JMeter实用案例讲解:生成Mockup/Dummy JSON压测REST API
JMeter实用案例:生成Mockup/Dummy JSON数据压测Restful API在实际工作中我们经常需要做一些性能测试,过去我基本上使用的都是JMeter,这么多年使用下来的一个感受是:JMeter并不太容易上手,但确实强大灵活,可以应对一些复杂的测试场景,一但掌握了,基本就不再需要其他工具了。所以这次专门写篇文章归纳总结一下。本文是一篇快速入门类的文章,将围绕最有代表性也是最常见的一类
在实际工作中我们经常需要做一些性能测试,过去我基本上使用的都是JMeter,这么多年使用下来的一个感受是:JMeter并不太容易上手,但确实强大灵活,可以应对一些复杂的测试场景,一但掌握了,基本就不再需要其他工具了。所以这次专门写篇文章归纳总结一下。本文是一篇快速入门类的文章,将围绕最有代表性也是最常见的一类场景进行介绍,即:生成Mockup/Dummy JSON数据压测Restful API,同时配合讲解我还专门开发了一个JMeter Demo工程:https://github.com/bluishglc/jmeter-demo.git,希望通过对实例的讲解能有助于大家学习和复用。
1. 压力测试有哪些常见的需求?
在开始对JMeter的讲解之前,我们先了解一下进行压力测试前需要做哪些事情:
- 准备测试数据
- 多线程并发推送数据
对于所有的压测工具来说,第2点都是内置的基本功能,没有太大差别,差别往往体现在是否能灵活便捷地生成测试数据。一般来说,生成测试数据时往往有这样一些需求:
- 为记录中的某些字段生成随机值
- 控制记录中的某些字段在一个限定的集合中取值
接下我们就进行JMeter的学习,看看它是如何实现这些需求的。
2. 案例需求与JMeter Demo工程
为了便于学习JMeter的特性,我们来虚拟一个压力测试场景:
假设现在我们有这样一个Restful API需要进行压力测试:
接口:POST /api/put
消息格式:application/json
消息样本:
[
{
"metric": "cpu.usage",
"timestamp": 1598286113000,
"value": "24",
"tags": {
"app": "app01",
"server": "server01"
}
},
{
"metric": "mem.used",
"timestamp": 1598286113000,
"value": "1234",
"tags": {
"app": "app01",
"server": "server01"
}
}
]
这是一个典型的向Restful API推送Json数据的压力测试,关于API接收的数据格式,有如下一些解释:
- 数据描述的一些服务器运行的硬件运行指标(标准叫法是metric),例如数组中的第一个JSON是cpu利用率,第二个是已用内存(熟悉OpenTSDB的同学可能已经认出来了,没错,这是OpenTSDB的数据格式)。
- 每次推送的是一个JSON数组,数组内的JSON元素格式是一样的(tags类似于一个map,内部的KV对可以是不固定的),只是字段的取值会有所不同
接下来是对需要生成的Mockup/Dummy JSON数据的重要需求:
- 在单次推送的JSON中,所有metric数据的
timestamp值是一样的,表示的是在同一个时间点采集的不同指标 - 但是在不同批次推送的JSON中,
timestamp的值是不一样的,需要在一个指定的时间区间内生成随机的时间戳 cpu.usage的value是一个0到100之间的随机值,mem.used的value是一个0到1024之间的随机值tags中的app和server既不可以完全随机,也不可以是固定的单一值,而是要按如下的取值组合生成数据:
app01,server01
app01,server02
app02,server03
app02,server04
很多时候,我们在生成数据时会通过不同的取值组合控制生成的的数据比例,从而可以测试在不同数据量下系统的性能表现,例如上面的场景,如果我们给app01再追加两台server,这样生成app01的数据量就是app02的两倍。介绍完样本数据的需求后,让我们看一下JMeter是如何实现这个测试的吧。
3. 创建测试计划
一个测试计划就是一个JMeter工程,通过菜单:“File” -> “New”即可创建,本文我们以建好的jmeter-demo项目为例讲解。首先,检出项目:git clone https://github.com/bluishglc/jmeter-demo.git,然后通过JMeter打开项目中的demo-testplan.jmx文件, 我们将会看到这样的界面:

在左侧的工程目录中,Demo Test Plan是根目录,下面包含一个Demo Thread Group。一个Test Plan通常会包含多个Test Group, 一个Test Group相当于一个可独立执行的测试用例。对于Test Group来说,最重要的三个设置项是分别是:
- Number of Threads: 启动多少个并发线程
- Loop Count:(每个线程的)执行次数
- Ramp-up Period: 当启动多个线程时,在多长时间内完成全部线程的启动
对这个三个参数作两点简要说明:
- Number of Threads * Loop Count = Total Count, 如果线程数是2,Loop Count是50, 则测试计划将总计将执行2 * 50 = 100次
- 如果线程数是5,Ramp-up Period是50秒,则平均每10秒会启动一个新线程,直到5个线程全部起来。之所以会有这个ramp-up的时间是因为启动线程是一个比较耗费资源的动作,一般不太可能一下就初始化出这么多线程,给定一个ramp-up的周期是比较好的做法。
需要提醒大家注意的是,虽然最新的JMeter对于Thread Group中各个配置项的顺序并没有要求,但是为了便于管理和维护,还是建议大家按配置项起作用的顺序进行排序,把发送请求前需要完成的配置项放在前面,例如这里的HTTP Header Manager, Random Variable以及CSV Data Set Config;把请求发送的配置项放在中间,也就是这里的HTTP Request,发送之后的结果汇总放在最后,也就是View Results in Table, View Results Tree和Summary Report。
4. 配置HTTP Header
接下来, 我们先看Thread Goup中的第一个配置项: HTTP Header Manager:

添加“HTTP Header Manager”的方法是在Thread Group上单击右键,在弹出的菜单中选择:“Add” -> “Config Element” -> “HTTP Header Manager” 。
顾名思义,这是配置HTTP请求的Header信息的,在我们这个示例中,只有一个重要的Header信息,即Content-Type: application/json;charset=UTF-8,因为我们推送的是一个JSON数据。需要特别提醒的是:通常HTTP Header的配置在一个项目中是高度统一的,所以更多时候,HTTP Header Manager会放在Test Plan下面,而不是某一个Thread Group下,以便其全局有效。
5. 设定随机变量
接下来是Tread Group中的第二个配置项:Random Variable:
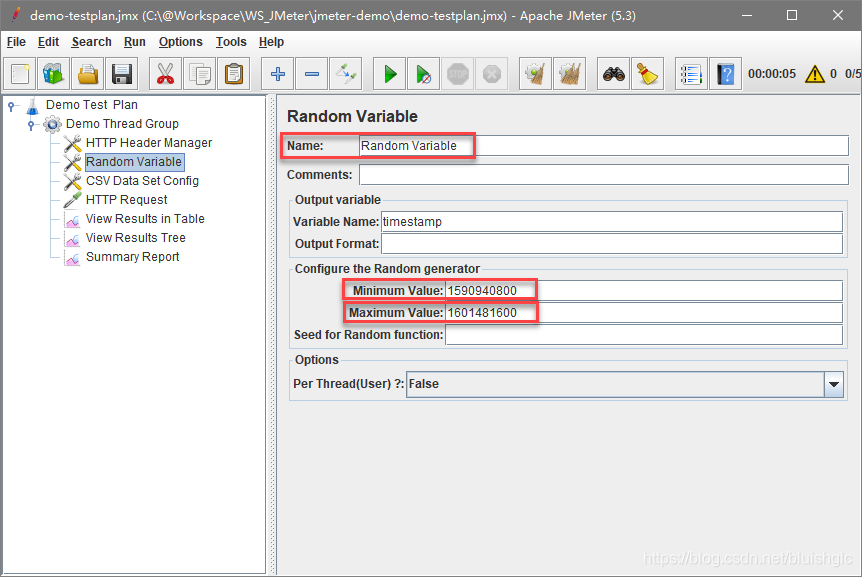
添加“Random Variable”的方法是在Thread Group上单击右键,在弹出的菜单中选择:“Add” -> “Config Element” -> “Random Variable” 。
这是用来配置随机变量的。前面我们对JSON数据提出的第2点需求:
在不同批次推送的JSON中, timestamp的值必需是不一样的,需要在一个指定的时间区间内生成随机的时间戳
这里的Random Variable设置就是应这一需求而添加的。在右侧的面板中,我们需要做如下配置:
Variable Name:timestamp
Minimum Value: 1590940800
Maximum Vlaue: 1601481600
解释一下这三项配置,变量名我们取名为timestamp,这一变量名将在后面的JSON模板中引用,使用方式是${timestamp},其值使用Unix Timestamp格式,Minimum Value是设定的最小取值,转换为日期是2020-06-01 00:00:00,Maximum Vlaue是最大值,转换为日期是2020-10-01 00:00:00,所以这个三个配置项合在一起就可以实现:生成2020-06-01 00:00:00到2020-10-01 00:00:00之间的随机时间戳。
关于随机时间戳,我们必须要留意这样一个问题:如果我们指定的时间范围较小,而生成的数据量又比较大时,一定会产生大量的重复时间戳,假如这个时间戳字段在你测试的系统中不允许重复,或者时间戳重复的记录被自动覆盖(例如OpenTSDB),而压测完成后,沉淀在数据库里的数据条数会远远小于你的压测数据量,这一点大家务必要注意。
关于Random Variable还要解释一点的是:在一次运行中只会有一个随机值,所有引用这个变量的地方在一次运行中其值是一样的,这正符合我们对timestamp时间戳的要求,因为我们需要:在单次推送的JSON中,所有metric数据的timestamp值是一样的,表示的是在同一个时间点采集的不同的metric。
如果我们想让同一批次推送的JSON中的某个多次出现的值不一样,则应该使用Random函数。在需求3中,我们要求cpu.usage的value每次都是一个0到100之间的随机值,所以value的值可以这样设定:${__Random(0,100)},我们会在后面的JSON模板中看到。
JMeter中提供了大量强大而灵活的function,可以参考其官方文档: https://jmeter.apache.org/usermanual/functions.html
6. 基于限定的取值集合生成测试数据
我们再继续往下看CSV Data Set Config:

添加“Random Variable”的方法是在Thread Group上单击右键,在弹出的菜单中选择:“Add” -> “Config Element” -> “CSV Data Set Config” 。
CSV Data Set Config是为实现需求4:
tags中的app和server既不可以完全随机,也不可以是固定的单一值,而是要按如下的取值组合生成数据:
app01,server01
app01,server02
app02,server03
app02,server04
而添加的。这是JMeter中非常强大的一项功能。简单地说,它的用处就是把测试需要的取值集合写到一个CSV文件中,每次执行时从CSV文件中读取一行数据替换请求中的相关变量。
我们看一下它的具体实现,在右侧配置中,最重要的是两项配置:
File Name:data-classifier.csv
Varaiable Names: app,server
File Name用来指定取值集合CSV文件的位置,我们建议将CSV文件放置于项目文件*.jmx的同一目录下,这样可以使用相对路径,即只指定csv文件名即可,因为CSV文件和工程文件是在同一目录下,这做的好处不管工程拷贝到什么位置,都不需要修改这里的路径。
同时,我们要给CSV提供的数据集合取一些变量名,只有有了变量名才能在后续的JSON模板中引用。CSV文件中的每一列数据都可以单独引用,所以这里的变量名相当于CSV文件的列名。我们来看一下data-classifier.csv文件就知道了:
app01,server01
app01,server02
app02,server03
app02,server04
我们给出的Varaiable Names是app,server,意思就是CSV中的第一列取名app, 第二列取名server,这样就可以在JSON模板中以${app}和${server}的形式引用CSV中的数据了,在第一次运行时,解析出的这两个变量的值分别是app01和server01,第二次运行时,解析出的值分别是app02和server02,依次类推,当第五次运行时,解析出的值又将回到app01和server01,如此一直循环下去。
7. 配置HTTP请求和JSON模板
在完成了所有的准备工作后,我们可以正式创建一个HTTP请求了。添加HTTP请求的方法是在Thread Group上单击右键,在弹出的菜单中选择:“Add” -> “Sampler” -> “HTTP Request” 。
这里我们看一下demo工程中已经创建好的这个HTTP Request:

在这个HTTP Request中有五个重要的配置项:
Server Name or IP: xxx.xxx.xxx.xxx //需要手动修改为你的API服务器的主机名或IP
HTTP Request Method: POST //需要手动修改为你的API接受的Method
HTTP Request Path: /api/put //需要手动修改为你的API接受的Path
HTTP Port: 4242 //需要手动修改为你的API服务器的端口
Boday Data: [{"metric": "cpu.usage", ....}] //需要手动修改为你的API接受的JSON格式
这些配置都与你实际测试的API密切相关,所以基本都需要手动修改一下。我们重点要关注的是Body Data里的这个JSON,它就是我们前面多次提到的JSON模板,我们前面配置的所有变量都在这个JSON模板中使用到了, 我们看一下它的具体内容:
[
{
"metric": "cpu.usage",
"timestamp": ${timestamp},
"value": ${__Random(0,100)},
"tags": {
"app": "${app}",
"server": "${server}"
}
},
{
"metric": "mem.used",
"timestamp": ${timestamp},
"value": ${__Random(0,1024)},
"tags": {
"app": "${app}",
"server": "${server}"
}
}
]
这个JSON模板与前我们前面给出的那个JSON样本的区别在于部分字段的值被一些变量和函数替代了,从而使得每次执行时生成的JSON都是变化的。我们在前面的介绍中已经介绍过了所有的这些变量和函数,这里我们再从JSON模板的视角重新梳理一下:
${timestamp}:是通过Random Variable定义的一个随机值,它的特点是在单次执行中其值是不变的,下次执行时才会改变。所以在本例中,每次生成的JSON里cpu.usage和mem.used两个metric的timestamp值是一样的。${__Random(0,100)}:是一个随机函数,可以生成0到100之间的随机值,每次执行都是不一样的值。所以在本例中,每次生成的cpu.usage和mem.used两个metric的value大概率是不一样的(有一定几率生成相同的随机值)${app}和${server}:是通过CSV Data Set Config定义的,其值分别来自于data-classifier.csv文件的第一列和第二列,每执行一次读取一行。
8. 通过命令行启动测试计划并设定并发数量和数据量
在测试计划的开发阶段,我们可以通过JMeter的GUI直接启动少量的请求来验证测试计划是否配置正确,一旦开发完成准备进行正式测试时,就不建议在GUI上执行了,而是要将整个工程拷贝到一台测试服务器上,通过命令行的方式来启动测试计划,以下是命令行方式启动jmeter-demo的参考:
nohup /your-jmeter-cli-path/jmeter.sh -n -t /your-jmeter-demo-project-path/demo-testplan.jmx -l result.jtl &
tail -f nohup.out
由于压力测试的执行时间一般都非常长,所以建议使用nohup...&的形式在后台运行,然后使用tail -f nohup.out来查看执行状态。
但是上述执行使用的并发数量和压测数据量是固化在demo-testplan.jmx工程文件中的,很多时候我们需要在执行时动态调整并发数和数据量,怎么做呢?我们可以在工程配置中将Number of Threads和Loop Count这两个配置项从固定值改为变量形式,然后在命令行中以参数形式给变量赋值。具体做法就是到Thread Group的配置页面,将Number of Threads和Loop Count配置项的值分别改为${__P(thread,)}和${__P(count,)},如下图所示:
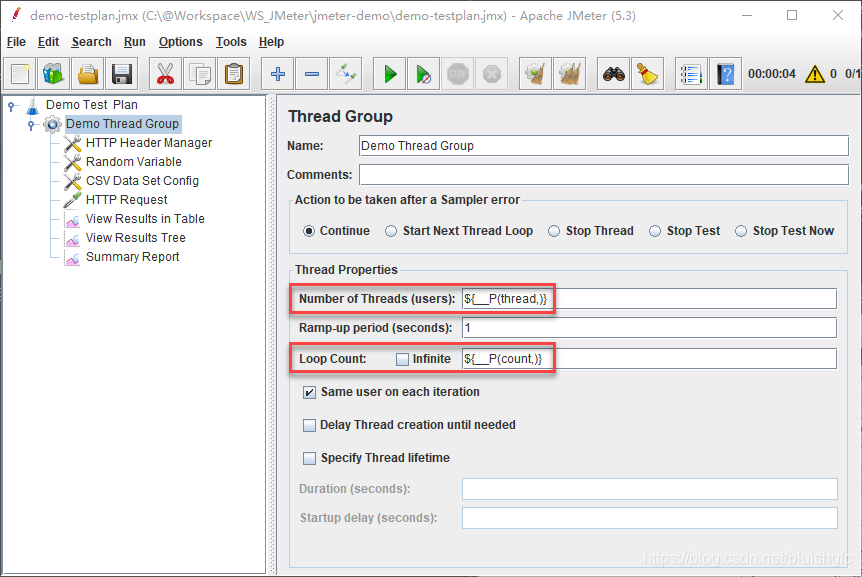
然后,通过-J变量名=变量值的形式给这两个变量赋值。此时,如果我们想让这个测试启动2个线程,每个线程插入50条数据,则命令行为:
nohup /your-jmeter-cli-path/jmeter.sh -Jthread=2 -Jcount=50 -n -t /your-jmeter-demo-project-path/demo-testplan.jmx -l result.jtl &
tail -f nohup.out
9. 查看执行结果
JMeter提供了多种多样的结果报表,可以在Thread Group上单击右键,在弹出的菜单中选择:“Add” -> “Listener”,然后选择你需要的即可,一般对于HTTP请求来说,常用的也就是我们Demo项目中配置的这些,我们简单看一下:
- View Results in Table

- View Results Tree

- Summay Report

关于作者:耿立超,架构师,14年IT系统开发和架构经验,对大数据、企业级应用架构、SaaS、分布式存储和领域驱动设计有丰富的实践经验,热衷函数式编程。目前负责企业数据中台的架构设计和开发工作,对Hadoop/Spark 生态系统有深入和广泛的了解,参与过Hadoop商业发行版的开发,曾带领团队建设过数个完备的企业数据平台,个人技术博客:https://laurence.blog.csdn.net/ 作者著有《大数据平台架构与原型实现:数据中台建设实战》一书

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)