
交叉验证以及scikit-learn中的cross_val_score详解
K折验证交叉验证总的来说,交叉验证既可以解决数据集的数据量不够大问题,也可以解决参数调优的问题。这块主要有三种方式:简单交叉验证(HoldOut检验)、k折交叉验证(k-fold交叉验证)、自助法。该文仅针对k折交叉验证做详解。简单交叉验证方法:将原始数据集随机划分成训练集和验证集两部分。比如说,将样本按照70%~30%的比例分成两部分,70%的样本用于训练模型;30%的样本用于模型验证。...
K折验证交叉验证
总的来说,交叉验证既可以解决数据集的数据量不够大问题,也可以解决参数调优的问题。这块主要有三种方式:简单交叉验证(HoldOut检验)、k折交叉验证(k-fold交叉验证)、自助法。该文仅针对k折交叉验证做详解。
简单交叉验证
方法:将原始数据集随机划分成训练集和验证集两部分。比如说,将样本按照70%~30%的比例分成两部分,70%的样本用于训练模型;30%的样本用于模型验证。
缺点:(1)数据都只被所用了一次,没有被充分利用
(2)在验证集上计算出来的最后的评估指标与原始分组有很大关系。

k折交叉验证
为了解决简单交叉验证的不足,提出k-fold交叉验证。
1、首先,将全部样本划分成k个大小相等的样本子集;
2、依次遍历这k个子集,每次把当前子集作为验证集,其余所有样本作为训练集,进行模型的训练和评估;
3、最后把k次评估指标的平均值作为最终的评估指标。在实际实验中,k通常取10.
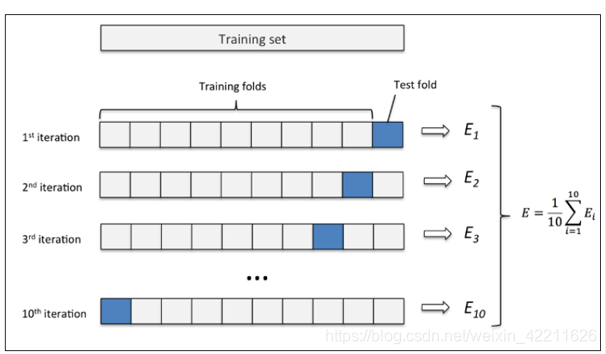
举个例子:这里取k=10,如下图所示:
(1)先将原数据集分成10份
(2)每一将其中的一份作为测试集,剩下的9个(k-1)个作为训练集
此时训练集就变成了k * D(D表示每一份中包含的数据样本数)

(3)最后计算k次求得的分类率的平均值,作为该模型或者假设函数的真实分类率
 交叉验证的方式,要简单于数学理解,而且具有说服性。需要谨记一点,当样本总数过大,若使用 留一法时间开销极大。
交叉验证的方式,要简单于数学理解,而且具有说服性。需要谨记一点,当样本总数过大,若使用 留一法时间开销极大。
具体API和参数下面有说明。
自主法
自助法是基于自助采样法的检验方法。对于总数为n的样本合集,进行n次有放回的随机抽样,得到大小为n的训练集。
n次采样过程中,有的样本会被重复采样,有的样本没有被抽出过,将这些没有被抽出的样本作为验证集,进行模型验证。
cross_val_score参数设置
sklearn.model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=’warn’, n_jobs=None, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’, error_score=’raise-deprecating’)
参数:
estimator: 需要使用交叉验证的算法
X: 输入样本数据
y: 样本标签
groups: 将数据集分割为训练/测试集时使用的样本的组标签(一般用不到)
scoring: 交叉验证最重要的就是他的验证方式,选择不同的评价方法,会产生不同的评价结果。具体可用哪些评价指标,官方已给出详细解释,链接:https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
具体如下:
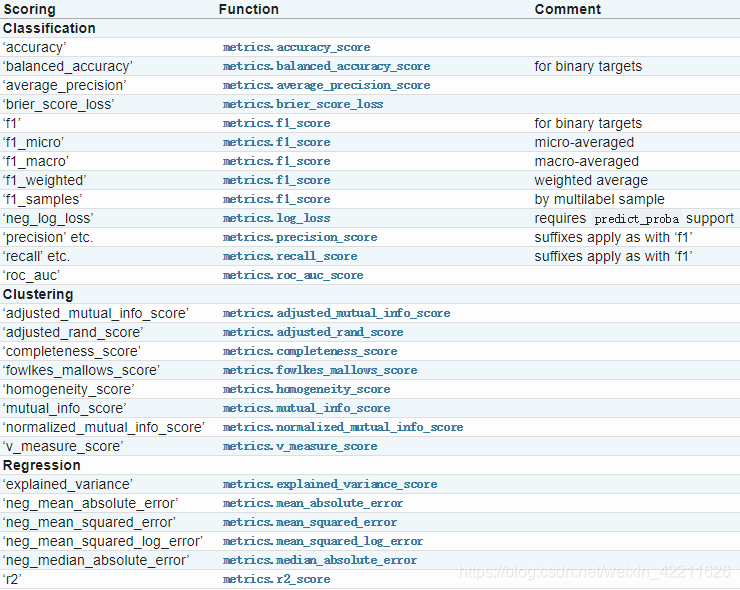
(具体的可以看这篇文章:https://blog.csdn.net/marsjhao/article/details/78678276)
cv: 交叉验证折数或可迭代的次数
n_jobs: 同时工作的cpu个数(-1代表全部)
verbose: 详细程度
fit_params: 传递给估计器(验证算法)的拟合方法的参数
pre_dispatch: 控制并行执行期间调度的作业数量。减少这个数量对于避免在CPU发送更多作业时CPU内存消耗的扩大是有用的。该参数可以是:
- 没有,在这种情况下,所有的工作立即创建并产生。将其用于轻量级和快速运行的作业,以避免由于按需产生作业而导致延迟
- 一个int,给出所产生的总工作的确切数量
- 一个字符串,给出一个表达式作为n_jobs的函数,如’2 * n_jobs
error_score: 如果在估计器拟合中发生错误,要分配给该分数的值(一般不需要指定)
cross_var_score使用方法
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsRegressor
import matplotlib.pylab as plt
train_data = pd.read_csv("E:/competitions/kaggle/House Price/train.csv")
X = pd.DataFrame(train_data["GrLivArea"].fillna(0))
y = train_data["SalePrice"]
score = []
alphas = []
for alpha in range(1,100,1):
alphas.append(alpha)
rdg = KNeighborsRegressor(alpha)
sc = np.sqrt( -cross_val_score(rdg,X,y,scoring = "neg_mean_squared_error", cv = 10))
score.append(sc.mean())
plt.plot(alphas,score)
plt.show()
这里使用了neg_mean_squared_error作为评分,画出损失——alpha的关系图如下:
 由上图可以看到,在alpha = 23的时候,其损失是最小的。这样便完成了选择参数的任务。
由上图可以看到,在alpha = 23的时候,其损失是最小的。这样便完成了选择参数的任务。

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 86
86 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)