语音识别可以直接编码吗
我们将声音数据直接每隔m个数据进行加和s,使用s代表m个数据的值,声音就变成了方波接下来我们将y值分为大于中间值m和小于中间值两个区域,这样就有了对齐的点,方便编码后进行逐个方波进行对比,接着对上下两个部分进行N分类,每分类值范围为(max−m)/N,(m−min)/N(max-m)/N,(m-min)/N(max−m)/N,(m−min)/N一个值v在某段值范围内就取值为该范围内的...
·
我们将声音数据直接每隔m个数据进行加和s,使用s代表m个数据的值,声音就变成了方波
 接下来我们将y值分为大于中间值m和小于中间值两个区域,
接下来我们将y值分为大于中间值m和小于中间值两个区域,
这样就有了对齐的点,方便编码后进行逐个方波进行对比,
接着对上下两个部分进行N分类,每分类值范围为
( m a x − m ) / N , ( m − m i n ) / N (max-m)/N,(m-min)/N (max−m)/N,(m−min)/N
一个值v在某段值范围内就取值为该范围内的最小值,
对比的之后不看值的大小,如图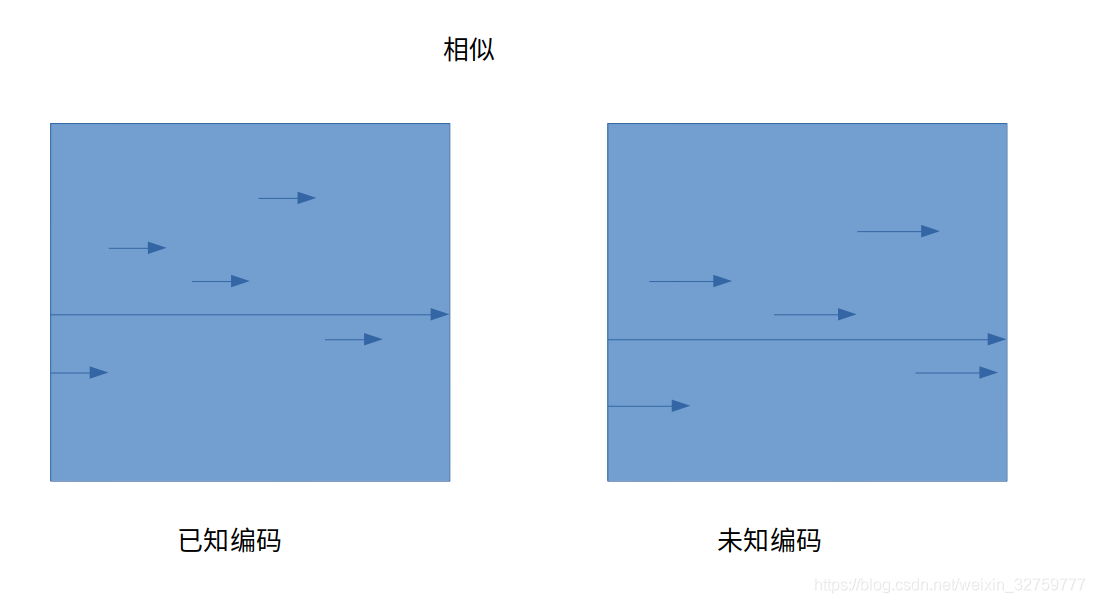 这样就可以进行语音识别了
这样就可以进行语音识别了

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)