
(2020)指代消解ontoNotes_Release_5.0处理详细流程
最近在做指代消解的任务,目前才处理完数据部分,确实有些繁琐,因此记录准备用spanbert做的指代消解,所以该代码里的.sh文件: github代码数据获取获取数据部分也需要耐心,参考以下博客(可以搭配看)博客1博客2注意事项:在获取ontoNotes 5.0数据时,注册完LDC账号后,立马给LDC官方发邮件,告知你比较急,希望将管理员信息告诉你或者直接将你...
-
最近在做指代消解的任务,目前才处理完数据部分,确实有些繁琐,因此记录
-
准备用spanbert做的指代消解,所以该代码里的
.sh文件: github代码
数据获取
-
获取数据部分也需要耐心,参考以下博客(可以搭配看)
-
注意事项:
- 在获取ontoNotes 5.0数据时,注册完LDC账号后,立马给LDC官方发邮件,告知你比较急,希望将管理员信息告诉你或者直接将你拉入组织。
- 如果LDC告知你管理员信息,立马联系管理员。
数据处理
- 以spanbert中的setup_training.sh脚本为例,我之前是在win10上处理的,最好在Linux上处理(别担心我也是linux小白)
- 下方两个连接是官方的处理教程(参考即可)
步骤:
🐢 1.在 数据处理教程1 中下载(都在该页面中):
-
测试数据:conll-2012-test-official.v9.tar.gz 、conll-2012-test-supplementary.v9.tar.gz、conll-2012-test-key.tar.gz
-
ontonotes-release-5.0等加入组织后就可以下到

🐢 2. 将图中7个文件放在一个目录下,解压即可。
-
前6个conll解压后生成conll-2012文件夹
-
最后一个生成ontonotes-release-5.0文件夹
-
到此才刚下载好数据
-
setup_training.sh部分
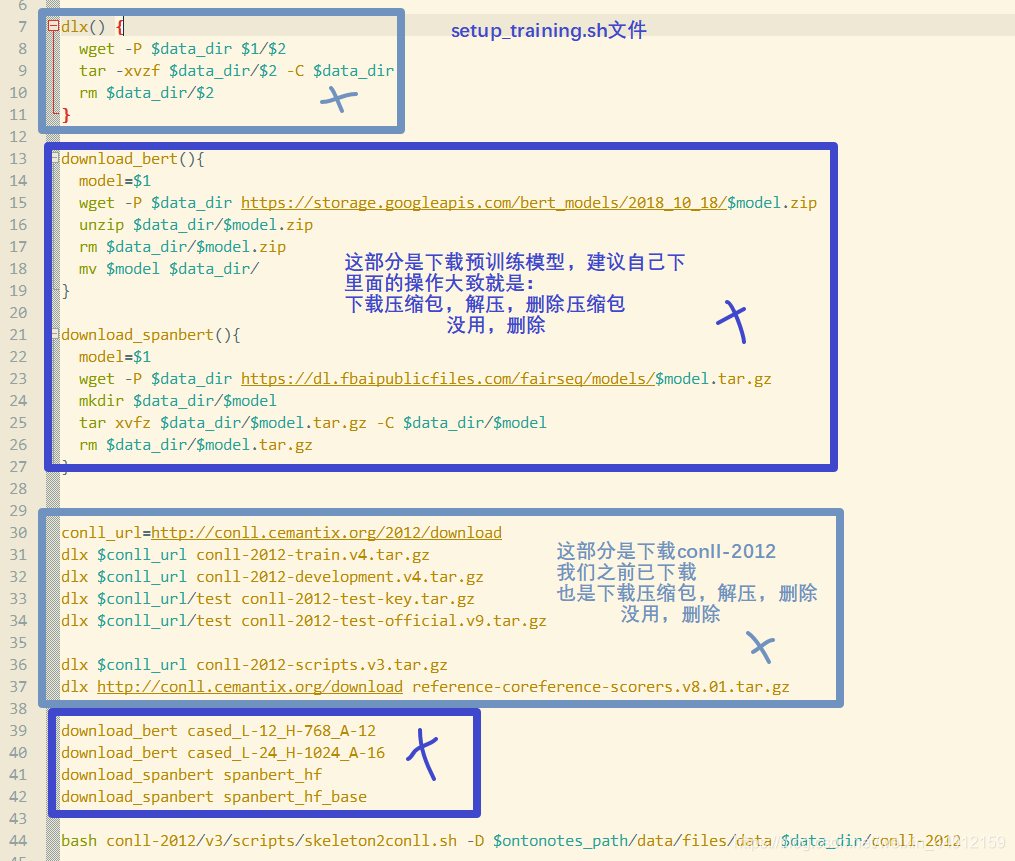
🐢 3. 执行setup_training.sh脚本
sh空格./setup_training.sh空格ontonotes-release-5.0路径空格conll-2012路径- 只要下图部分即可(下面部分也先去掉),因为这部分需要在python2运行,或者改成python3(我比较懒,文末有转换方法),不然会报错的

我自己的例子:setup_training.sh和conll-2012 ontonotes-release-5.0在同一级目录中,转到该文件目录,执行:sh空格./setup_training.sh空格./ontonotes-release-5.0空格./

🐢 4. Setup(代码中markdowm文件的步骤)
-
以下这部分按顺序执行,建议在linux中操作,主要涉及到.so动态库,windows不太好操作。
-
配置环境:
pip install -r requirements.txt -
export data_dir=</path/to/data_dir>(我是 export data_dir=./) -
./setup_all.sh: This builds the custom kernels(我是 bash ./setup_all.sh) -
现在的
setup_training.sh内容如下:
./setup_training.sh <ontonotes/path/ontonotes-release-5.0> $data_dir(我是bash空格./setup_training.sh空格./ontonotes-release-5.0/空格./)
🐢5. 最后会在
data_dir目录生成如下json文件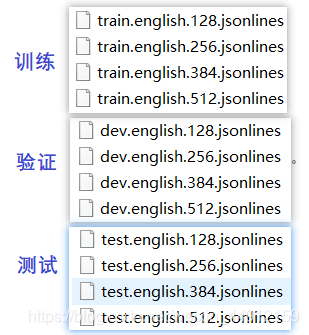
-
英文:训练集2802个文档,验证集343个文档,测试集348个文档
-
中文:训练集1810个文档,验证集252个文档,测试集218个文档
-
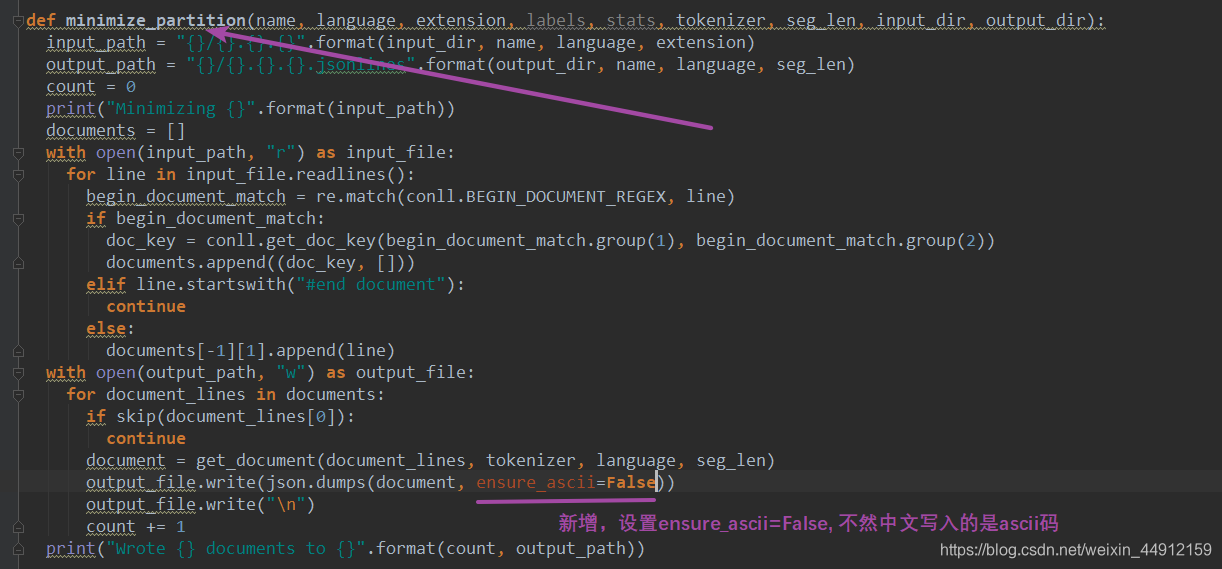
注:生成中文json需要修改的地方
setup_training.sh

minimize.py
-
-
到此数据处理完毕,不足之处还请指出,我将及时更正。
-
补充:If you are using Python 3.X, you have to edit the
conll-2012/v3/scripts/skeleton2conll.pyfile- Change
except InvalidSexprException, e:toexcept InvalidSexprException as e - Change all
printtoprint()
- Change

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)