- @yanzongshuai
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
stream->oldest_buffer_index处开始取内存数据页(前面已经发起了一个异步批量IO,已经讲数据页pin住了),ios[oldest_io_index].buffer_index == oldest_buffer_index时表示该页所处的批次IO还未完成,则等待IO完成。IO 接口,libaio仅支持直接 IO(O_DIRECT,绕过页缓存),不适合依赖页缓存的场景(如普通文
可以通过硬件或软件实现,基于硬件的预取通常是通过在处理器中具有专用硬件机制来实现的,该机制监视执行程序请求的指令或数据流,根据该流识别程序可能需要的接下来的几个元素,并预取到处理器的缓存中。反向分支是指目标地址低于其自身地址的分支。这种技术可以帮助提高循环的预测精度,循环通常是反向分支,并且更常被采用。可执行的微操作,并放到微操作缓存中,以便后面不必每次都解码。指令解码位置时,问下分支预测器,预测
PostgreSQL透明数据加密Cybertec为PG提供了一个透明数据加密(TDE)的补丁。是目前唯一支持透明加密数据(集群)级的实现,独立于操作系统或文件系统加密。透明数据加密如何工作...
GreenPlum(GPDB)是一款基于PostgreSQL(PgSQL)的开源分布式数据库。目前GPDB7已发布beta4,PgSQL内核支持到了12.12,但PgSQL优秀内核特性比如并行查询仍旧不支持。经查询PgSQL中并行代码已存在于GPDB中,但执行计划生成这块却不支持。这就比较可惜了。现在有款国产分布式数据库CloudberryDB基于GPDB,继承了GPDB优秀特性,并兼容PgSQL
1、磁盘数据格式2、代码分析//磁盘头初始化函数ssd_device_header *ssd_init_header(as_namespace *ns){//header的大小是1Mssd_device_header *h = cf_valloc(SSD_DEFAULT_HEADER_LENGTH);if (! h) {return 0;}memset(h, 0,
2023年4月7-8日,数据技术嘉年华给我们带了一场数据库行业盛宴。重点关注下向量化引擎的技术实现原理和创新应用点。1、MogDB基于openGauss内核在Copy导入优化方面使用了SIMD指令并行解析,能够提高导入性能10%-20%。SIMD指令优化方面同样可以用到分析型数据库中,比如向量化执行引擎。openGauss本身已实现向量化执行引擎,将执行器以行执行的模式改造成了以batch执行的批
openGauss-向量化执行引擎系列-VecUnique算子openGauss实现了向量化执行引擎,达到算子级别的并行。也就是说在执行器火山模型基础上,一次处理一批数据,而不是一次一个元组。这样可以充分利用SIMD指令进行优化,达到指令级别并行。前期我们介绍了PgSQL Unique算子的实现机制,本文接着介绍openGauss是如何实现Unique算子向量化的。简单来说,openGauss的V
openGauss-向量化执行引擎-索引扫描CStoreIndexScanopenGauss实现了向量化执行引擎,达到算子级别的并行。也就是说在执行器火山模型基础上,一次处理一批数据,而不是一次一个元组。这样可以充分利用SIMD指令进行优化,达到指令级别并行。本文关注索引扫描算子CStoreIndexScan,并以btree索引为例。1、Btree索引openGauss基于PostgreSQL,b
openGauss - 内核原理 - BatchStore和Batchsortstate为什么仅ForwardScanDirection取数据openGauss的普通执行引起从Tuplestorestate(物化)和Tuplesortstate(排序)取数据时,会有方向,即ForwardScanDirection:从前向后依次取;BackwardScanDirection:从后向前依次取。但是,在
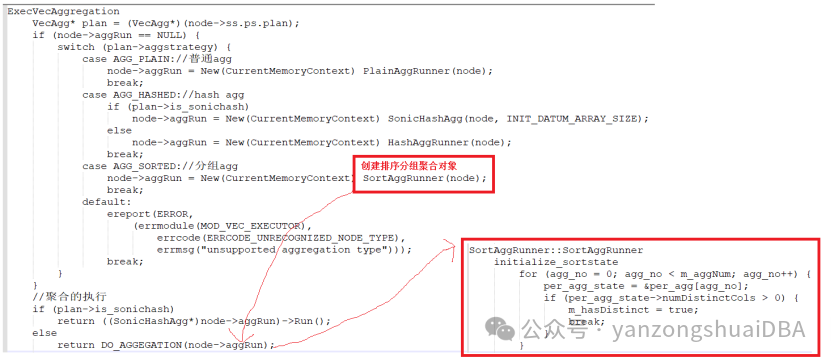
openGauss - 向量化执行引擎 - distinct分组聚合的实现openGauss向量化执行引擎中分组聚合有两种实现方式:排序和hash。本文介绍排序实现机制下的distinct分组聚合如何实现。分组聚合也分为两种使用方式:普通group by和grouping sets等分组集,其中普通group by就是每次查询生成一个分组的聚合;而grouping sets、cube或者rollu