图像处理(2):Pytorch垃圾分类 ResNextWSL1000 分类模型预测
ResNext WSLAuthor: Facebook AIResNext models trained with billion scale weakly-supervised data.图1:使用不同规模和参数配置的ResNeXt-101模型在ImageNet和Instagram标记数据集的分类性能的比较何恺明团队新作ResNext:Instagram图片预训练,挑战ImageNe...
ResNext WSL
作者:沈福利 北京工业大学硕士学位,高级算法专家。产品和技术负责人,专注于NLP、图像、推荐系统
Author: Facebook AI
ResNext models trained with billion scale weakly-supervised data.
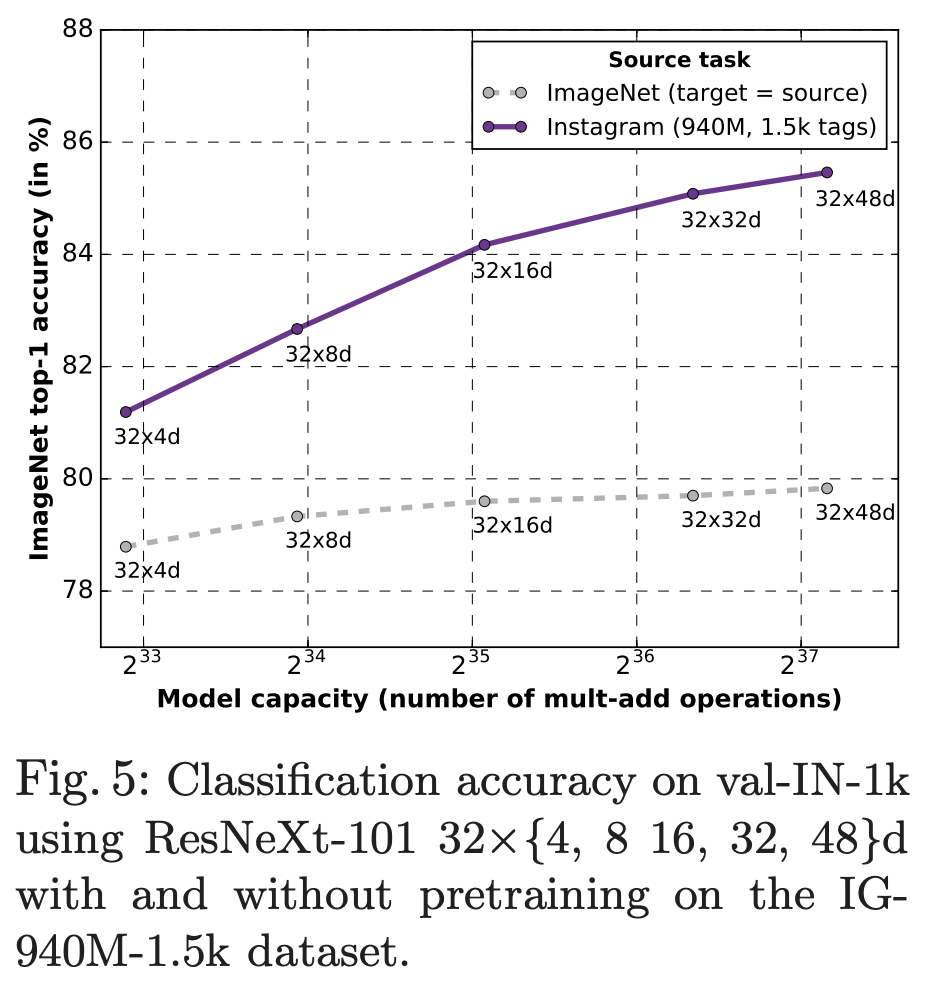
图1:使用不同规模和参数配置的ResNeXt-101模型在ImageNet和Instagram标记数据集的分类性能的比较
何恺明团队新作ResNext:Instagram图片预训练,挑战ImageNet新精度
8亿参数,刷新ImageNet纪录:何恺明团队开源最强ResNeXt预训练模型
resnext101_32x{4,8,16,32,48}d_wsl,其中wsl是弱监督学习。用Instagram上面的9.4亿张图做了 (弱监督) 预训练,用ImageNet做了微调。
ImageNet测试中,它的 (32×48d) 分类准确率达到85.4% (Top-1) ,打破了从前的纪录。
导入库
# 导入torch 库
import torch
import torch.nn as nn
from torchvision import transforms
# 导入 经调整后 facebookresearch_WSL_resnext 模型
## 'resnext50_32x4d', 'resnext101_32x8d', 'resnext101_32x16d_wsl'
import models
加载模型
# 加载模型,设置仅预测模式
model_ft = models.resnext101_32x16d_wsl()
r = model_ft.eval()
# 模型1000类
model_ft.fc
Linear(in_features=2048, out_features=1000, bias=True)
加载图片数据
All pre-trained models expect input images normalized in the same way,
i.e. mini-batches of 3-channel RGB images of shape (3 x H x W), where H and W are expected to be at least 224.
The images have to be loaded in to a range of [0, 1] and then normalized using mean = [0.485, 0.456, 0.406]
and std = [0.229, 0.224, 0.225].
Here’s a sample execution.
# sample execution (requires torchvision)
file_name ='images/yindu.jpg'
from PIL import Image
input_image = Image.open(file_name)
print(input_image)
print(input_image.size) # 尺寸大小:长=1546,宽1213
# 数据处理后,我们看看处理后图片
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示符号
plt.imshow(input_image)

图像归一化是计算机视觉、模式识别等领域广泛使用的一种技术。所谓图像归一化, 就是通过一系列变换, 将待处理的原始图像转换成相应的唯一标准形式(该标准形式图像对平移、旋转、缩放等仿射变换具有不变特性)
基于矩的图像归一化过程包括 4 个步骤 即坐标中心化、x-shearing 归一化、缩放归一化和旋转归一化。
图片数据预处理
preprocess = transforms.Compose([
# 1. 图像变换:重置图像分辨率,图片缩放256 * 256
transforms.Resize(256),
# 2. 裁剪: 中心裁剪 ,依据给定的size从中心裁剪
transforms.CenterCrop(224),
# 3. 将PIL Image或者 ndarray 转换为tensor,并且归一化至[0-1].注意事项:归一化至[0-1]是直接除以255
transforms.ToTensor(),
# 4. 对数据按通道进行标准化,即先减均值,再除以标准差
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),#图片归一化
])
input_tensor = preprocess(input_image)
print('input_tensor.shape = ',input_tensor.shape)
print('input_tensor = ',input_tensor)
input_tensor.shape = torch.Size([3, 224, 224])
input_tensor = tensor([[[ 0.8104, 0.9646, 1.0502, ..., 0.3994, 0.4166, 0.4337],
[ 0.7591, 0.9646, 1.0502, ..., 0.4337, 0.4337, 0.4508],
[ 0.7248, 0.9474, 1.0673, ..., 0.4166, 0.4337, 0.4337],
...,
[ 2.1119, 2.1290, 2.1290, ..., -0.2513, -0.2513, -0.3198],
[ 2.0948, 2.1119, 2.0948, ..., -0.2513, -0.1828, -0.2171],
[ 2.0777, 2.0948, 2.0948, ..., -0.3198, -0.1486, -0.1828]],
[[ 1.5357, 1.6933, 1.7808, ..., 1.0980, 1.1155, 1.1331],
[ 1.5007, 1.6758, 1.7808, ..., 1.1506, 1.1506, 1.1681],
[ 1.4307, 1.6583, 1.7633, ..., 1.1681, 1.1856, 1.1856],
...,
[ 2.4111, 2.4111, 2.4286, ..., 0.0126, 0.0126, -0.0574],
[ 2.4286, 2.4286, 2.4286, ..., 0.0126, 0.0826, 0.0476],
[ 2.4286, 2.4286, 2.4286, ..., -0.0574, 0.1176, 0.0826]],
[[ 2.1171, 2.2566, 2.3437, ..., 1.7163, 1.7337, 1.7337],
[ 2.0648, 2.2566, 2.3437, ..., 1.7511, 1.7685, 1.7685],
[ 2.0125, 2.2391, 2.3263, ..., 1.7685, 1.7860, 1.7860],
...,
[ 2.6226, 2.6226, 2.6400, ..., 0.2696, 0.2696, 0.1999],
[ 2.6400, 2.6400, 2.6400, ..., 0.2696, 0.3393, 0.3045],
[ 2.6226, 2.6400, 2.6400, ..., 0.1999, 0.3742, 0.3393]]])
# 转换模型需要数据格式
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
print('input_batch.shape = ',input_batch.shape)
print('input_batch = ',input_batch)
import matplotlib.pyplot as plt
%matplotlib inline
image_tmp = input_tensor.permute(1,2,0) #Changing from 3x224x224 to 224x224x3
print('image_tmp.matplotlib.shape = ',image_tmp.shape)
input_tensor = torch.clamp(input_tensor,0,1)
print('image_tmp.matplotlib.clamp.shape = ',image_tmp.shape)
plt.imshow(image_tmp)
input_batch.shape = torch.Size([1, 3, 224, 224])
input_batch = tensor([[[[ 0.8104, 0.9646, 1.0502, ..., 0.3994, 0.4166, 0.4337],
[ 0.7591, 0.9646, 1.0502, ..., 0.4337, 0.4337, 0.4508],
[ 0.7248, 0.9474, 1.0673, ..., 0.4166, 0.4337, 0.4337],
...,
[ 2.1119, 2.1290, 2.1290, ..., -0.2513, -0.2513, -0.3198],
[ 2.0948, 2.1119, 2.0948, ..., -0.2513, -0.1828, -0.2171],
[ 2.0777, 2.0948, 2.0948, ..., -0.3198, -0.1486, -0.1828]],
[[ 1.5357, 1.6933, 1.7808, ..., 1.0980, 1.1155, 1.1331],
[ 1.5007, 1.6758, 1.7808, ..., 1.1506, 1.1506, 1.1681],
[ 1.4307, 1.6583, 1.7633, ..., 1.1681, 1.1856, 1.1856],
...,
[ 2.4111, 2.4111, 2.4286, ..., 0.0126, 0.0126, -0.0574],
[ 2.4286, 2.4286, 2.4286, ..., 0.0126, 0.0826, 0.0476],
[ 2.4286, 2.4286, 2.4286, ..., -0.0574, 0.1176, 0.0826]],
[[ 2.1171, 2.2566, 2.3437, ..., 1.7163, 1.7337, 1.7337],
[ 2.0648, 2.2566, 2.3437, ..., 1.7511, 1.7685, 1.7685],
[ 2.0125, 2.2391, 2.3263, ..., 1.7685, 1.7860, 1.7860],
...,
[ 2.6226, 2.6226, 2.6400, ..., 0.2696, 0.2696, 0.1999],
[ 2.6400, 2.6400, 2.6400, ..., 0.2696, 0.3393, 0.3045],
[ 2.6226, 2.6400, 2.6400, ..., 0.1999, 0.3742, 0.3393]]]])
image_tmp.matplotlib.shape = torch.Size([224, 224, 3])
image_tmp.matplotlib.clamp.shape = torch.Size([224, 224, 3])

模型在线预测
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model_ft(input_batch)
# Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes
print(output[0].shape)
torch.Size([1000])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
result = torch.nn.functional.softmax(output[0], dim=0)
print(result.shape)
torch.Size([1000])
# 获取预测结果标签id,然后imagenet 标签库查看对应的标签名称
v_list = result.cpu().numpy().tolist()
v_max = 0
idx = 0
for i,v in enumerate(v_list):
if v>v_max:
v_max = v
idx = i
print('v_max = ',v_max)
print('idx = ',idx)
v_max = 0.3861195147037506
idx = 638
加载ImageNet 标签,然后获取结果
imagenet数据集类别标签和对应的英文中文对照表:data/ImageNet1k_label.txt
import codecs
ImageNet_dict = {}
for line in codecs.open('data/ImageNet1k_label.txt','r',encoding='utf-8'):
line = line.strip()
_id = line.split(":")[0]
_name = line.split(":")[1]
ImageNet_dict[int(_id)] = _name.replace('\xa0',"")
ImageNet_dict[idx]
" 'maillot',"
maillot 中文的意思是:紧身衣;女子游泳衣;紧身体操衣.

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)