西蒙斯的赚钱秘籍:隐马尔科夫模型(HMM)的择时应用
摘要:西蒙斯是被量化圈所广为追捧的量化之神,旗下的大奖章基金创造了无数神话。成立初期的创始人中,有一位科学家发明了广泛应用在语音识别等领域的鲍姆-威尔士算法。隐马尔可夫模型(HMM)已经被成功应用在工程领域,并取得了具有科学意义和应用价值的重要成果。本文将西蒙斯大奖章基金的利器-隐马尔可夫模型应用到我国股市的预测中,通过对股票数据序列的模式识别来对大盘走势进行预测。一、前言:从大...
摘要:
西蒙斯是被量化圈所广为追捧的量化之神,旗下的大奖章基金创造了无数神话。成立初期的创始人中,有一位科学家发明了广泛应用在语音识别等领域的鲍姆-威尔士算法。隐马尔可夫模型(HMM)已经被成功应用在工程领域,并取得了具有科学意义和应用价值的重要成果。
本文将西蒙斯大奖章基金的利器-隐马尔可夫模型应用到我国股市的预测中,通过对股票数据序列的模式识别来对大盘走势进行预测。
一、前言:从大奖章讲起
西蒙斯是被量化圈所广为追捧的量化之神,在全球金融危机的08年,大部分对冲基金都亏损背景下,其收益高达80%。
西蒙斯创办的文艺复兴科技公司拥有一群物理学家和数学家,这群人聚在一起到底搞出了什么赚钱利器?一直是外界所猜测。众说纷纭,而其中隐马尔科夫模型也由于一些原因被推举出来。
本文将隐马尔可夫模型应用到我国股市的预测中,通过对股票数据序列的模式识别来对大盘走势进行预测。
二、HMM范例及原理
先简单回顾一下马尔科夫链。马尔可夫链,是指数学中具有马尔可夫性质的离散事件随机过程。马尔科夫性用数学公式表示如下:

马尔科夫经典范例:
根据当前天气的情况来预测未来天气情况。一种办法就是假设每天的天气状态都只依赖于前一天的状态。以下展示了天气预测的马尔科夫模型状态转移图:
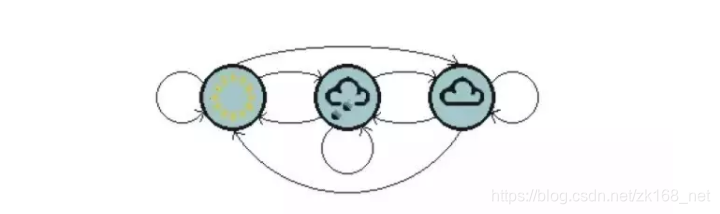
假设天气预测模型的状态转移矩阵如下:

这个矩阵表示,如果昨天是阴天,那么今天有25%的可能是晴天,12.5%的概率是阴天,62.5%的概率会下雨,很明显,矩阵中每一行的和都是1。
为了初始化这样一个系统,我们需要一个初始的概率向量:

这个向量表示第一天是晴天。到这里,我们就为上面的一阶马尔科夫过程定义了以下三个部分:
状态:晴天、阴天和下雨。
初始向量:定义系统在时间为0的时候的状态的概率。
状态转移矩阵:每种天气转换的概率。所有的能被这样描述的系统都是一个马尔科夫过程。
然而在某些情况下,马尔科夫过程不足以描述我们希望发现的模式。基于观测序列及隐含变量建立HMM模型,在模式识别上有一定优势。
HMM(隐马尔科夫)经典范例:
假设有3个不同的骰子。骰子1有6个面,称为D6,每个面对应数字出现的概率是1/6;骰子2有4个面,称为D4,每个面对应数字出现的概率是1/4;骰子3有8个面,称为D8,每个面对应数字出现的概率是1/8。

现在掷骰子10次,并假设得到这么一串数字:1 6 3 5 2 7 3 5 2 4,这串数字叫做观测序列。但是在隐马尔可夫模型中,我们不仅仅有这么一串可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是你用的骰子的序列。比如,隐含状态链有可能是:D4 D6 D8 D6 D4 D8 D6 D6 D6 D4。
一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态(骰子)之间存在转换概率。
在我们这个例子里,D6的下一个状态是D4,D6,D8的概率都是1/3。D4,D8的下一个状态是D4,D6,D8的转换概率也都一样是1/3。这样设定是为了最开始容易说清楚,但是我们其实是可以随意设定转换概率的。比如,我们可以这样定义,D6后面不能接D4,D6后面是D6的概率是0.9,是D8的概率是0.1。这样就是一个新的HMM。
可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个概率叫做输出概率。就我们的例子来说,六面骰子(D6)得到每个数字的输出概率都是1/6(假设骰子没被动过手脚)。

在上面的这些情况下,可以观察到的状态序列和隐藏的状态序列是概率相关的。于是我们可以将这种类型的过程建模为有一个隐藏的马尔科夫过程和一个与这个隐藏马尔科夫过程概率相关的并且可以观察到的状态集合,就是隐马尔可夫模型(Hidden Markov Model),简称HMM。
HMM的三个问题及算法:
对于股市我们也常常面临以下的问题:我们希望基于能观测到的有限的信息(股价、成交量及波动率)来预测我们所无法得知的股价背后驱动因素,乃至预测股价的涨跌原理,这个预测的建模过程与HMM不乏有许多相似之处。
HMM模型的构建,重点在于分别解决三种问题:
问题1:知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道每次掷出来的都是哪种骰子(隐含状态链)。
问题2:知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道掷出这个结果的概率。
问题3:知道骰子有几种(隐含状态数量),不知道每种骰子是什么(转换概率),观测到很多次掷骰子的结果(可见状态链),我想反推出每种骰子是什么(转换概率)。

三、HMM在股市预测中的应用
HMM在语音识别中的应用流程:
(1)首先,从输入的语音中提取相应的数字特征序列,并对模型进行训练,得到局部最优参数估计。HMM语音识别模型训练过程如下图:

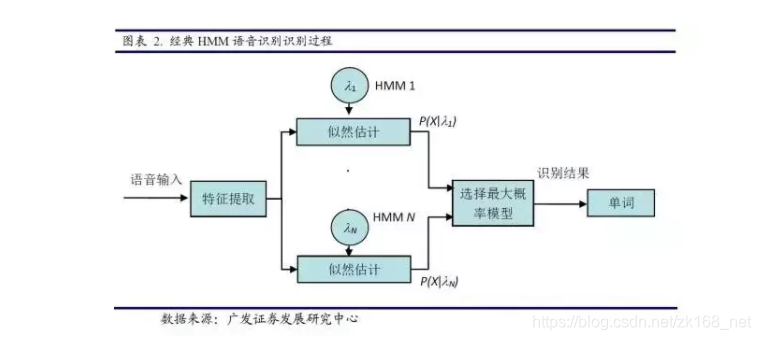
(2)其次,输入需要进行识别的语音,通过提取相应的数字特征序列,再运用向前-向后算法对各类模型进行似然估计,得到最大概率的模型输出,从而实现识别功能。HMM模型语音识别过程如下图:
基于HMM模式识别模型的股市走势预测:
(1)首先,按照事先分类,选取历史上属于同类走势的日期以及该日期之前若干个星期的股票数据,提取股票数据中某些特征指标(成交价格,成交量,等等)形成相应的序列作为模型的输入,并应用Baum-Welch算法对各类模型进行训练,训练过程如下图:

(2)其次, 根据训练好的HMM模型,选取若干个星期的股票特征指标(成交价格,成交量,等等)序列作为输入,应用向前-向后算法计算各个模型发生的概率,选取最大概率对应的模型,从而得到下一阶段股票走势的识别结果。识别过程如下图:

四、HMM策略实证结果
4.1、策略说明
择时指数:沪深300指数;
时间区间:2007/07/20至2016/09/09;
我们分别基于大盘的涨跌幅、换手率、成交金额以及每日的主动买卖盘金额等数据构造不同的观测序列变量如下:
X1: 股票日收益率;
X2: 资金日净流入占当日所有流动资金的比例;
X3: 日总流动资金环比;
X4: 标准化资金流,即:(日总流动资金-过去一年平均流动资金/过去一年流动资金波动率。
X5: 换手率日环比;
X6: 成交金额日环比;
X7: 标准化成交金额日。
从中选择不同的变量构造观测变量组合,并根据标的指数周涨跌情况将所有样本划分为两类(分别对应涨、跌),分别运用观测变量组合训练不同的HMM模型。
4.2、基于HMM的指数择时原理
基于不同类型(分涨、跌两类)样本数据分别训练得到对应的模型:HMM1和HMM2,根据最新观测变量输入之后的概率高低作为下周大盘涨跌的判断依据,对指数进行多空操作。此外,为了避免模型连续预测错误导致的策略较大亏损,我们加入了信号止损机制:当最近一次信号开仓起来,策略累计亏损达到某个阀值(如5%),则对当前仓位进行平仓,直到下一次出现相反信号再重新开仓
4.3、策略表现
(1)不考虑做空
若当信号为空时,指数空仓,不考虑做空,则在2007年07月20至2016年9月9日共450周间,共发出了62次买入信号和61次卖出信号,信号止损信号8次。平均每3.8周一次买卖信号。其中,预测结果准确为250周,准确率为56 %,策略累计收益率为183%,年化21.1%。

(2)考虑做空
若当信号为空时,指数开空仓,则在2007年07月20日至2016年9月9日共450周间,共发出了62次买入信号和61次卖出信号,信号止损信号16次,由于止损而空仓31周。平均每3.8周一次买卖信号。其中,预测结果准确为250周,准确率为56 %,策略累计收益率为899%,年化103.9%。

五、总结
5.1、研究意义和创新点
本报告首次提出将HMM模式识别模型引入到股票价格波动预测问题中,通过解决HMM模型中的学习问题和识别问题,建立了一个基于股票日收益率以及日资金流等变量的对股票指数择时模型,经实证检验,无论是预测准确率和择时策略收益,该模型都取得了比较不错的效果,具有相当的理论和现实意义。
由于HMM模型的相关算法相当成熟,且具有效率高,效果好以及易于通过已有的数据进行模型训练等特点,因此选用HMM模型进行股票波动模式识别不仅是一个较大的创新,更是一个值得探讨的选择。
5.2、模型的不足
(1)模型的预测准确率有待进一步提高;
(2)输入向量的选择是HMM模型的关键,本文仅针对股价、换手率以及资金流等构造输入变量,所能提取的股市信息存在局限。
-------------------------
拓展阅读:

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)