Pandas groupby apply 自定义apply
这篇文章介绍了自定义apply函数和groupby的联合用法。pandas中,groupby和apply一起使用,会减少很多操作。被groupby后的数据是一组一组的DataFrame,这些Frame会被apply函数处理。apply函数能够返回单一值、Series和DataFrame。这些返回结果能够被拼接成Series或者DataFrame,你只需要自定义一个合适的函数f并把它传给a...
这篇文章介绍了自定义apply函数和groupby的联合用法。
pandas中,groupby和apply一起使用,会减少很多操作。被groupby后的数据是一组一组的DataFrame,这些Frame会被apply函数处理。apply函数能够返回单一值、Series和DataFrame。 这些返回结果能够被拼接成Series或者DataFrame,你只需要自定义一个合适的函数f并把它传给apply就好。
1.数据
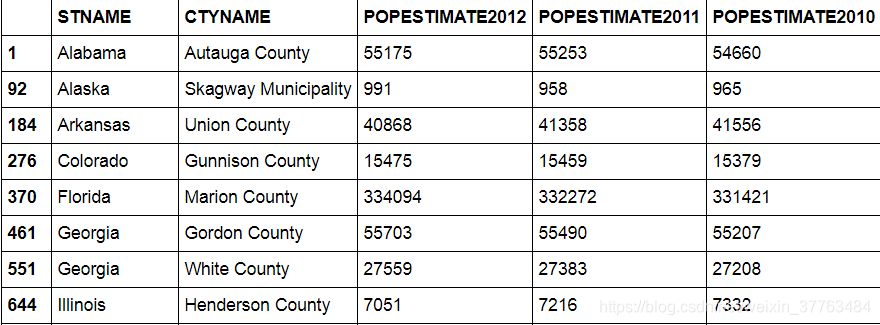
| STNAME CTYNAME POPESTIMATE2012 POPESTIMATE2011 POPESTIMATE2010 |
1 Alabama Autauga County 55175 55253 54660
92 Alaska Skagway Municipality 991 958 965
184 Arkansas Union County 40868 41358 41556
276 Colorado Gunnison County 15475 15459 15379
370 Florida Marion County 334094 332272 331421
461 Georgia Gordon County 55703 55490 55207
551 Georgia White County 27559 27383 27208
644 Illinois Henderson County 7051 7216 7332
735 Indiana Franklin County 22984 23000 23062
826 Iowa Clayton County 17926 17991 18081
917 Kansas Clark County 2179 2136 2201
1007 Kansas Wilson County 9124 9248 9404
1098 Kentucky Morgan County 13475 13721 13747
1189 Louisiana Vernon Parish 54162 52312 52742
1283 Michigan Hillsdale County 46283 46622 46619
1374 Minnesota Lac qui Parle County 7123 7236 7237
1465 Mississippi Leake County 23228 23282 23756
1556 Missouri Jackson County 677558 675373 675011
1647 Montana Judith Basin County 2023 2031 2064
1738 Nebraska Logan County 773 769 770
1832 New Mexico Curry County 50713 49688 48959
1924 North Carolina Alamance County 153822 152947 151581
2014 North Carolina Vance County 45053 45242 45302
2106 Ohio Geauga County 93859 93374 93418
2197 Oklahoma Harper County 3694 3708 3694
2289 Pennsylvania Blair County 127015 127192 127051
2381 South Carolina Hampton County 20727 20777 21052
2473 Tennessee Benton County 16359 16421 16492
2563 Tennessee White County 26086 26045 25836
2654 Texas Goliad County 7338 7208 7223
2744 Texas Nueces County 347926 343217 340314
2835 Utah Millard County 12524 12596 12514
2927 Virginia Nelson County 14823 15050 14992
3018 Washington Kitsap County 254764 254458 251723
2 返回单一值
检查每个州2012年人口多于100000的县的数量:
# 统计每个州在2012年人口大于100000的县的个数
def handle(a):
i=0
for item in a:
if item:
i+=1
return i
def larger_100000(df):
a=df["POPESTIMATE2012"]>100000
return handle(a)
group=data.groupby("STNAME")
result=group.apply(larger_100000)
result.head()
2 返回Series
统计每个州在2011、2012年人口大于100000的县的个数:
# 统计每个州在2011、2012年人口大于100000的县的个数
def handle(a):
i=0
for item in a:
if item:
i+=1
return i
def larger_100000(df):
a=df["POPESTIMATE2012"]>100000
b=df["POPESTIMATE2011"]>100000
return pd.Series([handle(a),handle(b)],index=["POPIN2012>100000","POPIN2011>100000"])
group=data.groupby("STNAME")
result=group.apply(larger_100000)
result.sort_values(by=["POPIN2012>100000","POPIN2011>100000"],ascending=False).head(5)
3 返回DataFrame
# 统计每个州在某一个年份的人口最多的三个县
def max_three_in(df,year=2012):
result=df.sort_values(by="POPESTIMATE"+str(year),ascending=False)[0:3]
return result[["CTYNAME","POPESTIMATE"+str(year)]]
result1=group.apply(max_three_in,2011)
result1.head(9)

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)