声网 Agora 一站式智能语音识别方案:内容审核,快速接入
视频直播、语音聊天、音乐社交,这些与“声音”有关的社交场景在近两年来越来越热,也吸引了很多内容创作者和用户。不过,与之相关的语音内容审核一直是令很多平台头痛的问题。这也让...
视频直播、语音聊天、音乐社交,这些与“声音”有关的社交场景在近两年来越来越热,也吸引了很多内容创作者和用户。不过,与之相关的语音内容审核一直是令很多平台头痛的问题。这也让那些“每天听 4000 条语音”的声音鉴黄师上了头条。而现在,市场上已经有一些厂商开始提供智能语音鉴黄服务了,大幅减轻了人工鉴黄的工作量。
不过,对于社交产品团队来讲,现有的语音内容审核+实时音视频服务,部署、调试、运维的成本高,而且很多方案对有背景音乐、噪声的音频识别效果差。为了解决这个问题,我们正式推出声网 Agora 一站式智能语音识别方案。
现有的方案都是如何实现的呢?
一般来讲,一个社交产品需要对接三种厂商:CDN厂商,用来推流、拉流,实现普通的直播;RTC 厂商,用来实现低延时的实时互动直播;内容审核厂商,通过 AI、人工进行审核。接入的架构基本如下图所示,可简单概括为三步:
1. 内容经过转码或直接推流至 CDN;
2. 内容审核厂商从 CDN 拉流,然后进行 AI 、人工内容审核;
3. 完成审核后,传回给服务器端。
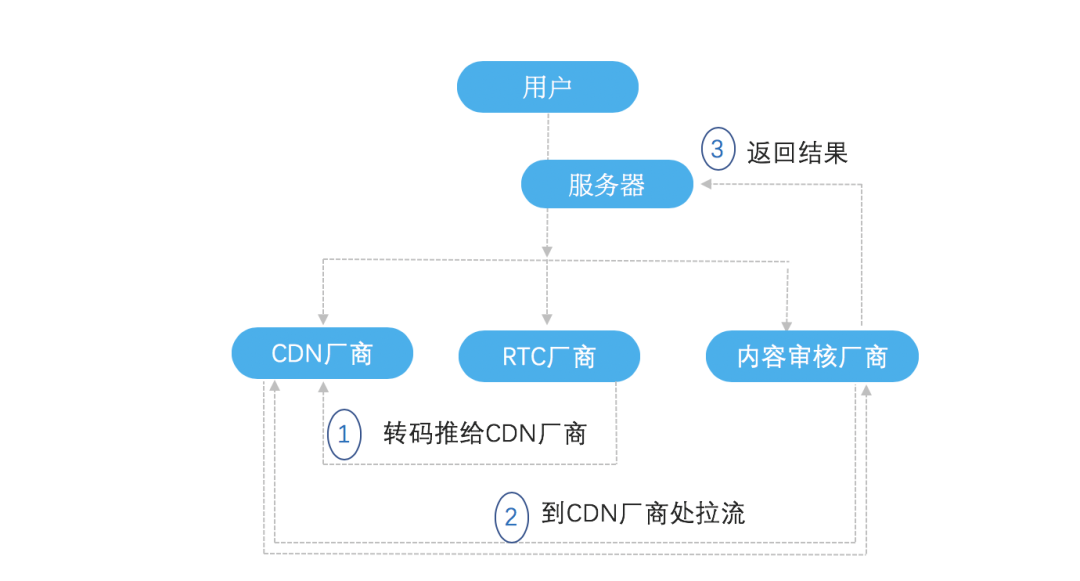 图:传统的实时音视频内容审核流程
图:传统的实时音视频内容审核流程
这种旧方式带来的问题显而易见。首先,开发者需要对接三个厂商,要进行多次部署、调试,其中有很多调试的成本与风险。而且,当 CDN 出现故障时,需要较长时间来排查问题。另外,在这个过程中,开发者还需要支付额外的拉流成本。
另一方面,目前的方案还需要解决噪声问题。因为音频社交有很多种场景,比如语音FM、语音聊天室、音乐社交、娱乐直播,这些场景常常伴有环境噪声和背景音乐,会影响现有内容审核方案的识别率。
声网Agora 一站式智能语音识别方案
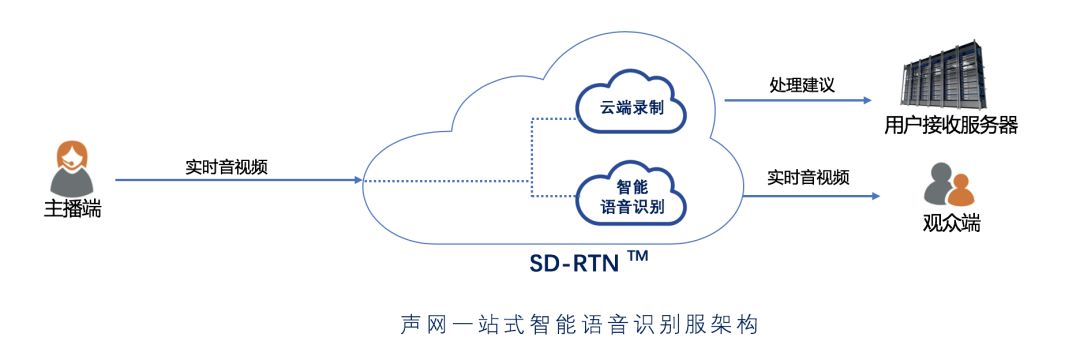
声网现已提供业界独有的一站式智能语音识别方案。如上图架构所示,开发者只需要在应用中集成声网 Agora SDK,即可让音频在 Agora SD-RTN™ 网络中实时传输的过程中完成语音内容识别与审核。我们在原有的实时语音互动直播的基础上,整合了业界 Top 3 语音识别服务。同时,基于声网的 AI 音频降噪引擎,来提高音频质量,优化语音识别效果。
语音识别的流程如下图所示。首先通过声网独家研发的 AI 音频降噪引擎消除背景音,优化音频质量,让语音更加清晰。我们在网络电台、语音交友等互联网平台听到的语音音频通常有两类,一类是普通的语音,另一类是非文字的声音,如娇喘和ASMR,后者是不存在任何语义的。所以我们会通过不同的模块来检测,将语音转化为文字通过内容安全引擎进一步过滤,结合“多意义上下文短文本垃圾检测”、“Deep Learning 垃圾检测”、“规则引擎”和“分类器”等模块,过滤掉音频中涉政、涉黄(包括娇喘、ASMR)、暴恐、辱骂等违规内容。人工审核团队可以通过Web端后台,对机器审核的结果进行抽查和复审,不断优化机器审核的准确率。这一过程可以大幅降人工审核成本,提升效率。
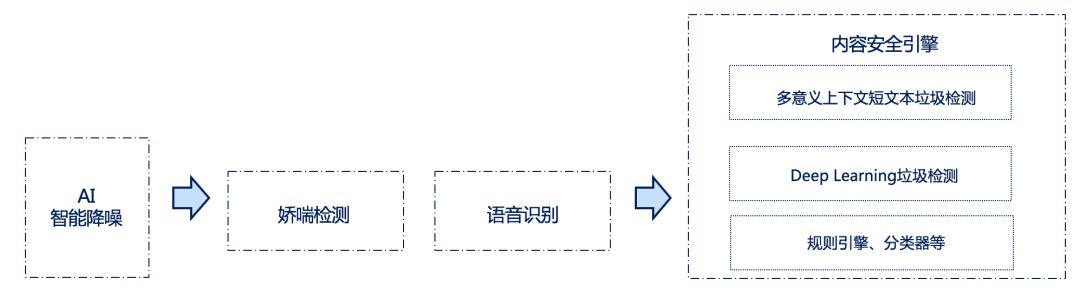
目前该解决方案可检测出广告、涉黄、涉政、暴恐、谩骂等违规内容,适用于视频直播、语音聊天室、娱乐直播、语音 FM、音乐社交等实时音视频社交互动场景。
声网Agora一站式智能语音识别方案优势包括:
1
调用 RESTful API,一站式接入
声网 Agora 目前提供了实时音频通话 SDK。在应用中集成 Agora SDK 后,开发者可以通过调用 RESTful API,即可为自己的应用增加语音内容审核服务。相比传统内容审核方案,声网方案可以节省开发时间、服务器等接入成本。
2
AI 降噪,识别率更高
面对语音识别中常见的噪声、背景音乐等音质问题。我们会通过声网 AI 音频降噪引擎对音频进行优化,以提升语音的识别率。与此同时,用户的语音、音频体验也会得到提升。在今年的 RTC 2019 实时互联网大会上,我们还将进一步分享 AI 音频降噪背后的技术实践,敬请期待。
3
语音交互低延时
声网 SDK 实现了全球端到端76ms 的实时音视频低延时传输。声网Agora SD-RTN™ 实时通信网络采用私有 UDP 协议进行传输,基于软件定义优化路由选择最优传输路径,自动规避网络拥塞和骨干网络故障带来的影响。在能保证低延时传输的同时,声网Agora SDK还支持 48kHz 高音质语音。

加入交流群
如果你希望了解更多关于声网一站式智能语音识别方案的细节,欢迎扫码申请加群,好友申请请备注「语音识别」。


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)