
Elasticsearch(ES)生产集群健康状况为黄色(yellow)的官方详细解释、原因分析和解决方案(实测可用)
文章目录介绍elasticsearch健康装填查询接口`/_cluster/health`接口反馈内容解释如下:处理方案步骤一、找到elasticsearch集群异常的索引步骤二、查看es集群健康信息,以及黄色状态索引的settings信息进行分析步骤三、分析并解决问题介绍 Elasticsearch(ES)集群状态显示黄色时,使用cerebro会提示显示黄色原因,如果使用其他工具,则可以通过健
文章目录
介绍
Elasticsearch(ES)集群状态显示黄色时,使用cerebro会提示显示黄色原因,如果使用其他工具,则可以通过健康检查api查看集群状态GET /_cluster/health。
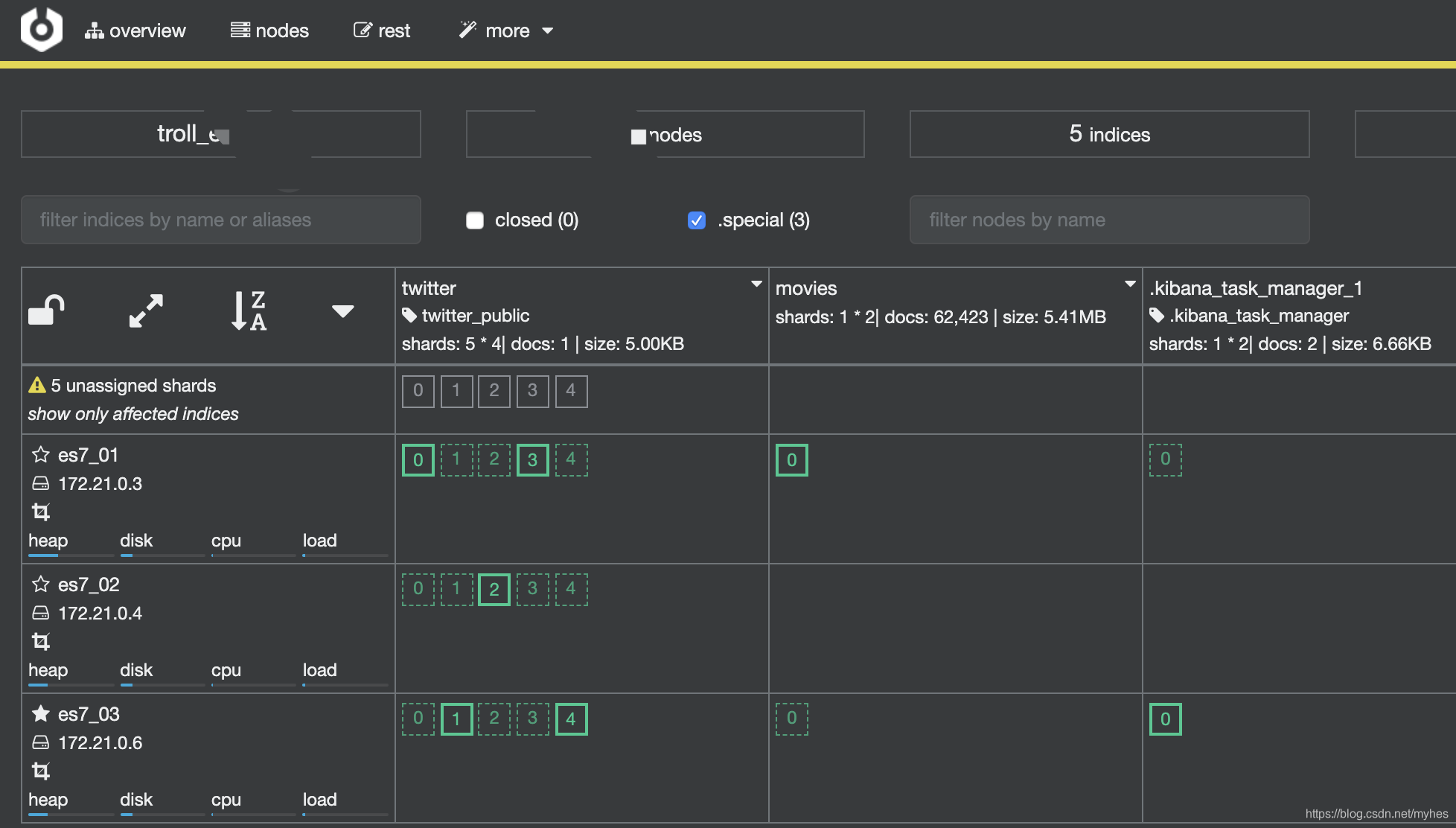
调用健康检查apiGET /_cluster/health反馈如下信息:
{
"cluster_name" : "troll*",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : ***,
"number_of_data_nodes" : ***,
"active_primary_shards" : ***,
"active_shards" : ***,
"relocating_shards" : ***,
"initializing_shards" : ***,
"unassigned_shards" : ***, // ~注意看这里~
"delayed_unassigned_shards" : ***,
"number_of_pending_tasks" : ***,
"number_of_in_flight_fetch" : ***,
"task_max_waiting_in_queue_millis" : ***,
"active_shards_percent_as_number" : ***
}
elasticsearch健康装填查询接口/_cluster/health接口反馈内容解释如下:
- 响应正文
- cluster_name
(字符串)集群的名称。 - status
(字符串)集群的运行状况,基于其主要和副本分片的状态。状态为:
– green
所有分片均已分配。
– yellow
所有主分片均已分配,但未分配一个或多个副本分片。如果群集中的某个节点发生故障,则在修复该节点之前,某些数据可能不可用。
– red
未分配一个或多个主分片,因此某些数据不可用。在集群启动期间,这可能会短暂发生,因为已分配了主要分片。 - timed_out
(布尔值)如果false响应在timeout参数指定的时间段内返回(30s默认情况下)。 - number_of_nodes
(整数)集群中的节点数。 - number_of_data_nodes
(整数)作为专用数据节点的节点数。 - active_primary_shards
(整数)活动主分区的数量。 - active_shards
(整数)活动主分区和副本分区的总数。 - relocating_shards
(整数)正在重定位的分片的数量。 - initializing_shards
(整数)正在初始化的分片数。 - unassigned_shards
(整数)未分配的分片数。 - delayed_unassigned_shards
(整数)其分配因超时设置而延迟的分片数。 - number_of_pending_tasks
(整数)尚未执行的集群级别更改的数量。 - number_of_in_flight_fetch
(整数)未完成的访存数量。 - task_max_waiting_in_queue_millis
(整数)自最早的初始化任务等待执行以来的时间(以毫秒为单位)。 - active_shards_percent_as_number
(浮动)群集中活动碎片的比率,以百分比表示。
问题分析
查看集群状态
# 查看集群健康状态
GET /_cluster/health
查看集群分片的情况,重点关注unassigned_shards没有正常分配的副本数量。
{
“cluster_name” : “*******”,
“status” : “yellow”,
“timed_out” : false,
“number_of_nodes” : *******,
“number_of_data_nodes” : *******,
“active_primary_shards” : *******,
“active_shards” : *******,
“relocating_shards” : *******,
“initializing_shards” : *******,
“unassigned_shards” : *******,
“delayed_unassigned_shards” : *******,
“number_of_pending_tasks” : *******,
“number_of_in_flight_fetch” : *******,
“task_max_waiting_in_queue_millis” : *******,
“active_shards_percent_as_number” : *******
}
找到问题索引
# 查看索引情况
GET _cat/indices
根据返回值找到异常索引
yello open 索引名 ***** ***** ***** ***** ***** ***** *****
查看详细的异常信息
# 查看异常原因
GET /_cluster/allocation/explain
查看分片异常的原因,这里提示异常原因为:unassigned、node_left、the shard cannot be allocated to the same node on which a copy of the shard already exists和cannot allocate because allocation is not permitted to any of the nodes,此处是由于节点丢失导致无法进行副本复制导致。
{
“index” : “",
“shard” : "”,
“primary” : “",
“current_state” : “unassigned”,
“unassigned_info” : {
“reason” : “NODE_LEFT”,
“at” : “2020-05-15T06:12:23.967Z”,
“details” : “node_left [KyZROB7BSASwY0i3r7q3nw]”,
“last_allocation_status” : “no_attempt”
},
“can_allocate” : “no”,
“allocate_explanation” : “cannot allocate because allocation is not permitted to any of the nodes”,
“node_allocation_decisions” : [
{
“node_id” : “FkwTKuMISlG88uNtelHQbQ”,
“node_name” : “es7_01”,
“transport_address” : “172.21.0.6:9300”,
“node_attributes” : {
“ml.machine_memory” : “12566077440”,
“ml.max_open_jobs” : “20”,
“xpack.installed” : “true”
},
“node_decision” : “no”,
“deciders” : [
{
“decider” : “same_shard”,
“decision” : “NO”,
“explanation” : "the shard cannot be allocated to the same node on which a copy of the shard already exists [[]][0], node[FkwTKuMISlG88uNtelHQbQ], [P], s[STARTED], a[id=l_k948LiTcSqjhp8PRKqVQ]]”
}
]
},
{
“node_id” : “mjNvBmkASwq0Dx6W5028Uw”,
“node_name” : “es7_03”,
“transport_address” : “172.21.。:9300”,
“node_attributes” : {
“ml.machine_memory” : “12566077440”,
“ml.max_open_jobs” : “20”,
“xpack.installed” : “true”
},
“node_decision” : “no”,
“deciders” : [
{
“decider” : “same_shard”,
“decision” : “NO”,
“explanation” : “the shard cannot be allocated to the same node on which a copy of the shard already exists [[******]][0], node[mjNvBmkASwq0Dx6W5028Uw], [R], s[STARTED], a[id=lS8fqbDoRA-ju6QW5psnjA]]”
}
]
}
]
}
处理方案
步骤一、找到elasticsearch集群异常的索引
# 查看索引信息,找出异常索引
GET /_cat/indices\?v
返回:
# health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
# green open ** D90ToWRGTpyeJAIy2ZVCvw *** *** *** *** *** ***
# yellow open ** hXI3lFOlSVi6gnqREZzEwQ *** *** *** *** *** ***
# green open .kibana_task_manager_1 akJZg3QkRta-oGH8BEfhXA *** *** *** *** *** ***
# green open .apm-agent-configuration f5ftL0VISRm36KXnN3QtPQ *** *** *** *** *** ***
# green open .kibana_1 d5k_3pOkRSe95Cf-dMo0SQ *** *** *** *** *** ***
从以上信息中可以看出第二行的索引存在异常,为黄色(yellow),elasticsearch健康状态为黄色则代表所有主分片均已分配,但未分配一个或多个副本分片。如果群集中的某个节点发生故障,则在修复该节点之前,某些数据可能不可用。则将副本集大小进行重新设置即可。
步骤二、查看es集群健康信息,以及黄色状态索引的settings信息进行分析
查看es集群的健康状态GET /_cluster/health
返回信息如下:
{
"cluster_name" : "troll*",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : ***,
"number_of_data_nodes" : ***,
"active_primary_shards" : ***,
"active_shards" : ***,
"relocating_shards" : ***,
"initializing_shards" : ***,
"unassigned_shards" : ***, // ~注意看这里~
"delayed_unassigned_shards" : ***,
"number_of_pending_tasks" : ***,
"number_of_in_flight_fetch" : ***,
"task_max_waiting_in_queue_millis" : ***,
"active_shards_percent_as_number" : ***
}
对照返回值官方文档解释(如上介绍中),发现存在部分副本分片为正常分配的情况。
查看es集群黄色状态索引的settings
# 查看索引设置
GET /***/_settings
反馈信息如下:
{
"***" : {
"settings" : {
"index" : {
"creation_date" : "***",
"number_of_shards" : "***",
"number_of_replicas" : "***", // 关注此处的副本分片的大小
"uuid" : "hXI3lFOlSVi6gnqREZzEwQ",
"version" : {
"created" : "***"
},
"provided_name" : "***"
}
}
}
}
步骤三、分析并解决问题
此处假设number_of_replicas的数量为3,则说明3个分片未分配。我们需要根据不同的情况进行分析:
- 存在数个节点宕机或者误操作的情况,导致数据丢失,或为开启新的副本集复制,此时若宕机节点数大于副本数时,可能导致部分数据不可用。若此时宕机数量小于副本集时,则在重建索引,或者手动启动副本复制后正常。
- 重建索引命令:
# 重建索引 POST _reindex { "source": { "index": "旧索引名" }, "dest": { "index": "新索引名" } } # 查看重建索引的设置 GET /新索引名 # 删除索引 DELETE /旧索引名 # 创建索引别名 POST /_aliases { "actions": [ { "add": { "index": "新索引名", "alias": "旧索引名" } } ] }
- 手动进行elasticsearch集群索引副本复制;
# 重新设置索引分片信息
PUT 索引名/_settings
{
"number_of_replicas" : **
}
-
在设置延迟复制副本集策略的生产集群,则需要进行手工启动复制副本集操作,以免出现数据丢失风险。
-
重建索引或大量写入过程中,若处于重建过程中,则黄色状态指示暂时的,需观察一段时间后再判断是否有异常。
-
当副本数大于数据节点数时,那么每个分片只能最多有
节点数量-1个副本,无法分配的副本数则为主分片数*(副本数-(节点数-1)),例如:假设节点数为3,主分片数为5,副本数为3,那么无法分配的副本数则为:5*(3-(3-1))=5。那么此时只需要重新设置索引副本分片数即可,具体操作如下:
# 重新设置索引分片信息
PUT 索引名/_settings
{
"number_of_replicas" : 2
}
执行结果如下:
{
“acknowledged” : true
}
查看修改后的索引配置
# 查看索引设置
GET /***/_settings
执行重新设置副本分片数后,最新settings如下:
{
"***" : {
"settings" : {
"index" : {
"creation_date" : "***",
"number_of_shards" : "***",
"number_of_replicas" : "2", // 关注此处的副本分片的大小已改变
"uuid" : "hXI3lFOlSVi6gnqREZzEwQ",
"version" : {
"created" : "***"
},
"provided_name" : "***"
}
}
}
}
此时再看集群健康状态:
{
"cluster_name" : "troll*",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : ***,
"number_of_data_nodes" : ***,
"active_primary_shards" : ***,
"active_shards" : ***,
"relocating_shards" : ***,
"initializing_shards" : ***,
"unassigned_shards" : ***, // ~注意看这里~
"delayed_unassigned_shards" : ***,
"number_of_pending_tasks" : ***,
"number_of_in_flight_fetch" : ***,
"task_max_waiting_in_queue_millis" : ***,
"active_shards_percent_as_number" : ***
}

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)