
Python dataframe.pivot()用法解析
python pandas 库的dataframe pivot()函数用法解析:简而言之,我理解的pivot()的用途就是,将一个dataframe的记录数据整合成表格(类似Excel中的数据透视表功能),而且是按照pivot(‘index=xx’,’columns=xx’,’values=xx’)来整合的。还有另外一种写法,但是官方貌似并没有给出来,就是pivot(‘索引列’,‘列名’,‘...
python pandas 库的dataframe pivot()函数用法解析:
简而言之,我理解的pivot()的用途就是,将一个dataframe的记录数据整合成表格(类似Excel中的数据透视表功能),而且是按照pivot(‘index=xx’,’columns=xx’,’values=xx’)来整合的。还有另外一种写法,
但是官方貌似并没有给出来,就是pivot(‘索引列’,‘列名’,‘值’)。
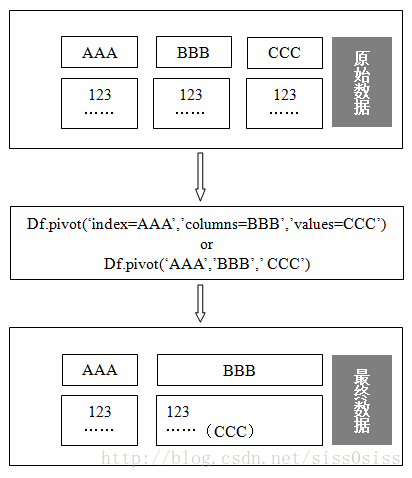
下面是官方描述:

============================================================================
Reshape data (produce a “pivot” table) based on column values. Uses unique values from index / columns to form axes of the resulting DataFrame.
译:重塑数据(产生一个“pivot”表格)以列值为标准。使用来自索引/列的唯一的值(去除重复值)为轴形成dataframe结果。
For finer-tuned control, see hierarchical indexing documentation along with the related stack/unstack methods
译:为了精细调节控制,可以看和stack/unstack方法有关的分层索引文件.
、============================================================================
以上内容来自链接:https://blog.csdn.net/siss0siss/article/details/77871027
在数据分析的时候要记得将pivot结果reset_index()。文章最后有关于reset_index()函数的说明
函数说明:
DataFrame.pivot(index=None, columns=None, values=None)
功能:重塑数据(产生一个“pivot”表格)以列值为标准。使用来自索引/列的唯一的值(去除重复值)为轴形成dataframe结果。
为了精细调节控制,可以看和stack/unstack方法有关的分层索引文件。
在数据分析的时候要记得将pivot结果reset_index()。
参数:index : string or object, optional
用于创建新框架索引的列名称。 如果没有,则使用现有的索引。
columns : string or object
用于创建新框架列的列名称
values : string or object, optional
用于填充新框架值的列名称。 如果未指定,则将使用所有剩余列,结果将具有分层索引列
返回:DataFrame
个人实践:
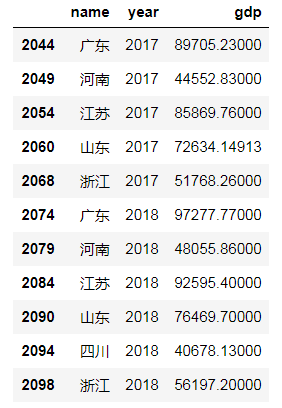
如图所示:这是在进行数据重塑之前的数据集,可以看到数据集包含三个字段的内容,分别是:name, year, gdp
采用pivot函数对数据集进行重塑(再说一遍:跟Excel中的数据透视表功能类似)
#对数据进行重塑
df = df.pivot(index='name',columns='year',values='gdp')
df = df.reset_index()
df.fillna(1.0,inplace=True)
dfdf = df.pivot(index='name',columns='year',values='gdp')的功能
新数据集索引列 = 原数据集'name'列中的值
新数据集列名 = 原数据集‘year’列中的值
新数据集数据 = 原数据集'gdp'列中的值
得到的结果如下图:

转换关系如下:

关于reset_index()的说明
reset_index() 官方文档
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
| level | 将df的原index_label作为新的一列留存,且列名为index,同时自动生成数字index |
| drop | defalt False,如果是True,删除原来索引 |
| inplace | 下面几个都是Multiindex下的参数,后续研究 |
常用于在数据清洗过后,对数据重新设置连续行索引。

————————————————
版权声明:本文为CSDN博主「Quant_Learner」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/The_Time_Runner/article/details/84076716

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 35
35 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)