“西游记之大圣归来”短评主题分析-Latent Dirichlet Allocation
功能:1.输出影评主题 2.输出每份评论在各个主题上的权重分布工具:python2 spark2.0.2etl#!/usr/bin/python# -*- coding: utf-8 -*-"""@author:@contact:@time:"""from __future__ import print_functionfrom pyspark.sql import SparkSessionimp
·
功能
- 输出影评主题;
- 输出每份评论在各个主题上的权重分布。
工具
- python2 spark2.0.2
引言
- 在机器学习中,LDA是两个常用模型的简称:线性判别分析(Linear Discriminant Analysis)和隐含狄利克雷分布(Latent Dirichlet allocation),本篇指的是后者。具体来说,LDA可以解决这样的问题:如我现在有一批针对“大圣归来”评论的文本,我想知道大家都在说些什么,以及每个人在说些什么。
- spark里LDA函数的输入是文本向量化的结果,LDA有两个输出:
- 每个主题的主题词、每个主题词对此主题的贡献程度(权重)①;
- 每篇文本在各个主题上的权重分布 ②。
- 那么LDA是如何由文本得到主题词及每篇文档的主题分布呢,我们令这批文本一共有3个主题,每个主题用6个词表示,即每个主题都是6个主题词。是这样:
- 随机初始化:,首先对当前所有文档中的所有词都随机赋予一个主题号(0,1,2),然后统计每个主题下出现每个词的数量(按照数量从大到小排序,排在前6位的即为该主题下的主题词)以及每个文档下出现各个主题的数量(这就是前面说到的②);
- 迭代:按照Gibbs采样规则,对每个词重新赋予主题号,统计主题下出现的词数量及每个文档下出现的主题数量;
- 不停的迭代,直到统计的数量不变或者变化较小,停止迭代。
- Spark包含rdd和dataframe两个接口(机器学习包对应mllib和ml),本文采用的是dataframe接口。
数据集
- 两个字段(评论人,评论内容),480条短评;
最优调参效果
- 迭代次数: maxIter=65
- 主题数: k=6
- 优化方法:online
- Alpha:设为默认值
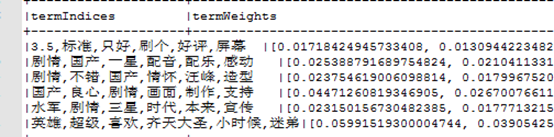
调参过程
- online,确定迭代次数
- 优化方法为online下,画出评价指标(logLikelihood,logPerplexity)和迭代次数的二维图,其中log likelihood,越大越好,Perplexity评估,越小越好;由下图可知,最优迭代次数大概在60到70之间,我们这里令最优迭代次数为65。

- 优化方法为online下,画出评价指标(logLikelihood,logPerplexity)和迭代次数的二维图,其中log likelihood,越大越好,Perplexity评估,越小越好;由下图可知,最优迭代次数大概在60到70之间,我们这里令最优迭代次数为65。
- online,迭代次数为65,确定主题数
- 优化方法为online,迭代次数为65的前提下,将主题数目从2设到9,主观观察结果,发现主题数目太少信息提取不全,太多主题分散,主观观察后最终定为6个主题。

- 优化方法为online,迭代次数为65的前提下,将主题数目从2设到9,主观观察结果,发现主题数目太少信息提取不全,太多主题分散,主观观察后最终定为6个主题。
- 主题数为6,online,迭代65次,alpha设为默认值,即0.16
- 这也是上面提到的最优的调参效果。
- 主题数为6,online,迭代65次,alpha设为2
- 使用online的过程中,出现了主题非常集中,各个文档对应的主题分布也不鲜明,原因是alpha>1,alpha值设错了,如下所示:

- 使用online的过程中,出现了主题非常集中,各个文档对应的主题分布也不鲜明,原因是alpha>1,alpha值设错了,如下所示:
- EM,迭代65次,主题数为6,确定alpha值
- 这里没有测试针对EM的最优迭代次数,设为65,主题数设为6,在这种情况下,alpha设置方式要参考以下三点:
- alpha必须>1.0,一般设置为:(50/k)+1,k为主题数;
- 评价指标(ogLikelihood,logPerplexity)和alpha的关系图选择合适的aplha值;
- 如果alpha设置的过大,各个文档对应的主题分布就不鲜明,此时要调小alpha
- 画出评价指标(logLikelihood,logPerplexity)和alpha的二维图,参考下图,alpha可取13,参考公式,alpha可取9.3,然而经测试,alpha=13,9.3,7,5.5时,文档的主题分布均不鲜明;当alpha取1.1时,有稍微明显的主题分布,不过也有可能是迭代次数设置的不对。

- 这里没有测试针对EM的最优迭代次数,设为65,主题数设为6,在这种情况下,alpha设置方式要参考以下三点:
调参规则总结
- 迭代次数: 结合logLikelihood、logPerplexity确定
- 主题数: 太少信息提取不全,太多信息分散,多试几次
- 优化方法: online、EM
- Alpha
- online: alpha取默认值即可(1.0/k),取值要小于1小于等于0
- 注意:如果使用online的过程中,出现了主题非常集中,各个文档对应的主题分布也不鲜明,原因是alpha>1。
- EM: alpha必须>1.0;默认为:(50/k)+1;根据评价指标(logLikelihood,logPerplexity)和alpha的关系图选择
- 注意:如果各个文档对应的主题分布不鲜明,此时要调小alpha值。
- online: alpha取默认值即可(1.0/k),取值要小于1小于等于0
pyspark脚本
- etl
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
@author:
@contact:
@time:
"""
from __future__ import print_function
from pyspark.sql import SparkSession
import os,ConfigParser,sys
reload(sys)
sys.setdefaultencoding("utf-8")
#读取配置文件
def configfileParameter(b):
pwd = sys.path[0]
path = os.path.abspath(os.path.join(pwd, os.pardir, os.pardir))
os.chdir(path)
cf = ConfigParser.ConfigParser()
cf.read("/con/configfile.conf")
SPARK_HOME = cf.get("SPARK_HOME", "SPARK_HOME")
return SPARK_HOME
#读取停用词
os.environ['SPARK_HOME'] ="/lib/spark"
spark = SparkSession.builder.appName("etl").getOrCreate()
sc = spark.sparkContext
stopwords = sc.textFile("hdfs://stopwords.txt").collect()
#去停用词、单字、数字
def stopword(strArr):
stop_strArr = []
for i in strArr:
if len(i)> 1:
if i.isdigit()!=True:
if i not in stopwords:
stop_strArr.append(i)
return stop_strArr
- lda
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
@author:
@contact:
@file:
@time:
"""
from __future__ import print_function
from pyspark.sql import functions as F
import sys,os,time,jieba,assistFuntion
reload(sys)
sys.setdefaultencoding("utf-8")
from pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.ml.clustering import LDA
from pyspark.ml.feature import CountVectorizer,IDF
from pyspark.sql.functions import split, explode
from pyspark.sql.window import Window, WindowSpec
#输出开始时间
print("运行开始时间:" + str(time.localtime(time.time()).tm_hour) + ":" + str(time.localtime(time.time()).tm_min) + "")
#读取配置文件
SPARK_HOME=assistFuntion.configfileParameter(1)
os.environ['SPARK_HOME'] = SPARK_HOME
spark = SparkSession.builder.appName("lda_test").getOrCreate()
sc = spark.sparkContext
#读取本地数据
lines = sc.textFile("hdfs://data.txt")
parts = lines.map(lambda l: l.split(" "))
textRdd = parts.map(lambda p: Row(da=p[0], text=p[1]))
textDf = spark.createDataFrame(textRdd)
textDf.createOrReplaceTempView("textDf")
#数据预处理
#如果time_CALLING_CALLED不是唯一的,做一遍合并操作
sqlDF = spark.sql("select a,concat_ws(' ', collect_set(text)) as text_group from textDf group by a")
sqlDF.cache()
#print("预处理后的数据量:" + str(sqlDF.count()) + "")
# 自定义分词词典
fenciDict = sc.textFile("hdfs://fenciDict.txt").collect()
for line in fenciDict:
jieba.add_word(line)
#分词、去停用词、单字、数字
rdd= sqlDF.rdd.map(lambda x: (x.a, x.text_group)).map(lambda x: Row(a=x[0], text=",".join(jieba.cut(x[1]))))
rdd=rdd.map(lambda x: Row(a=x[1], text=x[0].split(",")))
preDf = rdd.map(lambda x: Row(a=x[1], text=etl.stopword(x[0]))).toDF()
preDf.cache()
#print("分词、去停用词、单字、数字后的数据量:" + str(preDf.count()) + "")
# 文本向量化[tfidf]
cv = CountVectorizer(inputCol="text", outputCol="rawFeatures",vocabSize=2000)
cvModel = cv.fit(preDf)
cvResult = cvModel.transform(preDf)
idf = IDF(inputCol="rawFeatures", outputCol="features")
idfModel = idf.fit(cvResult)
tfidfResult = idfModel.transform(cvResult)
tfidfResult.cache()
#构造索引和词的对应字典
voc = cvModel.vocabulary
L = range(0, 2000)
nvs = zip(L, voc)
nvDict = dict((id, word) for id, word in nvs)
def Index_toword(i):
word = nvDict[i]
return word
def intarr_index(intArr):
StrArr = []
for i in intArr:
StrArr.append(Index_toword(i))
return StrArr
def intArr2StrArr(intArr):
StrArr = []
for i in intArr:
StrArr.append(str(round(i, 4)))
return StrArr
#主题模型Lda
lda = LDA(k=4, maxIter=80)
model = lda.fit(tfidfResult.select("a", "features"))
# 输出主题词,主题词对应的权重分布
topics = model.describeTopics(6)
dfTopics = topics.rdd.map(lambda x: Row(topicId=x[0], termIndices=",".join(intarr_index(x[1])),termWeights=x[2])).toDF()
dfTopics=dfTopics.select(dfTopics['termIndices'], dfTopics['topicId'] + 1)
print("输出主题词,主题词对应的权重分布")
dfTopics.show(truncate=False)
#输出每个文本在各个主题上的权重分布
transformed = model.transform(tfidfResult.select("a", "features"))
transformedrdd = transformed.rdd.map(lambda x: Row(a=x[0], topicDistribution=",".join(intArr2StrArr(x[2]))))
transformed = spark.createDataFrame(transformedrdd)
transformed_split=transformed.withColumn('topicDistribution', explode(split('topicDistribution', ',')))
transformed_split.cache()
transformed_split = transformed_split.select("a","topicDistribution", F.row_number().over(Window.partitionBy("a").orderBy("a")).alias("(topicId + 1)"))
transformed_split.cache()
#只保留最大概率
w = Window.partitionBy('a')
DF=transformed_split.withColumn('maxtopicDistribution', F.max('topicDistribution').over(w))\
.where(F.col('topicDistribution') == F.col('maxtopicDistribution'))\
.drop('maxtopicDistribution')
DF.cache()
#DF.show(10000,truncate=False)
print("统计每个类别下的文本条数")
DF.groupBy("(topicId + 1)" ).count().show()
#得到表:termIndices a text_group
tagDf = sqlDF.join(DF,"a", "inner").select("(topicId + 1)",sqlDF.a,"text_group")
tagFinalDf = tagDf.join(dfTopics,"(topicId + 1)", "inner").select("termIndices","a","text_group")
tagFinalDf.show(100,truncate=False)
'''
迭代次数
根据评价指标:logLikelihood,logPerplexity判断迭代次数
log likelihood,越大越好;
Perplexity评估,越小越好;
'''
# wr_max = open("/test_lda/maxIter105.txt", "w")
# # for i in range(0,90,5):
# for i in range(105, 150, 5):
# lda = LDA(k=8, maxIter=i)
# model = lda.fit(result.select("a3", "features"))
# ll = model.logLikelihood(result.select("a3", "features"))
# lp = model.logPerplexity(result.select("a3", "features"))
# wr_max.write("ll:" + str(i) + "\t" + str(ll))
# wr_max.write("\n")
# wr_max.write("lp:" + str(i) + "\t" + str(lp))
# wr_max.write("\n")
# wr_max.close()
'''
主题数目
迭代次数设为65的前提下查看合适的主题个数;
主题数目,太少信息提取不全,太多主题分散;
'''
# for i in range(3,10,1):
# lda = LDA(k=i, maxIter=90)
# model = lda.fit(result.select("a3", "features"))
# topics = model.describeTopics(6)
# transformed = model.transform(result.select("a3", "features"))
# # transformed.show(truncate=False)
# df = topics.rdd.map(lambda x: Row(topicId=x[0], termIndices=",".join(intarr_index(x[1])),termWeights=x[2])).toDF()
# df.show(truncate=False)
spark.stop()
#输出结束时间
print("运行结束时间:" + str(time.localtime(time.time()).tm_hour) + ":" + str(time.localtime(time.time()).tm_min) + "")
- 运行
spark-submit --master yarn --jars etl.py --executor-memory 20G --total-executor-cores 12 ldaTest.py >>/test_lda_$(date +\%Y\%m\%d).log 2>&1 &

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)