
Hive基本原理详解
目录一、Hive概述(1)什么是Hive?(2)Hive的优点及应用场景二、Hive 和 RDBMS(关系数据库管理系统)的对比三、Hive架构(1)Hive的基本组成(2)各组件的基本功能四、Hive的工作原理一、Hive概述(1)什么是Hive?由Facebook开源用于解决海量结构化日志的数据统计Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类SQL
目录
一、Hive概述
(1)什么是Hive?
- 由Facebook开源用于解决海量结构化日志的数据统计
- Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类SQL查询功能
- 构建在Hadoop之上的数据仓库:使用HQL作为查询接口,使用HDFS存储,使用MapReduce计算
- 本质是:将HQL转化为成MapReduce程序
- 灵活性和扩展性比较好:支持UDF,自定义存储格式等
- Hive中的表是纯逻辑表,就只是表的定义等,即表的元数据。本质就是Hadoop的目录/文件,达到了元数据与数据存储分离的目的,Hive本身不存储数据,它完全依赖HDFS和MapReduce。
- Hive的内容是读多写少,不支持对数据的更新
- Hive中没有定义专门的数据格式,由用户指定,需要指定三个属性:1. 列分隔符 2. 行分隔符 3. 读取文件数据的方法
(2)Hive的优点及应用场景
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 避免了去写 MapReduce,减少开发人员的学习成本
- 统一的元数据管理,可与 impala/ spark等共享元数据
- 易扩展(HDFS+ MapReduce:可以扩展集群规模;支持自定义函数)
- 数据的离线处理;比如:日志分析,海量结构化数据离线分析
- Hive的执行延迟比较高,因此hve常用于数据分析的,对实时性要求不高的场合
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高
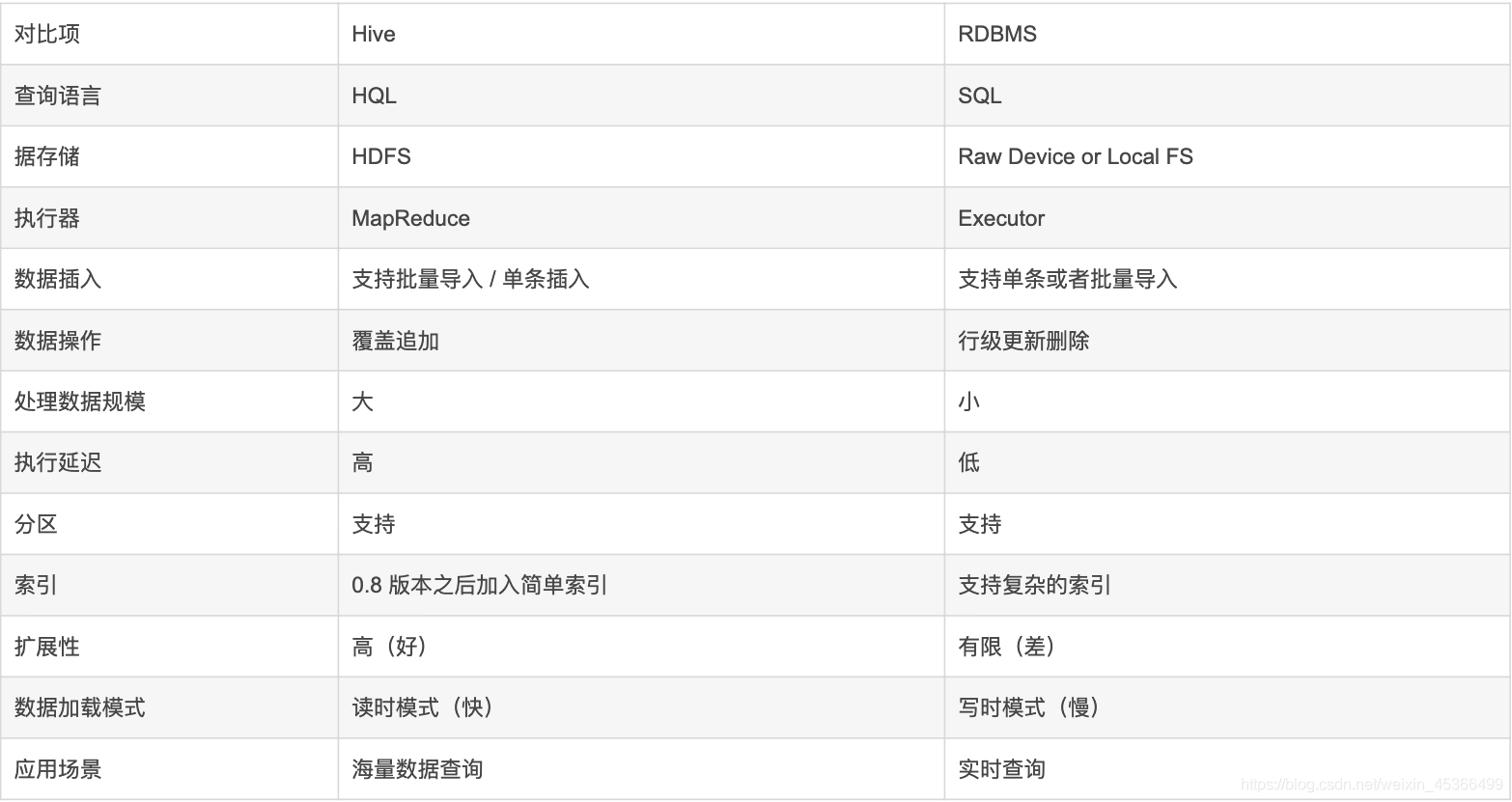
二、Hive 和 RDBMS(关系数据库管理系统)的对比
三、Hive架构
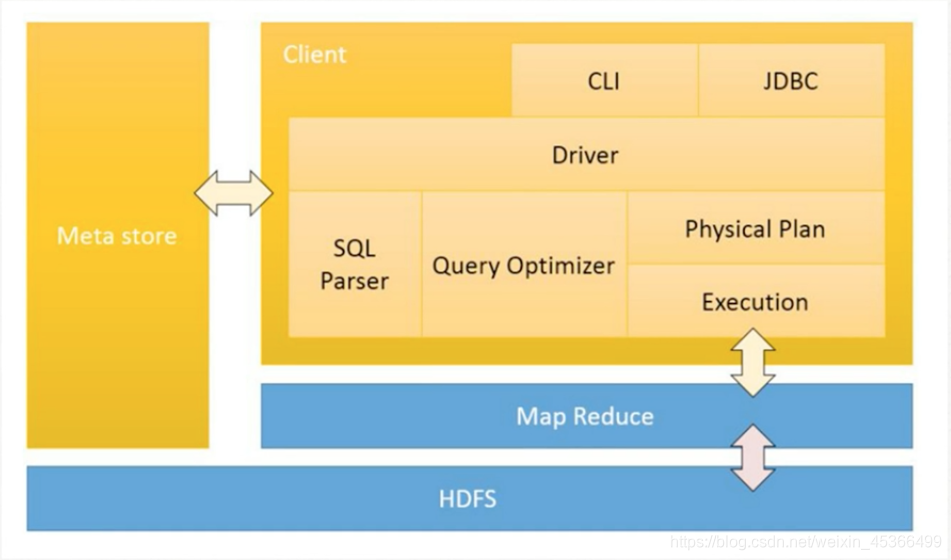
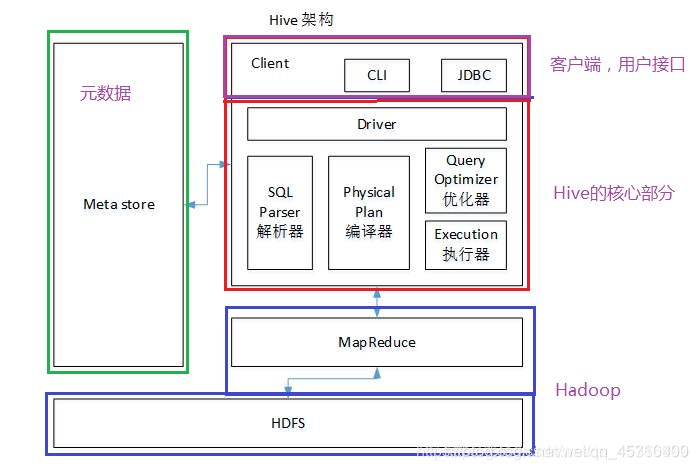
(1)Hive的基本组成
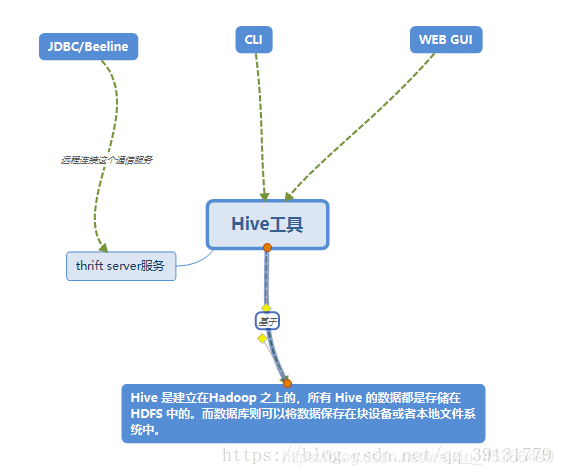
用户接口主要有三个:CLI,Client 和 WUI。
元数据存储:通常是存储在关系数据库如 mysql , derby中。
语句转换:解释器、编译器、优化器、执行器。
(2)各组件的基本功能
用户接口主要由三个:CLI、JDBC/Beeline和WebGUI。其中,CLI为shell命令行;JDBC/Beeline是Hive的JAVA实现,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。
元数据存储:Hive 将元数据存储在数据库中(MySql或者Derby)。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。表的数据所在目录Metastore 默认存在自带的 Derby 数据库中。缺点就是不适合多用户操作,并且数据存储目录不固定。数据库跟着 Hive 走,极度不方便管理。解决方案:通常存我们自己创建的 MySQL 库( 本地 或 远程)Hive 和 MySQL 之间通过 MetaStore 服务交互。
Driver : 编译器 (Compiler) ) ,优化器 (Optimizer) ) ,执行器 (Executor )
Driver 组件完成 HQL 查询语句从词法分析,语法分析,编译,优化,以及生成逻辑执行
计划的生成。生成的逻辑执行计划存储在 HDFS 中,并随后由 MapReduce 调用执行
Hive 的核心是驱动引擎, 驱动引擎由四部分组成:
(1) 解释器:解释器的作用是将 HiveSQL 语句转换为抽象语法树(AST)
(2) 编译器:编译器是将语法树编译为逻辑执行计划
(3) 优化器:优化器是对逻辑执行计划进行优化
(4) 执行器:执行器是调用底层的运行框架执行逻辑执行计划
四、Hive的工作原理
如图:
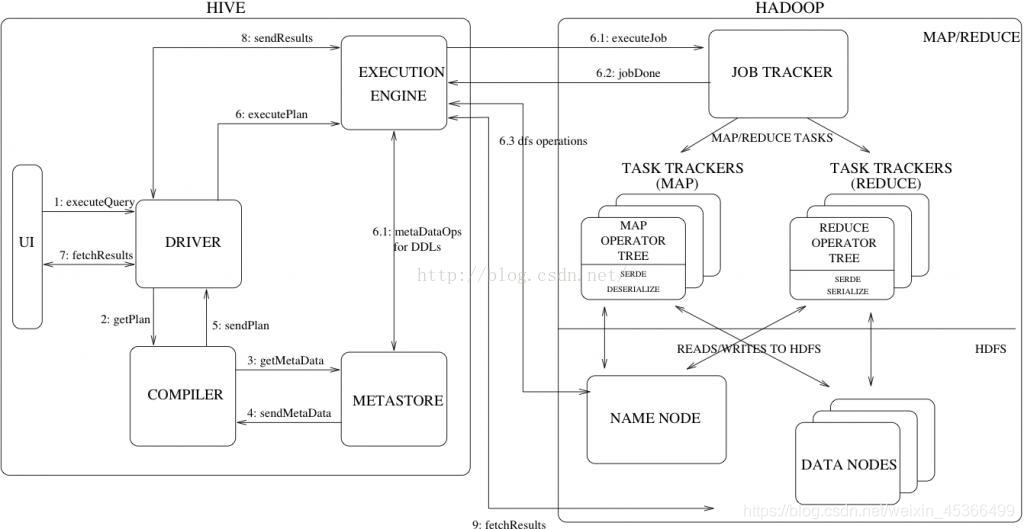
流程大致步骤为:
- 用户提交查询等任务给Driver。
- 编译器获得该用户的任务Plan。
- 编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
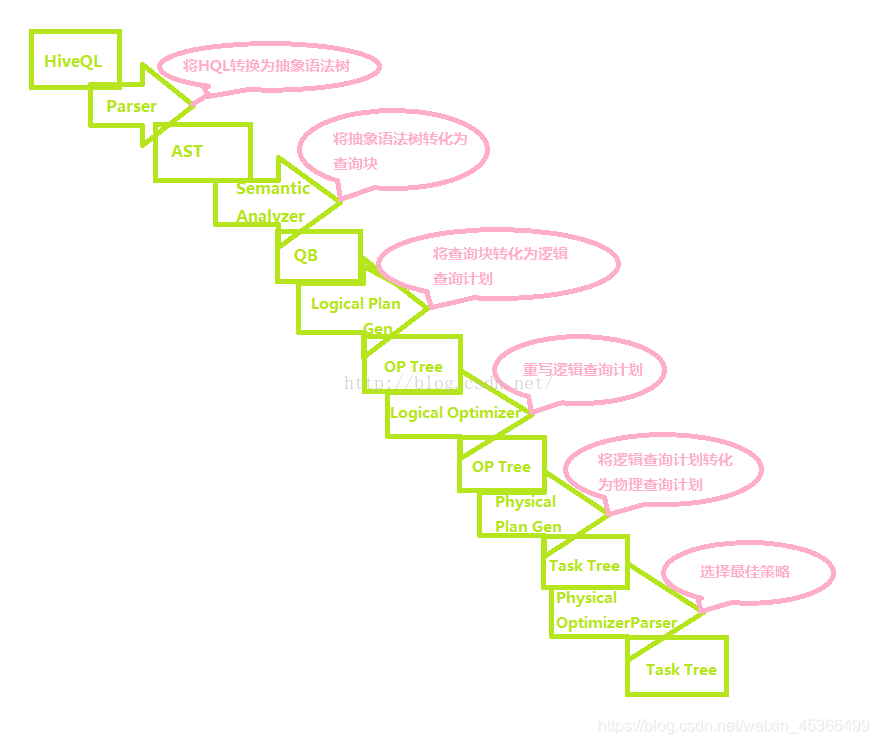
- 编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce), 最后选择最佳的策略。
- 将最终的计划提交给Driver。
- Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。
- 获取执行的结果。
- 取得并返回执行结果。
创建表时:
解析用户提交的Hive语句–>对其进行解析–>分解为表、字段、分区等Hive对象。根据解析到的信息构建对应的表、字段、分区等对象,从SEQUENCE_TABLE中获取构建对象的最新的ID,与构建对象信息(名称、类型等等)一同通过DAO方法写入元数据库的表中,成功后将SEQUENCE_TABLE中对应的最新ID+5.实际上常见的RDBMS都是通过这种方法进行组织的,其系统表中和Hive元数据一样显示了这些ID信息。通过这些元数据可以很容易的读取到数据。
Hive编译过程
基本流程为:将HiveQL转化为抽象语法树再转为查询块然后转为逻辑查询计划再转为物理查询计划最终选择最佳决策的过程。
优化器的主要功能:
- 将多Multiple join 合并为一个Muti-way join
- 对join、group-by和自定义的MapReduce操作重新进行划分。
- 消减不必要的列。
- 在表的扫描操作中推行使用断言。
- 对于已分区的表,消减不必要的分区。
- 在抽样查询中,消减不必要的桶。
- 优化器还增加了局部聚合操作用于处理大分组聚合和增加再分区操作用于处理不对称的分组聚合。
参考文章:
- https://blog.csdn.net/qq_36864672/article/details/78648248
- https://blog.csdn.net/zyz_home/article/details/79879617
- https://blog.csdn.net/qq_39131779/article/details/83384058
以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!

快速构建 Web 应用程序
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)