
RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving(2020.1)
代码:https://github.com/Banconxuan/RTM3D.摘要:单目3D检测框架的检测器利用的是3D bounding box与2D box的投影关系。2D box的四个边缘仅提供四个约束,并且就算2D检测器的误差小,性能也会下降不少。我们的方法在图像空间预测了9个关键点,利用3D和2D的几何关系,在3D空间还原出 大小、位置和方向。即使估计的关键...
代码:https://github.com/Banconxuan/RTM3D.
摘要:
单目3D检测框架的检测器利用的是3D bounding box与2D box的投影关系。2D box的四个边缘仅提供四个约束,并且就算2D检测器的误差小,性能也会下降不少。
我们的方法在图像空间预测了9个关键点,利用3D和2D的几何关系,在3D空间还原出 大小、位置和方向。即使估计的关键点存在噪声,但是估计的目标属性还是比较稳定,使得利用小结构的网络也能够快速检测。训练时,只使用目标3D属性,不需要额外的网络和数据。
一、介绍
单目3D检测大致由训练数据分两类:
- 一种利用复杂特征,如实例分割、车辆形状先验、甚至深度图,在多阶段融合模块中选择最佳建议。这些功能需要额外的注释工作来训练一些独立的网络,这将在训练和推断阶段消耗大量的计算资源。
- 另一种只使用了2D bounding box 和3D目标属性作为监督数据。
本方法思路就是:建立一个深层回归网络来直接预测目标的3D信息。但是由于需要搜索大量空间,会使效果出现限制,于是最近的方法应用从3D box顶点到2D box边缘之间的几何约束来修正并预测目标参数。
2D box的4条边只提对恢复3D box提供4个约束,而3D box的顶点可能与2D box任何一条边都有关。同时对2D box的过度依赖使得当2D box有轻微的错误会对3D box的预测效果有巨大影响。因此,这些方法大多利用两级检测器来保证2D box预测的准确性,这限制了检测速度的上限。
本文提出单过程单目3D检测,并且没有利用2D 检测器处理3D检测,如图1(Figure1)所示,分为两部分:
- 首先对3D box进行参数估计,其中8个顶点,1个中心点,这9个点为3D box提供了18个几何约束。受【47】CenterNet启发,对8个顶点和中心点进行建模来解决关键点建群、顶点顺序问题。使用SIFT,SUFT以及其他传统方法进行关键点检测,并计算图像金字塔来解决尺度不一致问题。同样使用了CenterNet 的后处理操作增加准确性,但处理速度变慢。注意,2D目标检测中的特征金字塔网络(FPN)[23]
不适用于关键点检测网络,因为在小尺度预测的情况下,相邻的关键点可能会重叠。我们提出多尺度金字塔关键点检测方法来产生尺度空间响应。通过soft-weighted金字塔的方法,可以得到最终的关键点激活图。 - 当给定9个投影点时,下一步就是最小化由物体的位置、尺寸、方向参数化的3D点的透视图上的重投影误差。重投影误差由SE3空间的多元公式表示。对维度、方向、距离的先验信息对基于特征点的方法影响进行讨论。获得此信息的前提是不增加计算量,以免影响检测速度。 我们对这些先验模型进行建模,并将重投影和先验误差项建立整体能量函数,以进一步改善3D估计。

图1:方法概述:首先预测由八个顶点和3D对象的中心点在图像空间中投影的序数关键点。 然后,我们通过使用透视投影的几何约束将3D边界框的估计重新构造为使能量函数最小化的问题。
贡献如下:
- 我们将单目3D检测化为关键点检测问题,并结合几何约束生成3D对象的属性
- 提出单级多尺度3D关键点检测网络,可为多尺度目标提供准确的投影点
- 提出了可以同时优化先验和3D对象信息的能量函数
- 根据KITTI基准评估,第一种使用实时3D检测方法,并且在相同的运行时间下与其他方法具有更高的精度
二、相关工作
3D检测的数据类型分为两种:雷达 和 基于图像的方法
雷达:
基于LiDAR的系统可以在3D场景中提供物体表面的准确和可靠的点云。 因此,大多数最近的3D对象检测以不同的表示形式使用它来获得准确模型
基于图像的3D目标检测的额外数据和网络:
由于相机的方便和廉价,图像3D目标检测研究兴起。由于缺少深度信息,之前方法依赖于独立网络或者额外的标注数据,如:实例分割、立体视觉、线框模型、CAD先验以及深度,如Table1所示。

表1:比较不同图像检测方法的实时状态和附加数据的需求
- 从单张图像中获得可靠的3D信息十分有难度。第一个例子[7]列举了大量来自预定义空间的三维建议,检测对象可能出现在这些几何位置上。然后,选用其他先验比如:形状、实例分割、语义特征等来过滤不合理建议并且利用分类器对他们进行打分(score)。
- 为了弥补深度不足,[42]嵌入了一个预训练的独立模块来估计视差和3D点云。 视差图与前视图表示进行结合,以帮助2D提案网络,并通过融合RoI池化后提取的特征(有效特征)以及点云来增强3D检测。
- [27]结合2D检测器和单目深度估计模块来得到2D box和相关的点云,通过注意机制将图像特征和3D点信息进行融合后,通过PointNet [32]的回归来获得最终的3D框。
但是额外的网络和标注的数据会带来更多的计算,并加重工作
仅图像的单目3D目标检测:
近期工作探索RGB图像在3D检测中的作用。大多数都包括几何约束和2D检测器,以明确描述对象的3D信息。
[28]使用CNN估计2D box中提取特征的尺寸和方向,然后提出利用3D顶点和2Dbox边缘之间的透视关系的几何约束来获得物体的位置,大多数基于图像的检测方法都会在调整中或直接对3D对象进行计算。我们知道这个约束是某个3D点被投影到了2D box边缘,但是相应关系和投影的具体位置并不清楚。
因此,它需要枚举84 = 4096个配置来确定最终对应关系,并且只能提供四个约束,这不足以在9个参数中进行完整的3D表示,因此需要估计其他先验信息。 然而,2D box中可能存在的不精确部分可能会导致带有少量约束的结果不准准确。因此,这些方法大多通过两级检测来获得更精确的2D box,而这很难得到实时的速度。
单目3D目标检测的关键点:
经证明,如果能从车辆关键点推断出完整形状,可以提高遮挡物和截断物的检测精度。一般使用线框模板来表示常规形状的车辆,该模板是从大量CAD模型获得的。为了训练关键点检测网络,他们需要重新标记数据集,甚至使用深度图来增强检测能力。
[14]与我们的工作最相关,后者也将线框模型视为先验信息。此外,它通过四个不同的网络共同优化2D box,2D关键点,3D方向,尺度假设,形状假设和深度。也因此不能实时处理。
我们将3D检测重新构造为稀疏关键点检测任务。 无需基于现成的2D检测器或其他数据生成器来预测3D框,而是建立一个网络来预测8个顶点和3D box中心投影的9个2D 关键点,同时将重投影误差最小化以找到最佳结果 。
三、方法
3.1 特征点监测网络
关键点检测网络仅将RGB图像作为输入,并从3D bounding box的顶点和中心生成透视点。如Figure2所示,包含三个主要部分:主干网络、特征点金字塔网络和检测头。主要结构采用单步策略,与anchor-free 2D目标检测器[38, 16, 47, 19]采用相似分布,从而进行快速检测。
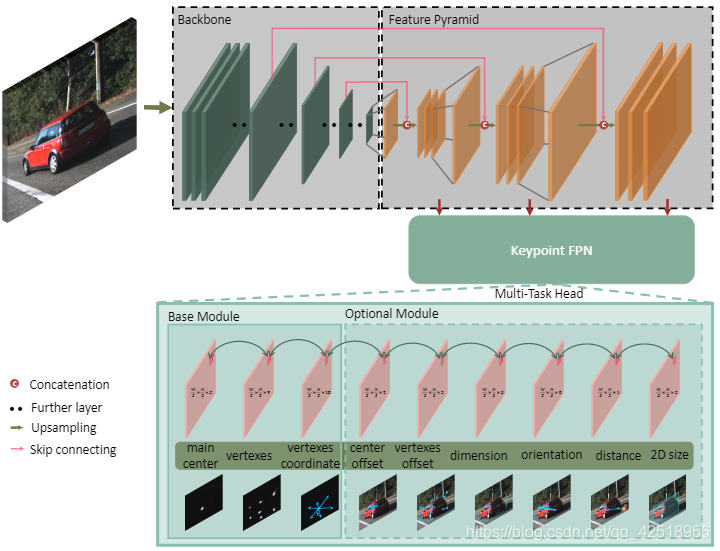
图2:关键点检测结构:它仅以RGB图像为输入,并输出主要中心heatmap,顶点heatmap和顶点坐标作为基本模块来估计3D边界框。 它还可以预测其他先验,以进一步提高3D检测的性能
主干网络:
在权衡速度和精度时,选用了ResNet18 和DLA-34 结构。两模块都是讲单张RGB作为输入,并且进行S=4的下采样。ResNet18 和DLA-34是用作图像分类的网络,其最大下采样因子为×32。
我们通过三个双线性插值和1×1卷积层对bottleneck三次进行上采样。 在上采样层之前,我们连接了相应的低级特征图,同时添加了一个1×1卷积层以减小通道维度。 经过三个上采样层后,通道分别为256、128、64
关键点特征金字塔:
图像中的关键点在大小上没有差异。 因此,关键点检测不适合使用特征金字塔网络(FPN)[23],该网络可以检测不同金字塔层中的多尺度2Dbox。 我们提出了关键点特征金字塔网络(KFPN),以检测点向空间中尺度不变的关键点,如Figure3所示。

图三:keypoint feature pyramid network(KFPN)
假设我们有F尺度的特征图,我们先将每个尺度f,1<f<F,还原到最大尺度,然后,我们通过softmax运算生成轻权重以表示每个尺度的重要性。 通过线性加权和获得最终的尺度空间得分图Sscore。 定义如下
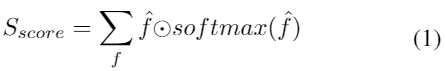
检测头:
由三个基本组件和六个可选组件组成,可以选择组合来提高3D检测准确性。 受CenterNet [47]的启发,我们选一个关键点作为连接所有特征的主要中心。 由于截断情况下对象的3D投影点可能会超出图像边界,因此将更适当地选择2D框中心点。
Heatmap定义为![]() ,其中C是目标种类的数量,另一部分是由顶点和中心点投影出的9个透视点
,其中C是目标种类的数量,另一部分是由顶点和中心点投影出的9个透视点![]()
,对于一个目标的关键点整合,我们还对从maincenter的局部偏移![]() 进行回归作为标志,将距离Vc坐标最近的V的关键点作为一个对象的集合。
进行回归作为标志,将距离Vc坐标最近的V的关键点作为一个对象的集合。
尽管9个关键点的18个的约束能够恢复物体的3D信息,但是越多的先验条件能够增加更多的约束,中心偏移![]() ,顶点偏移
,顶点偏移![]() 是heatmap中对每个关键点的离散误差。
是heatmap中对每个关键点的离散误差。
3D目标的维度D 方差较小很容易预测,对象的旋转R(θ)只有在自主驾驶场景对方向θ(偏航)进行参数化。我们引用基于Multi-Bin [28]方法对局部方向进行回归。将局部角度的余弦偏移和正弦偏移概率在1个bin中进行分类,并使用2个bin生成方向特征图
![]() ,我们还对3D box的中心深度
,我们还对3D box的中心深度![]() 进行回归,用来初始化Sec3.2的值,并进行加速。
进行回归,用来初始化Sec3.2的值,并进行加速。
训练:
关键点的所有heatmap按照[47].[19]进行训练,使用focal loss 解决了正反例的不平衡,其中K是不同关键点的通道数,在maincenter K=C,在计算顶点K=9. N是一张图像的maincenter或顶点数,α 和 β为减少损失权重的超参数,Pxy可以由高斯核![]() 定义并以真正的关键点为中心。对于σ,我们找到了训练数据中的2D box的最大最小区域Amax,Amin,并设置两个超参数σmax,σmin 然后定义大小为A的目标
定义并以真正的关键点为中心。对于σ,我们找到了训练数据中的2D box的最大最小区域Amax,Amin,并设置两个超参数σmax,σmin 然后定义大小为A的目标 ![]() ,为了对维度和距离进行回归,定义残差部分为:
,为了对维度和距离进行回归,定义残差部分为:
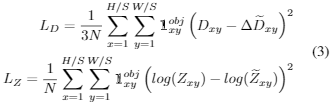
我们设置![]() ,其中
,其中![]() 为训练数据的平均和标准差维度,
为训练数据的平均和标准差维度,![]() 代表maincenter是否出现在位置x,y,maincenter,顶点由L1损失进行训练:
代表maincenter是否出现在位置x,y,maincenter,顶点由L1损失进行训练:

其中![]() 为maincenter和顶点在原始图像的位置,使用L1损失的顶点回归坐标为:
为maincenter和顶点在原始图像的位置,使用L1损失的顶点回归坐标为:
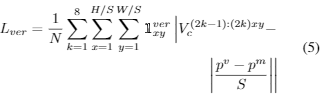
最后为关键点检测的多任务损失进行定义:
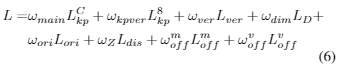
3.2 3D bounding box估计
考虑一张图像,有一组 i = 1...N的目标,由9个关键点和其他先验知识表达,由我们的关键点检测网络给出。我们将关键点定义为![]() 其中 j = 1...9,
其中 j = 1...9,![]() 为维度,方向为
为维度,方向为![]() ,距离为
,距离为![]() 。相应的3D bounding box Bi由它的旋转
。相应的3D bounding box Bi由它的旋转![]() ,位置
,位置![]() ,以及维度
,以及维度![]() 定义。
定义。
我们的目标是找出3D box,找出哪一个box的中心点和顶点投影与2D 关键点 ![]() 最匹配。这能够最小化3D 关键点和2D 关键点的投影损失,并将它和其他先验损失定义为一个非线性最小二乘优化问题:
最匹配。这能够最小化3D 关键点和2D 关键点的投影损失,并将它和其他先验损失定义为一个非线性最小二乘优化问题:
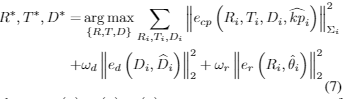
其中![]() 是相机点、维度先验、方向先验的损失。
是相机点、维度先验、方向先验的损失。![]() 是关键点投影误差的协方差矩阵。它是从对应于关键点的heatmap中提取的置信度:
是关键点投影误差的协方差矩阵。它是从对应于关键点的heatmap中提取的置信度:
![]()
Camera-Point:
按照[10],我们定义了8顶点和中心点的齐次坐标:
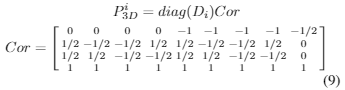
给定内参矩阵K,我们将3D点投影到图像坐标为:
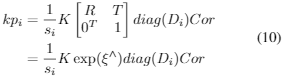
其中![]() ,使用exp将se3转换到SE3空间,投影坐标应与检测网络检测到的二维关键点紧密配合。因此,相机点误差定义为:
,使用exp将se3转换到SE3空间,投影坐标应与检测网络检测到的二维关键点紧密配合。因此,相机点误差定义为:
![]()
最小化相机点误差需要se3空间的雅可比矩阵:

其中![]()
维度先验:
Ed被定义如下:
![]()
旋转先验
我们在SE3空间定义Er,并使用log将error映射到切向量空间:
![]()
这些多元方程可以通过g2o库[18]中的Gaussnewton或Levenberg-Marquardt算法求解。我们采用由关键点检测网络产生的先验信息作为初始值,这对提高检测速度非常重要。
四、实验
4.1 实验细节
4.2 方法比较
评估基于关键点方法的效果,对KITTI进行三个官方评估指标:3D交叉点联合平均精度(AP3D),鸟瞰图平均精度(APBEV),平均方向相似度(AOS)(如果2D box可行),根据图像空间中目标的遮挡、截断和高度分为简单、中等、困难难度。
AP3d和APbev:
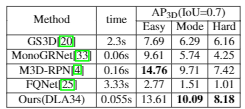
AP3D、APbev以及运行时间如Table2、3,ResNet-18作为主干网络在精度和速度都很有效。比Mono3D【7】在效果提高10%的情况下速度快了100倍。比使用双目图像作为输入的3DOP【8】快了75倍。用DLA-34作为主干网络比最近的M3D-RPN【4】快了三倍并且效果更好,
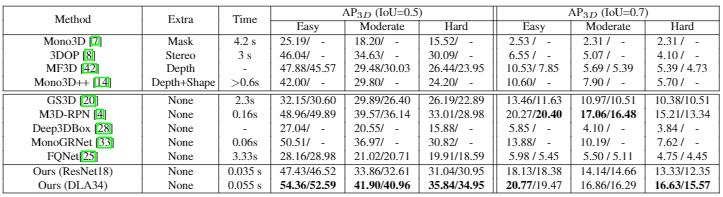
表2:与基于图像的汽车类别三维检测框架进行比较,使用度量AP3D对KITTI数据集的val1 / val2进行评估

表3:APBEV对比
KITTI测试集结果:
4.3 定性实验
如Figure4,我们将关键点监测网络、几何约束模块、BEV图像输出可视化,实验证明图像的3D box比其他方法更能解决拥挤截断的目标,BEV结果展现了不同场景的准确度。

图.4:从上到下是关键点,3D box和鸟瞰图的投影,绿色是真值和蓝色的预测。深红色箭头、绿色箭头和红色箭头分别指向被遮挡的、远处的和截断的对象
4.4 消融实验
可选项作用:
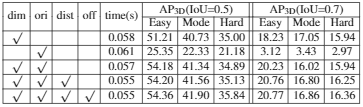
三个可选项:维度、方向、距离和关键点偏移。通过不同组合证明对3D检测效果影响。如Table5,用DLA-34训练网络,使用AP3D和APbev评估,将四个附加项全部使用得到了最高准确率,这是因为将我们网络的输出作为几何优化模块的初始值,减少了梯度下降方法的搜索空间
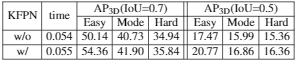
关键点FPN作用:
2D检测和方向:
尽管主要研究3D检测,但是也对2D检测和方向评估效果进行比较,对阈值IoU=0.7的AOS和AP进行比较,如Table7。Deep3DBox训练了MS-CNN【5】来生成2D box并使用VGG16对方向进行预测准确率高。Deep3DBox利用了更好的2D 检测器,然而我们的AP3D在中等难度比它高出20%,说明了对于3D检测的重要性。另一点是,由于我们的方法可以推出目标的范围,使得3D反向投影的2D结果比直接预测要准。

Ours(2D)代表关键点检测网络的结果,而Ours(3D)是投影3D box的2D bounding box

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)