kubeadm安装K8s 1.16集群--问题集锦
1、安装完毕后无法获取node信息2、Node节点join的时候发生错误3、kubeadm init重新初始化的时候报错4、初始化的一个问题5、coredns一直是pending6、安装完毕flannel 后coredns还是pending状态7、kubernetes和docker版本兼容性问题8、node节点无法查看pod状态9、coredns一直是ContainerCreating10、卸载.
1、安装完毕后无法获取node信息
问题
[root@master k8s]# kubectl get nodes
Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")

解决
[root@master home]# mkdir -p $HOME/.kube
[root@master home]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master home]# chown $(id -u):$(id -g) $HOME/.kube/config
2、Node节点join的时候发生错误
问题
[root@node1 k8s]# kubeadm join 192.168.3.100:6443 --token safdsafsafsafd \
> --discovery-token-ca-cert-hash sha256:safdsafsafsafdsafsafdsafdsafd
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-10250]: Port 10250 is in use

解决
node上重启kubeadm然后再join
[root@node1 k8s]# kubeadm reset
3、kubeadm init重新初始化的时候报错
问题
[root@master k8s]# kubeadm init --kubernetes-version=v1.15.0 --pod-network-cidr=10.1.0.0/16 --apiserver-advertise-address=192.168.3.100
[init] Using Kubernetes version: v1.15.0
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty

解决
直接删除/var/lib/etcd目录
[root@master k8s]#rm -rf /var/lib/etcd
4、初始化的一个问题
问题
[root@localhost ~]# kubeadm init --kubernetes-version=v1.16.1 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --ignore-preflight-errors=Swap
[init] Using Kubernetes version: v1.16.1
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-10251]: Port 10251 is in use
[ERROR Port-10252]: Port 10252 is in use
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables contents are not set to 1
[ERROR Port-10250]: Port 10250 is in use
解决
发现杀死进程都没有用,最终重启一下kubeadm就可以了
[root@localhost ~]# kubeadm reset
5、coredns一直是pending
问题
Master、node都安装完毕,并且node join了master
在master发现coredns一直是pending
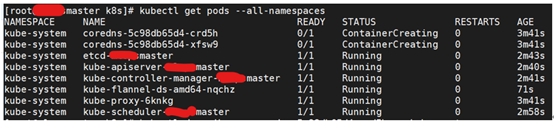
[root@master ~]# kubectl get pods --all-namespaces
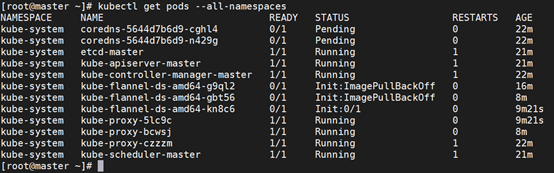
解决
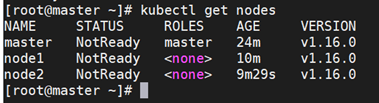
检查各节点状态,发现master、node都是notready状态
[root@master ~]# kubectl get nodes
查看kubeletl日志
[root@master ~]# journalctl -f -u kubelet.service
edVolume started for volume "cni" (UniqueName: "kubernetes.io/host-path/5accb47d-53bc-42d2-81c0-394bc9a2efee-cni") pod "kube-flannel-ds-amd64-g9ql2" (UID: "5accb47d-53bc-42d2-81c0-394bc9a2efee")
Dec 17 23:37:42 master kubelet[20121]: I1217 23:37:42.498480 20121 reconciler.go:154] Reconciler: start to sync state
Dec 17 23:37:43 master kubelet[20121]: W1217 23:37:43.504742 20121 cni.go:237] Unable to update cni config: no networks found in /etc/cni/net.d
Dec 17 23:37:47 master kubelet[20121]: E1217 23:37:47.255729 20121 kubelet.go:2187] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
Dec 17 23:37:48 master kubelet[20121]: W1217 23:37:48.505560 20121 cni.go:237] Unable to update cni config: no networks found in /etc/cni/net.d
报错信息显示网络插件没有准备好。
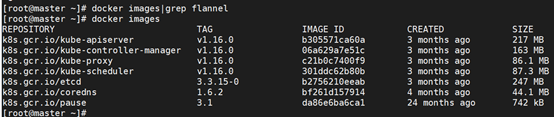
执行命令docker images|grep flannel来查看flannel镜像是否已经成功拉取下来,发现flannel镜像没有拉下来。
[root@master ~]# docker images |grep flannel
重新拉取flannel镜像
[root@master ~]#docker pull quay.io/coreos/flannel:v0.11.0-amd64
如果官方镜像无法下载。可以从阿里云下载
[root@master ~]#docker pull registry.cn-hangzhou.aliyuncs.com/kubernetes_containers/flannel:v0.11.0-amd64
[root@master ~]#docker tag registry.cn-hangzhou.aliyuncs.com/kubernetes_containers/flannel:v0.11.0-amd64 quay.io/coreos/flannel:v0.11.0-amd64
[root@master ~]#docker rmi registry.cn-hangzhou.aliyuncs.com/kubernetes_containers/flannel:v0.11.0-amd64
重新执行如下命令,启动flannel容器
[root@master home]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/62e44c867a2846fefb68bd5f178daf4da3095ccb/Documentation/kube-flannel.yml
6、安装完毕flannel 后coredns还是pending状态
问题
查看kubelet日志
[root@master ~]# journalctl -f -u kubelet.service
edVolume started for volume "cni" (UniqueName: "kubernetes.io/host-path/5accb47d-53bc-42d2-81c0-394bc9a2efee-cni") pod "kube-flannel-ds-amd64-g9ql2" (UID: "5accb47d-53bc-42d2-81c0-394bc9a2efee")
Dec 17 23:37:42 master kubelet[20121]: I1217 23:37:42.498480 20121 reconciler.go:154] Reconciler: start to sync state
Dec 17 23:37:43 master kubelet[20121]: W1217 23:37:43.504742 20121 cni.go:237] Unable to update cni config: no networks found in /etc/cni/net.d
Dec 17 23:37:47 master kubelet[20121]: E1217 23:37:47.255729 20121 kubelet.go:2187] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
Dec 17 23:37:48 master kubelet[20121]: W1217 23:37:48.505560 20121 cni.go:237] Unable to update cni config: no networks found in /etc/cni/net.d
解决
master重启kubeadm再init
[root@master ~]# kubeadm reset
[root@master ~]#kubeadm init --kubernetes-version=v1.16.0 --pod-network-cidr=172.22.0.0/16 --apiserver-advertise-address=192.168.3.100
node也要reset重启kubelet并要重新join
[root@node1 home]#kubeadm reset
[root@node1 home]#systemctl daemon-reload && systemctl restart kubelet
[root@node1 home]# kubeadm join 192.168.3.100:6443 --token vmuuvn.q7q14t5135zm9xk0 \
--discovery-token-ca-cert-hash sha256:c302e2c93d2fe86be7f817534828224469a19c5ccbbf9b246f3695127c3ea611
问题解决

7、kubernetes和docker版本兼容性问题
问题
[root@master ~]# journalctl -f -u kubelet.service
Dec 28 09:52:55 mlopsmaster kubelet[1842]: E1228 09:52:55.524231 1842 summary_sys_containers.go:47] Failed to get system container stats for "/system.slice/kubelet.service": failed to get cgroup
解决
所有节点都执行
[root@master kubelet.service.d]# pwd
/usr/lib/systemd/system/kubelet.service.d
[root@master kubelet.service.d]# ls
10-kubeadm.conf
编辑10-kubeadm.conf
新增: Environment=“KUBELET_MY_ARGS=–runtime-cgroups=/systemd/system.slice --kubelet-cgroups=/systemd/system.slice”
修改ExecStart: 在末尾新增 $KUBELET_MY_ARGS

保存之后,重启kubelet服务即可
[root@master kubelet.service.d]#systemctl daemon-reload
[root@master kubelet.service.d]#systemctl restart kubelet
8、node节点无法查看pod状态
问题
[root@node2 ~]# kubectl get pod -n kubeflow
The connection to the server localhost:8080 was refused - did you specify the right host or port?
解决
kubectl命令需要使用kubernetes-admin来运行。
将主节点中的【/etc/kubernetes/admin.conf】文件拷贝到子节点相同目录下,然后配置环境变量
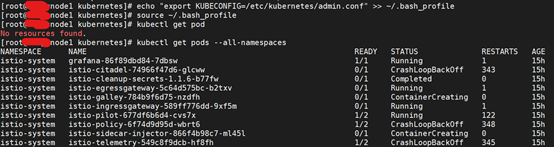
[root@node2 ~]#echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
立即生效
[root@node2 ~]#source ~/.bash_profile
9、coredns一直是ContainerCreating
问题
删除k8s后,修改节点名称并重装,node join后
查看pod信息,发现coredns一直是ContainerCreating
[root@master k8s]# kubectl describe po coredns-5c98db65d4-crd5h -n kube-system
e = Unknown desc = failed to set up sandbox container "0888e2b293742a71b1dbd0e473fc7e4c2f697be372f9c27820c14d7bb94f4830" network for pod "coredns-5c98db65d4-crd5h": NetworkPlugin cni failed to set up pod "coredns-5c98db65d4-crd5h_kube-system" network: failed to set bridge addr: "cni0" already has an IP address different from 10.1.0.1/24
解决
修改node名称后的遗留症状。所有节点执行如下
[root@master k8s]#rm -rf /var/lib/cni/flannel/* && rm -rf /var/lib/cni/networks/cbr0/* && ip link delete cni0
[root@master k8s]#rm -rf /var/lib/cni/networks/cni0/*
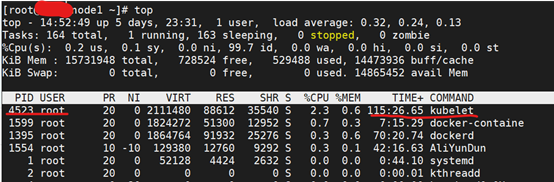
10、卸载K8S容器无法删除
问题

解决
Kubelet进程还在,杀掉kubelet进程,再删除容器
[root@node1 ~]# kill -9 4523
11、卸载后重新安装,init失败
问题
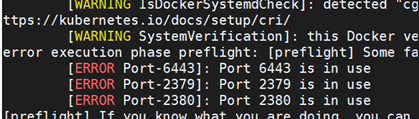
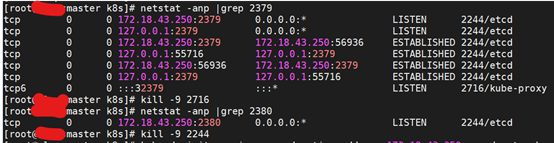
解决
卸载后k8s相关进程还在,导致端口被占用
杀掉相关进程再init

开源、云原生的融合云平台
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)