使用requests和 xpath模块爬取网页内容
1.使用requests和 xpath模块爬取网页内容1.from fake_useragent import UserAgent动态设置消息头使用下面模块 爬取网页内容网页解析使用xpathxpath 语法 最简单使用谷歌浏览器 定位标签 copy xpath#!/usr/bin/env python#-*- coding:utf-8 -*-"""@author: zhengxianjun@co
·
1.使用requests和 xpath模块爬取网页内容
1.from fake_useragent import UserAgent
动态设置消息头
使用下面模块 爬取网页内容
网页解析使用xpath
xpath 语法 最简单使用谷歌浏览器 定位标签 copy xpath
#!/usr/bin/env python
#-*- coding:utf-8 -*-
"""
@author: zhengxianjun
@contact: 1596492090@qq.com
@datetime:2020/6/5 22:25
@software: PyCharm
"""
if __name__ == '__main__':
"""
使用下面模块 爬取网页内容
网页解析使用xpath
xpath 语法 最简单使用谷歌浏览器 定位标签 copy xpath
"""
import requests
import re
from lxml import etree
from fake_useragent import UserAgent
# 消息头 随机选取
headers = {
'User-Agent': UserAgent().random
}
url = ''
# 1.连接请求 解析HTML
resp = requests.get(url=url, headers=headers).content.decode('utf8')
html = etree.HTML(resp)
# 11.如果是Ajax请求 直接解析json数据 这个比较好处理
# resp = requests.get(url=url, headers=headers)
# json = resp.content
element = html.xpath('//*[@id="full-view-identifiers"]/li[3]/span/a') ## 返回一个元素列表
result_txt = '' if not element else str(element[0].text).strip() ##获取 标签里的 文本信息
# //text() xpath 后面加这个 表示 获该标签下的所有文本信息
data = {}
authors_list_xpath = '//*[@id="full-view-heading"]/div[2]/div/div//text()'
element_authors = html.xpath(authors_list_xpath) ## 返回一个元素列表
authors = ''
for a in element_authors:
authors = authors + a.strip()
authors = re.sub('[1-9]', '', authors) ##用正则表达式解析文本信息
data['authors'] = authors
#以上可以应付简单的日常开发工作了
#又是搬砖的一天。。。
按F12进入开发者界面 copy xpath !!!! 注意 有两个可选 一个是全部的 另一个是相对的 都试试看能不能解析 ,这里今天汤坑了
copy xpath !!!! 注意 有两个可选 一个是全部的 另一个是相对的 都试试看能不能解析 ,这里今天汤坑了
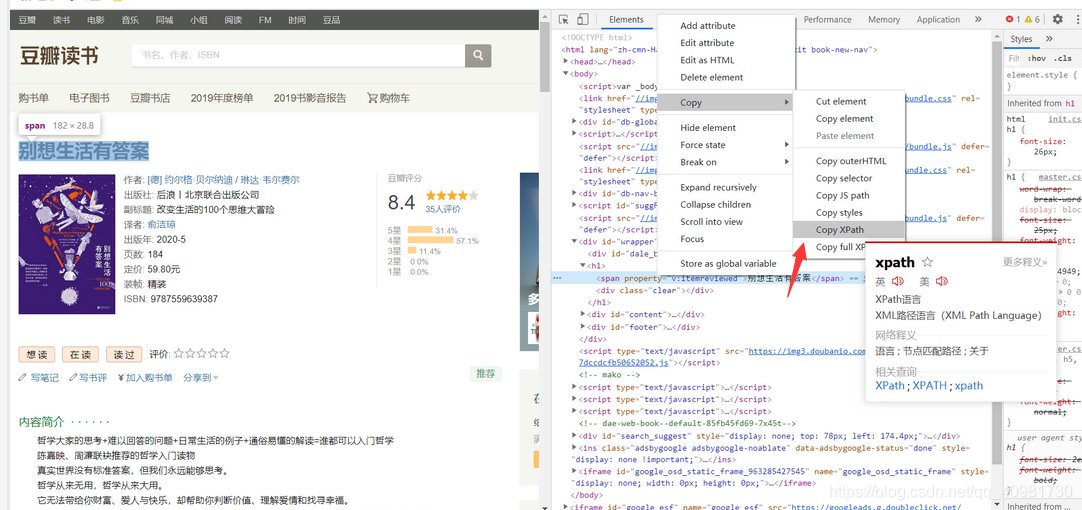
然后就大功告成,不用学太多内容,就算不会xpath也可以轻松搞定任务。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)