
SVM做文本分类代码实现详解
之前的一篇博文 SVM做文本分类详细操作流程 由于是很早之前写的,大部分都是调用脚本,代码也不是很全,这里我再对之前的博文进行一个详细的补充。代码详见 GitHub 。首先需要导入必要的包:import jiebaimport numpy as npimport pandas as pd然后我们把天气相关的语料称为正语料,其他类别的语料称为负语料,接着我们读取这两个类别的语料:pos = pd.r
之前的一篇博文 SVM做文本分类详细操作流程 由于是很早之前写的,大部分都是调用脚本,代码也不是很全,这里我再对之前的博文进行一个详细的补充。代码详见 GitHub 。
首先需要导入必要的包:
import jieba
import numpy as np
import pandas as pd
然后我们把天气相关的语料称为正语料,其他类别的语料称为负语料,接着我们读取这两个类别的语料:
pos = pd.read_csv('../Desktop/weather_pos.txt', encoding='UTF-8', header=None)
neg = pd.read_csv('../Desktop/weather_neg.txt', encoding='UTF-8', header=None)
我们可以看看正负类的语料长什么样子:

这里的正语料有6565条,负语料有22513条。接着我们用jieba对每一条语料进行分词处理:
pos['words'] = pos[0].apply(lambda x: jieba.lcut(x))
neg['words'] = neg[0].apply(lambda x: jieba.lcut(x))
分词的结果如下所示:


接着我们将正负语料进行合并成训练语料然后并打上标签,正语料打上标签1,负语料打上标签0:
x = np.concatenate((pos['words'], neg['words']))
y = np.concatenate((np.ones(len(pos)),np.zeros(len(neg))))
做好了准备工作之后,我们就可以开始训练词向量了,具体训练方法可以参考我的博文 如何训练一个词向量 。直接上代码:
from gensim.models.word2vec import Word2Vec
word2vec = Word2Vec(x, size=300, window=3, min_count=5, sg=1, hs=1, iter=10, workers=25)
word2vec.save('../Desktop/word2vec.model')
我们将训练好的词向量储存下来,接着我们可以试一下:
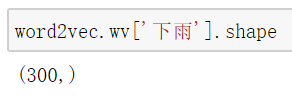
我们可以看到 ‘下雨’ 这个词是一个300维的词向量,接下来我们如何获取整句话的词向量呢?我们知道词向量的叠加同时也会将语义进行叠加,这里我们将每句话中的所有词进行词向量的相加,我们就可以定义词向量相加的方法:
def total_vector(words):
vec = np.zeros(300).reshape((1, 300))
for word in words:
try:
vec += word2vec.wv[word].reshape((1, 300))
except KeyError:
continue
return vec
接下来我们可以得到训练集:
train_vec = np.concatenate([total_vector(words) for words in x])
叠加之后就可以得到一条条的词向量了:

接下来我们可以开始训练分类模型了:
from sklearn.externals import joblib
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
model = SVC(kernel='rbf', verbose=True)
model.fit(train_vec, y)
joblib.dump(model, '../Desktop/weather_svm.pkl')
我们训练好SVM模型之后便可以将模型储存下来,接着我们可以验证一下模型的效果,这里我们需要定义一个预测的方法,将输入的query进行分词向量化操作:
def svm_predict(query):
words = jieba.lcut(str(query))
words_vec = total_vector(words)
result = model.predict(words_vec)
if int(result) == 1:
print('类别:天气')
elif int(result) == 0:
print('类别:其他')
然后我们就可以进行验证了:

随便测了几个,效果还是阔以的,好了,代码很好理解,希望对大家在词向量和文本分类的理解上有所帮助,文中如有纰漏,也请大家不吝指教,如有转载,请注明出处,谢谢。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)