd的ctr task list,显示在containerd中容器状态是 stopped。dockper ps确显示容器在docker中为UP状态。
-
google为何出现状态不一致,发现github有这方面issue-【process exited, containerd task is stopped, but docker container is running】(https://github.com/docker/for-linux/issues/779),在此链接中,提到如下信息

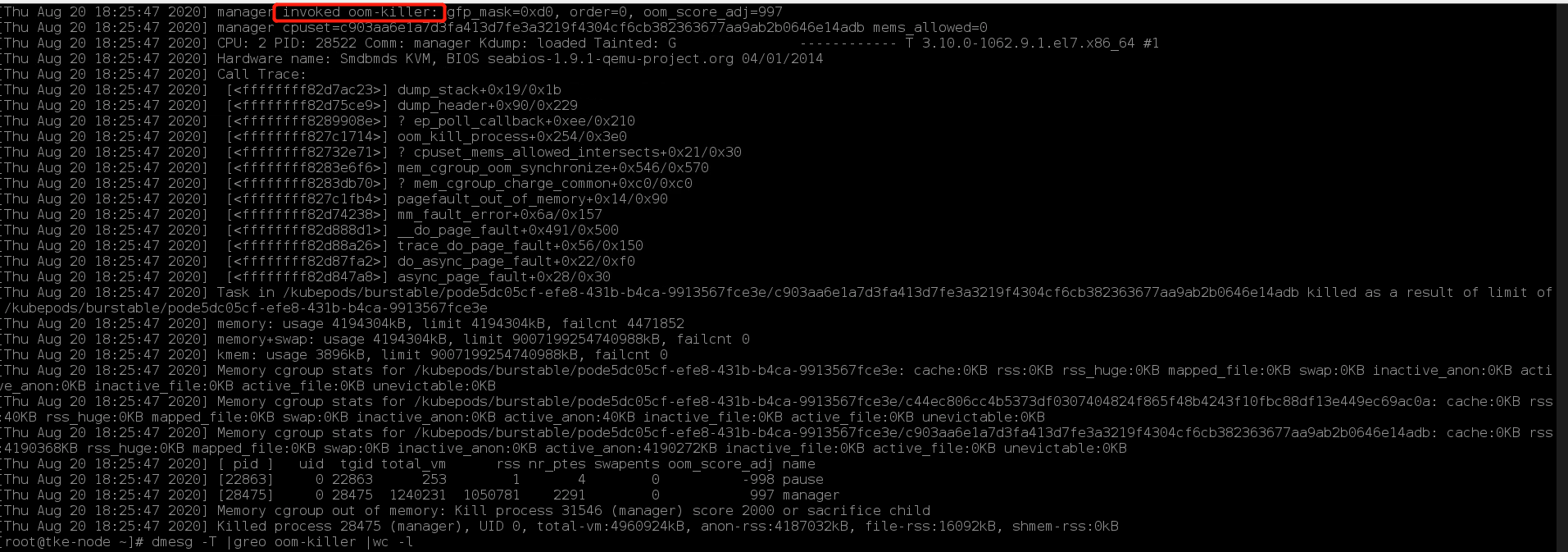
总体而言,events might not be reliable.系统发生oom时事件信息可能无法有效传递,而出现异常的环境节点,确实在dmesg日志中有大量oom的信息。
总结
- 因着急业务恢复,通过docker prune和重启故障节点docker,清理了卡住的terminating的pod。
- 按照github的对应issue描述,此问题应该容易复现,在使用docker的情况下,貌似无法避免,待调研是否可直接使用 containerd,绕过 dockerd ?在直接使用containerd时,事件信息是否也是可靠传递?

开源、云原生的融合云平台
更多推荐
 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)