

''' Created on 2017年7月23日 @author: weizhen ''' #导入库 from __future__ import division,print_function,absolute_import import tflearn import speech_data import tensorflow as tf #定义参数 #learning rate是在更新权重的时候用,太高可用很快 #但是loss大,太低较准但是很慢 learning_rate=0.0001 training_iters=300000#STEPS batch_size=64 width=20 #mfcc features height=80 #(max) length of utterance classes = 10 #digits #用speech_data.mfcc_batch_generator获取语音数据并处理成批次, #然后创建training和testing数据 batch=word_batch=speech_data.mfcc_batch_generator(batch_size) X,Y=next(batch) trainX,trainY=X,Y testX,testY=X,Y #overfit for now #4.建立模型 #speech recognition 是个many to many的问题 #所以用Recurrent NN #通常的RNN,它的输出结果是受整个网络的影响的 #而LSTM比RNN好的地方是,它能记住并且控制影响的点, #所以这里我们用LSTM #每一层到底需要多少个神经元是没有规定的,太少了的话预测效果不好 #太多了会overfitting,这里普遍取128 #为了减轻过拟合的影响,我们用dropout,它可以随机地关闭一些神经元, #这样网络就被迫选择其他路径,进而生成想对generalized模型 #接下来建立一个fully connected的层 #它可以使前一层的所有节点都连接过来,输出10类 #因为数字是0-9,激活函数用softmax,它可以把数字变换成概率 #最后用个regression层来输出唯一的类别,用adam优化器来使 #cross entropy损失达到最小 #Network building net=tflearn.input_data([None,width,height]) net=tflearn.lstm(net,128,dropout=0.8) net=tflearn.fully_connected(net,classes,activation='softmax') net=tflearn.regression(net,optimizer='adam',learning_rate=learning_rate,loss='categorical_crossentropy') #5.训练模型并预测 #然后用tflearn.DNN函数来初始化一下模型,接下来就可以训练并预测,最好再保存训练好的模型 #Traing ### add this "fix" for tensorflow version erros col=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES) for x in col: tf.add_to_collection(tf.GraphKeys.VARIABLES,x) model=tflearn.DNN(net,tensorboard_verbose=0) while 1: #training_iters model.fit(trainX, trainY, n_epoch=10, validation_set=(testX,testY), show_metric=True, batch_size=batch_size) _y=model.predict(X) model.save("tflearn.lstm.model") print(_y)
下面是训练的结果
Training Step: 3097 | total loss: [1m[32m1.51596[0m[0m | time: 1.059s [2K | Adam | epoch: 3097 | loss: 1.51596 - acc: 0.6324 | val_loss: 0.36655 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3098 | total loss: [1m[32m1.64602[0m[0m | time: 1.050s [2K | Adam | epoch: 3098 | loss: 1.64602 - acc: 0.5801 | val_loss: 0.36642 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3099 | total loss: [1m[32m1.54328[0m[0m | time: 1.052s [2K | Adam | epoch: 3099 | loss: 1.54328 - acc: 0.6206 | val_loss: 0.36673 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3100 | total loss: [1m[32m1.65763[0m[0m | time: 1.044s [2K | Adam | epoch: 3100 | loss: 1.65763 - acc: 0.5741 | val_loss: 0.36645 - val_acc: 1.0000 -- iter: 64/64 -- --------------------------------- Run id: E1W1VX Log directory: /tmp/tflearn_logs/ --------------------------------- Training samples: 64 Validation samples: 64 -- Training Step: 3101 | total loss: [1m[32m1.56009[0m[0m | time: 1.328s [2K | Adam | epoch: 3101 | loss: 1.56009 - acc: 0.6167 | val_loss: 0.36696 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3102 | total loss: [1m[32m1.68916[0m[0m | time: 1.034s [2K | Adam | epoch: 3102 | loss: 1.68916 - acc: 0.5660 | val_loss: 0.36689 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3103 | total loss: [1m[32m1.58796[0m[0m | time: 1.044s [2K | Adam | epoch: 3103 | loss: 1.58796 - acc: 0.6078 | val_loss: 0.36627 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3104 | total loss: [1m[32m1.49236[0m[0m | time: 1.055s [2K | Adam | epoch: 3104 | loss: 1.49236 - acc: 0.6470 | val_loss: 0.36599 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3105 | total loss: [1m[32m1.60916[0m[0m | time: 1.028s [2K | Adam | epoch: 3105 | loss: 1.60916 - acc: 0.5995 | val_loss: 0.36535 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3106 | total loss: [1m[32m1.51083[0m[0m | time: 1.049s [2K | Adam | epoch: 3106 | loss: 1.51083 - acc: 0.6396 | val_loss: 0.36534 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3107 | total loss: [1m[32m1.63413[0m[0m | time: 1.066s [2K | Adam | epoch: 3107 | loss: 1.63413 - acc: 0.5865 | val_loss: 0.36566 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3108 | total loss: [1m[32m1.74167[0m[0m | time: 1.042s [2K | Adam | epoch: 3108 | loss: 1.74167 - acc: 0.5373 | val_loss: 0.36556 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3109 | total loss: [1m[32m1.63324[0m[0m | time: 1.051s [2K | Adam | epoch: 3109 | loss: 1.63324 - acc: 0.5835 | val_loss: 0.36557 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3110 | total loss: [1m[32m1.75479[0m[0m | time: 1.042s [2K | Adam | epoch: 3110 | loss: 1.75479 - acc: 0.5377 | val_loss: 0.36524 - val_acc: 1.0000 -- iter: 64/64 -- --------------------------------- Run id: 93CFSE Log directory: /tmp/tflearn_logs/ --------------------------------- Training samples: 64 Validation samples: 64 -- Training Step: 3111 | total loss: [1m[32m1.64290[0m[0m | time: 1.320s [2K | Adam | epoch: 3111 | loss: 1.64290 - acc: 0.5839 | val_loss: 0.36560 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3112 | total loss: [1m[32m1.76515[0m[0m | time: 1.029s [2K | Adam | epoch: 3112 | loss: 1.76515 - acc: 0.5349 | val_loss: 0.36552 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3113 | total loss: [1m[32m1.65166[0m[0m | time: 1.050s [2K | Adam | epoch: 3113 | loss: 1.65166 - acc: 0.5814 | val_loss: 0.36609 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3114 | total loss: [1m[32m1.76346[0m[0m | time: 1.062s [2K | Adam | epoch: 3114 | loss: 1.76346 - acc: 0.5342 | val_loss: 0.36636 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3115 | total loss: [1m[32m1.65255[0m[0m | time: 1.042s [2K | Adam | epoch: 3115 | loss: 1.65255 - acc: 0.5808 | val_loss: 0.36636 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3116 | total loss: [1m[32m1.55663[0m[0m | time: 1.042s [2K | Adam | epoch: 3116 | loss: 1.55663 - acc: 0.6227 | val_loss: 0.36689 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3117 | total loss: [1m[32m1.67928[0m[0m | time: 1.051s [2K | Adam | epoch: 3117 | loss: 1.67928 - acc: 0.5729 | val_loss: 0.36726 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3118 | total loss: [1m[32m1.78375[0m[0m | time: 1.043s [2K | Adam | epoch: 3118 | loss: 1.78375 - acc: 0.5266 | val_loss: 0.36714 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3119 | total loss: [1m[32m1.67364[0m[0m | time: 1.041s [2K | Adam | epoch: 3119 | loss: 1.67364 - acc: 0.5724 | val_loss: 0.36725 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3120 | total loss: [1m[32m1.79457[0m[0m | time: 1.044s [2K | Adam | epoch: 3120 | loss: 1.79457 - acc: 0.5276 | val_loss: 0.36694 - val_acc: 1.0000 -- iter: 64/64 -- --------------------------------- Run id: YE812Z Log directory: /tmp/tflearn_logs/ --------------------------------- Training samples: 64 Validation samples: 64 -- Training Step: 3121 | total loss: [1m[32m1.68830[0m[0m | time: 1.351s [2K | Adam | epoch: 3121 | loss: 1.68830 - acc: 0.5686 | val_loss: 0.36691 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3122 | total loss: [1m[32m1.79857[0m[0m | time: 1.022s [2K | Adam | epoch: 3122 | loss: 1.79857 - acc: 0.5227 | val_loss: 0.36642 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3123 | total loss: [1m[32m1.68557[0m[0m | time: 1.071s [2K | Adam | epoch: 3123 | loss: 1.68557 - acc: 0.5673 | val_loss: 0.36519 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3124 | total loss: [1m[32m1.58528[0m[0m | time: 1.042s [2K | Adam | epoch: 3124 | loss: 1.58528 - acc: 0.6106 | val_loss: 0.36366 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3125 | total loss: [1m[32m1.49228[0m[0m | time: 1.042s [2K | Adam | epoch: 3125 | loss: 1.49228 - acc: 0.6495 | val_loss: 0.36180 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3126 | total loss: [1m[32m1.41012[0m[0m | time: 1.052s [2K | Adam | epoch: 3126 | loss: 1.41012 - acc: 0.6846 | val_loss: 0.36061 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3127 | total loss: [1m[32m1.55866[0m[0m | time: 1.023s [2K | Adam | epoch: 3127 | loss: 1.55866 - acc: 0.6286 | val_loss: 0.35908 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3128 | total loss: [1m[32m1.46943[0m[0m | time: 1.044s [2K | Adam | epoch: 3128 | loss: 1.46943 - acc: 0.6657 | val_loss: 0.35735 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3129 | total loss: [1m[32m1.39050[0m[0m | time: 1.042s [2K | Adam | epoch: 3129 | loss: 1.39050 - acc: 0.6992 | val_loss: 0.35632 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3130 | total loss: [1m[32m1.54006[0m[0m | time: 1.043s [2K | Adam | epoch: 3130 | loss: 1.54006 - acc: 0.6371 | val_loss: 0.35513 - val_acc: 1.0000 -- iter: 64/64 -- --------------------------------- Run id: YGRXY5 Log directory: /tmp/tflearn_logs/ --------------------------------- Training samples: 64 Validation samples: 64 -- Training Step: 3131 | total loss: [1m[32m1.45402[0m[0m | time: 1.336s [2K | Adam | epoch: 3131 | loss: 1.45402 - acc: 0.6702 | val_loss: 0.35442 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3132 | total loss: [1m[32m1.59202[0m[0m | time: 1.029s [2K | Adam | epoch: 3132 | loss: 1.59202 - acc: 0.6110 | val_loss: 0.35325 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3133 | total loss: [1m[32m1.50035[0m[0m | time: 1.070s [2K | Adam | epoch: 3133 | loss: 1.50035 - acc: 0.6499 | val_loss: 0.35195 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3134 | total loss: [1m[32m1.41417[0m[0m | time: 1.042s [2K | Adam | epoch: 3134 | loss: 1.41417 - acc: 0.6849 | val_loss: 0.35042 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3135 | total loss: [1m[32m1.34060[0m[0m | time: 1.037s [2K | Adam | epoch: 3135 | loss: 1.34060 - acc: 0.7149 | val_loss: 0.34937 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3136 | total loss: [1m[32m1.47476[0m[0m | time: 1.039s [2K | Adam | epoch: 3136 | loss: 1.47476 - acc: 0.6574 | val_loss: 0.34826 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3137 | total loss: [1m[32m1.38535[0m[0m | time: 1.053s [2K | Adam | epoch: 3137 | loss: 1.38535 - acc: 0.6917 | val_loss: 0.34739 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3138 | total loss: [1m[32m1.51673[0m[0m | time: 1.063s [2K | Adam | epoch: 3138 | loss: 1.51673 - acc: 0.6413 | val_loss: 0.34637 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3139 | total loss: [1m[32m1.42892[0m[0m | time: 1.042s [2K | Adam | epoch: 3139 | loss: 1.42892 - acc: 0.6756 | val_loss: 0.34570 - val_acc: 1.0000 -- iter: 64/64 -- Training Step: 3140 | total loss: [1m[32m1.58217[0m[0m | time: 1.052s [2K | Adam | epoch: 3140 | loss: 1.58217 - acc: 0.6112 | val_loss: 0.34494 - val_acc: 1.0000 -- iter: 64/64 -- ---------------------------------
这里边有一个死循环,具体怎么回事我也不太清楚。
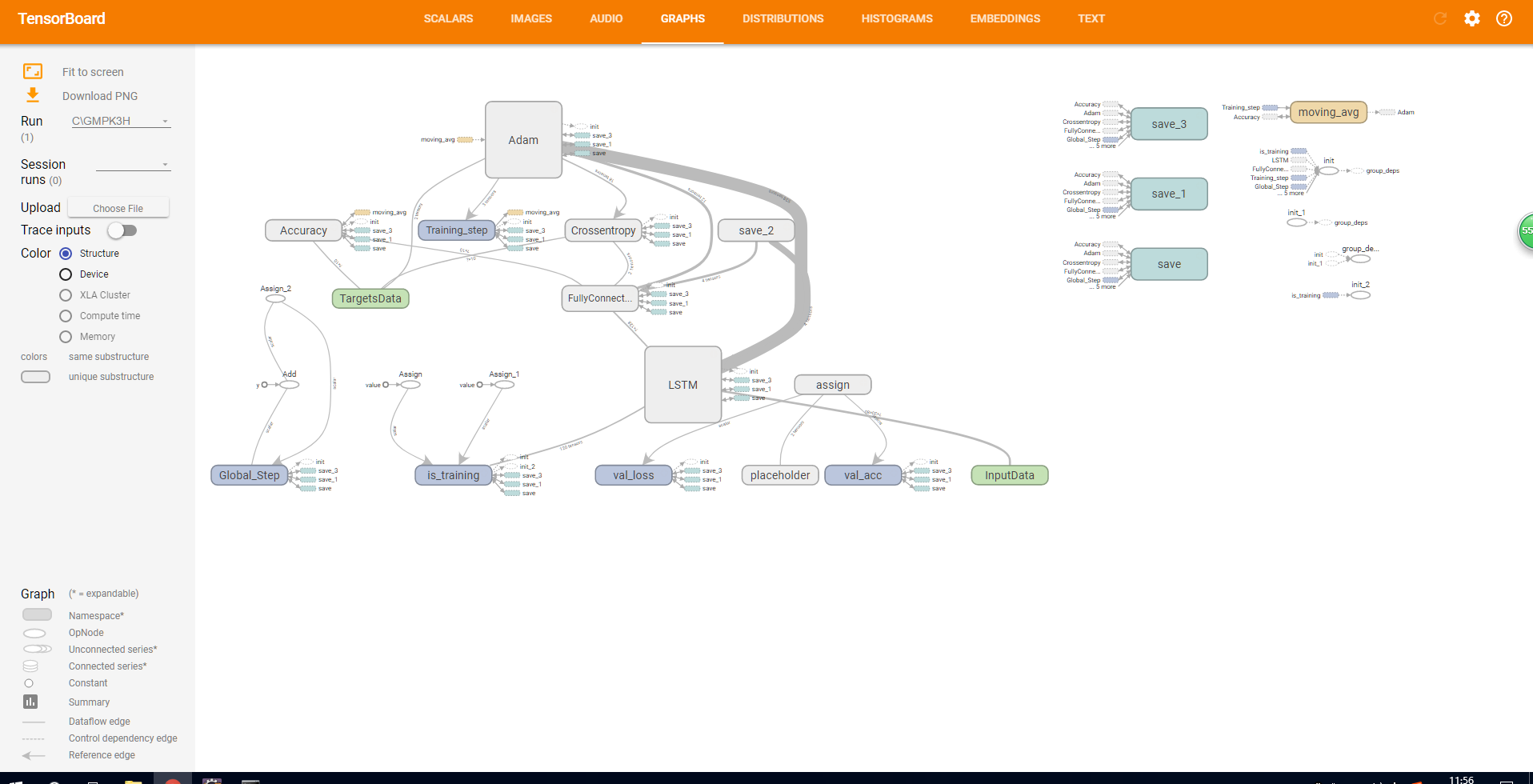
下边是可视化训练,展示训练的图像







 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)