
Matlab TreeBagger随机森林回归实例
简介这里是一个在Matlab使用随机森林(TreeBagger)的例子。随机森林回归是一种机器学习和数据分析领域常用且有效的算法。本文介绍在Matlab平台如何使用自带函数和测试数据实现回归森林,对于随机森林和决策树的相关理论原理将不做太深入的描述。算法流程(1)加载Matlab测试数据集;(2)获取计算机性能,以便最好地利用其性能;(3)训练TreeBagger(随机森林);(4)创...
简介
在探寻变量之间相关性时,简单线性相关容易实现,对于多元的非线性关系,如果不知道关系式(函数方程)很难建立自变量和因变量之间关系。而机器学习方法为解决这类复杂多元非线性问题提供了很好的思路。
其中,随机森林回归是一种机器学习和数据分析领域常用且有效的算法。本文介绍在Matlab平台如何使用自带函数(TreeBagger)和测试数据实现回归森林,对于随机森林和决策树的相关理论原理将不做太深入的描述。
算法流程
(1)加载Matlab测试数据集;
(2)训练TreeBagger(随机森林);
(3)创建散点图;
(4)估计输入变量的相对重要性;
(5)检查需要多少棵树。
TreeBagger介绍
TreeBagger集成了一组决策树,用于分类或回归。集成中的每棵树都生长在独立绘制的输入数据的引导程序副本上。该副本中未包含的观察结果对于该树而言是“无用之物”。
TreeBagger将决策树用于分类或回归。TreeBagger依靠ClassificationTree和 RegressionTree功能来生长单个树。ClassificationTree和RegressionTree接受为每个决策拆分随机选择的特征数作为可选输入参数。也就是说, TreeBagger实现了随机森林算法。
对于回归问题,TreeBagger支持均值和分位数回归(即分位数回归森林)。
默认情况下,TreeBagger为分类树。要使用回归树,请指定 ‘Method’,‘regression’。
语法
Mdl = TreeBagger(NumTrees,Tbl,ResponseVarName)
Mdl = TreeBagger(NumTrees,Tbl,formula)
Mdl = TreeBagger(NumTrees,Tbl,Y)
B = TreeBagger(NumTrees,X,Y)
B = TreeBagger(NumTrees,X,Y,Name,Value)
描述
Y是相应自变量数据的因变量数组,对于分类问题, Y是一组类标签。标签可以是数字或逻辑向量等。对于回归问题,Y是一个数值向量。对于回归树,必须指定名称-值对 ‘Method’,‘regression’。
若要预测均值响应或估计给定数据的均方误差,请分别传递TreeBagger模型和数据分析。要对袋外观测数据执行类似的操作,请使用oobPredict或oobError。
要估计给定数据的响应分布的分位数或分位数误差,请将TreeBagger模型和数据分别传递给quantilePredict或quantileError。要对袋外观察执行类似的操作,请使用oobQuantilePredict或oobError。
测试数据集下载
波士顿房价数据集:http://t.cn/RfHTAgY
https://download.csdn.net/download/wokaowokaowokao12345/12243422
或者使用Matlab自带测试数据集。
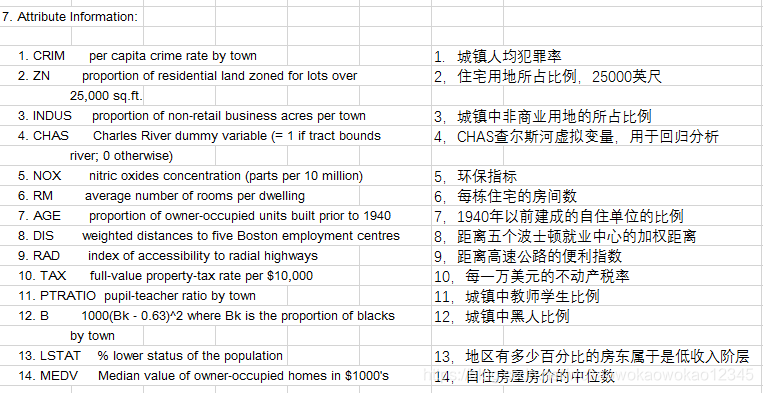
波士顿房价数据集是一个回归问题数据集,共有 506 个样本,13 个输入变量和1个输出变量。每条数据包含房屋以及房屋周围的详细信息。其中包含城镇犯罪率,一氧化氮浓度,住宅平均房间数,到中心区域的加权距离以及自住房平均房价等等。房价是因变量,其它变量为自变量。
例子1
https://www.mathworks.com/help/stats/regression-treeBagger-examples.html
clear;clc;close all
%%
% 加载Matlab提供的测试数据——使用1985年汽车进口量数据库,其中包含205个样本数据,25个自变量和1个因变量
load imports-85;
Y = X(:,1);
X = X(:,2:end);
isCategorical = [zeros(15,1);ones(size(X,2)-15,1)]; % Categorical variable flag
% 设置随机生成器种子,实际运用中可以注释掉,以获得随机性
rng(1945,'twister')
%% 最优leaf选择
% 对于回归,一般规则是将叶子大小设置为5。通过比较不同叶子数量MSE获得最佳叶子数量
% 叶子数量越少MSE越小,即使如此也肯定不是越小越好,这里就假设leaf=5是最优了
leaf = [5 10 20 50 100];
col = 'rbcmy';
figure
for i=1:length(leaf)
b = TreeBagger(50,X,Y,'Method','R','OOBPrediction','On',...
'CategoricalPredictors',find(isCategorical == 1),...
'MinLeafSize',leaf(i));
plot(oobError(b),col(i))
hold on
end
xlabel('Number of Grown Trees')
ylabel('Mean Squared Error')
legend({'5' '10' '20' '50' '100'},'Location','NorthEast')
hold off
%% 树的数量设置,前面用了50棵树(为了收敛速度快),接下来增加到100
b = TreeBagger(100,X,Y,'Method','R','OOBPredictorImportance','On',...
'CategoricalPredictors',find(isCategorical == 1),...
'MinLeafSize',5);
% 绘制误差曲线
figure
plot(oobError(b))
xlabel('Number of Grown Trees')
ylabel('Out-of-Bag Mean Squared Error')
%% 自变量重要性分析
% 自变量对RF模型贡献有大有小,RF的预测能力依赖于贡献大的自变量。对于每个自变量,可以观察其重要性,进行取舍组合,并查看MSE是否有改善。
% OOBPermutedPredictorDeltaError提供了每个自变量的重要性,值越大,变量越重要。
figure
bar(b.OOBPermutedPredictorDeltaError)
xlabel('Feature Number')
ylabel('Out-of-Bag Feature Importance')
% 选择重要性大于0.7的变量
idxvar = find(b.OOBPermutedPredictorDeltaError>0.7)
idxCategorical = find(isCategorical(idxvar)==1);
finbag = zeros(1,b.NTrees);
for t=1:b.NTrees
finbag(t) = sum(all(~b.OOBIndices(:,1:t),2));
end
finbag = finbag / size(X,1);
figure
plot(finbag)
xlabel('Number of Grown Trees')
ylabel('Fraction of In-Bag Observations')
%% 使用选择的特征重新训练
b5v = TreeBagger(100,X(:,idxvar),Y,'Method','R',...
'OOBPredictorImportance','On','CategoricalPredictors',idxCategorical,...
'MinLeafSize',5);
figure
plot(oobError(b5v))
xlabel('Number of Grown Trees')
ylabel('Out-of-Bag Mean Squared Error')
figure
bar(b5v.OOBPermutedPredictorDeltaError)
xlabel('Feature Index')
ylabel('Out-of-Bag Feature Importance')
%% 找到样本数据中的异常数据
b5v = fillProximities(b5v);
figure
histogram(b5v.OutlierMeasure)
xlabel('Outlier Measure')
ylabel('Number of Observations')
figure(8)
[~,e] = mdsProx(b5v,'Colors','K');
xlabel('First Scaled Coordinate')
ylabel('Second Scaled Coordinate')
figure
bar(e(1:20))
xlabel('Scaled Coordinate Index')
ylabel('Eigenvalue')
例子2
clear;clc;close all
%%
% 加载Matlab提供的测试数据——使用1985年汽车进口量数据库,其中包含205个样本数据,25个自变量和1个因变量
load imports-85;
Y = X(:,1);
X = X(:,2:end);
isCategorical = [zeros(15,1);ones(size(X,2)-15,1)]; % Categorical variable flag
%% 训练随机森林,TreeBagger使用内容,以及设置随机森林参数
tic
leaf = 5;
ntrees = 200;
fboot = 1;
disp('Training the tree bagger')
b = TreeBagger(ntrees, X,Y, 'Method','regression', 'oobvarimp','on', 'surrogate', 'on', 'minleaf',leaf,'FBoot',fboot);
toc
%% 使用训练好的模型进行预测
% 这里没有单独设置测试数据集合,如果进行真正的预测性能测试,使用未加入至模型训练的数据进行预测测试。
disp('Estimate Output using tree bagger')
x = Y;
y = predict(b, X);
toc
% calculate the training data correlation coefficient
% 计算相关系数
cct=corrcoef(x,y);
cct=cct(2,1);
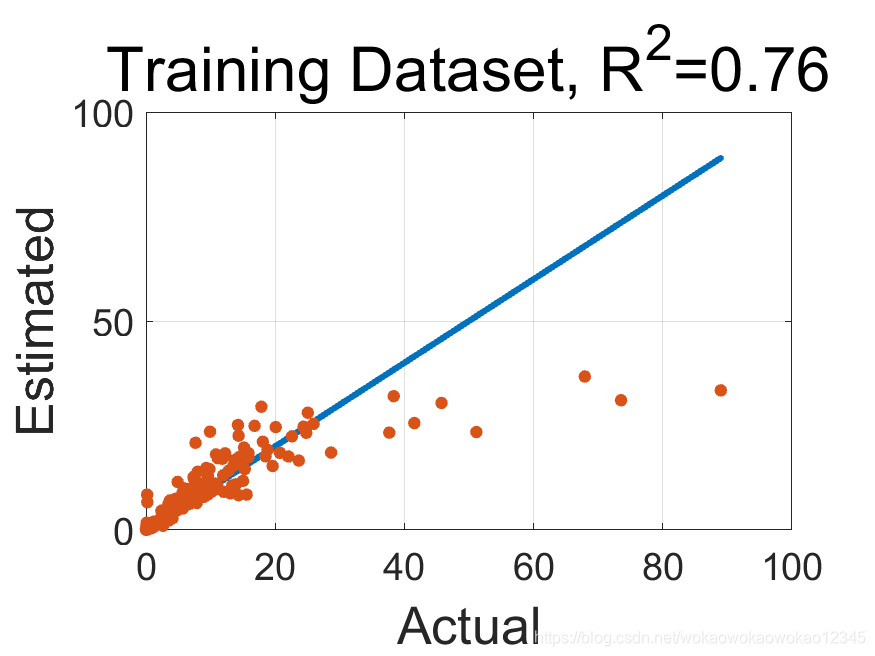
% Create a scatter Diagram
disp('Create a scatter Diagram')
% plot the 1:1 line
plot(x,x,'LineWidth',3);
hold on
scatter(x,y,'filled');
hold off
grid on
set(gca,'FontSize',18)
xlabel('Actual','FontSize',25)
ylabel('Estimated','FontSize',25)
title(['Training Dataset, R^2=' num2str(cct^2,2)],'FontSize',30)
drawnow
fn='ScatterDiagram';
fnpng=[fn,'.png'];
print('-dpng',fnpng);
%--------------------------------------------------------------------------
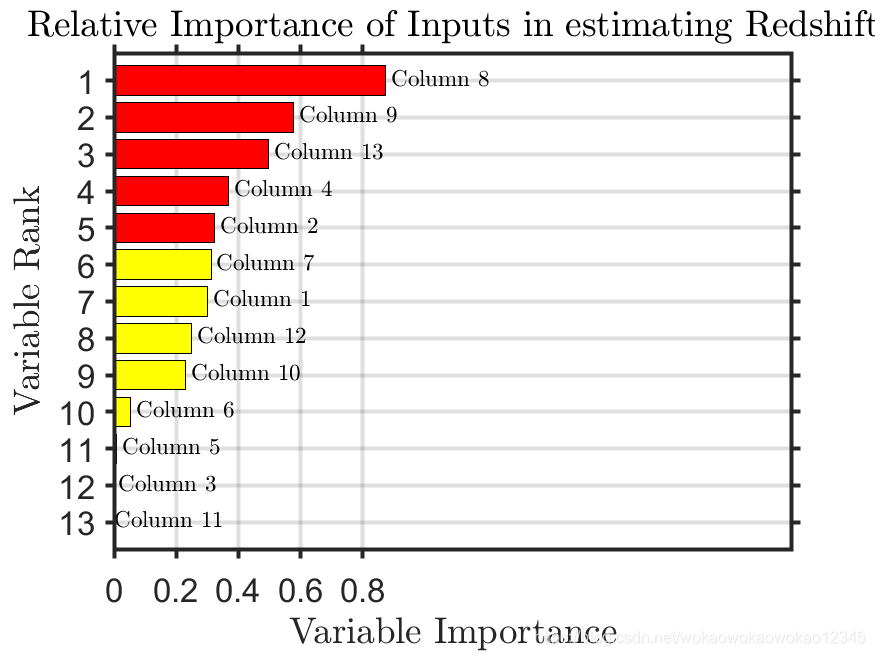
% Calculate the relative importance of the input variables
tic
disp('Sorting importance into descending order')
weights=b.OOBPermutedVarDeltaError;
[B,iranked] = sort(weights,'descend');
toc
%--------------------------------------------------------------------------
disp(['Plotting a horizontal bar graph of sorted labeled weights.'])
%--------------------------------------------------------------------------
figure
barh(weights(iranked),'g');
xlabel('Variable Importance','FontSize',30,'Interpreter','latex');
ylabel('Variable Rank','FontSize',30,'Interpreter','latex');
title(...
['Relative Importance of Inputs in estimating Redshift'],...
'FontSize',17,'Interpreter','latex'...
);
hold on
barh(weights(iranked(1:10)),'y');
barh(weights(iranked(1:5)),'r');
%--------------------------------------------------------------------------
grid on
xt = get(gca,'XTick');
xt_spacing=unique(diff(xt));
xt_spacing=xt_spacing(1);
yt = get(gca,'YTick');
ylim([0.25 length(weights)+0.75]);
xl=xlim;
xlim([0 2.5*max(weights)]);
%--------------------------------------------------------------------------
% Add text labels to each bar
for ii=1:length(weights)
text(...
max([0 weights(iranked(ii))+0.02*max(weights)]),ii,...
['Column ' num2str(iranked(ii))],'Interpreter','latex','FontSize',11);
end
%--------------------------------------------------------------------------
set(gca,'FontSize',16)
set(gca,'XTick',0:2*xt_spacing:1.1*max(xl));
set(gca,'YTick',yt);
set(gca,'TickDir','out');
set(gca, 'ydir', 'reverse' )
set(gca,'LineWidth',2);
drawnow
%--------------------------------------------------------------------------
fn='RelativeImportanceInputs';
fnpng=[fn,'.png'];
print('-dpng',fnpng);
%--------------------------------------------------------------------------
% Ploting how weights change with variable rank
disp('Ploting out of bag error versus the number of grown trees')
figure
plot(b.oobError,'LineWidth',2);
xlabel('Number of Trees','FontSize',30)
ylabel('Out of Bag Error','FontSize',30)
title('Out of Bag Error','FontSize',30)
set(gca,'FontSize',16)
set(gca,'LineWidth',2);
grid on
drawnow
fn='EroorAsFunctionOfForestSize';
fnpng=[fn,'.png'];
print('-dpng',fnpng);
实验结果


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 71
71 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)