




- @weixin_49475940
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
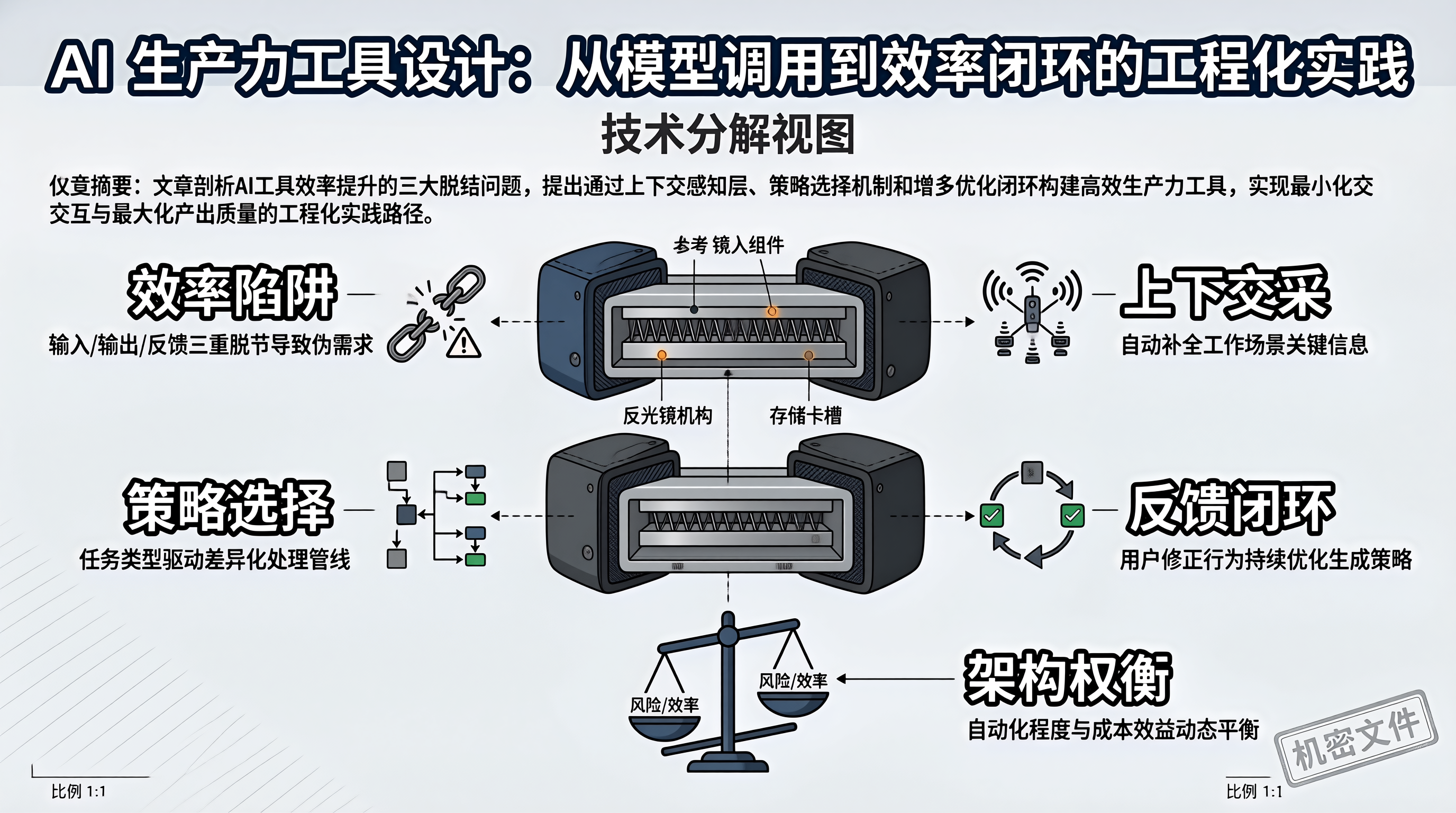
AI 生产力工具的核心竞争力,在于最小化人机交互次数、最大化单次交互的产出质量。落地路线如下:第一,构建上下文感知层。自动采集用户当前的工作环境信息,包括文件内容、项目结构、操作历史和偏好配置。用户只需要提供最少的必要信息,工具负责补全上下文。第二,实施策略选择机制。不同任务类型使用不同的上下文范围和 Prompt 模板。代码补全用局部上下文,文档生成用全局结构,重构建议用依赖分析。避免所有任务都
优化资源加载和缓存减少渲染阻塞优化JavaScript执行监控性能指标技术应当有温度,更快的应用能提升用户体验。
独立产品智能化的核心挑战不在于模型调用本身,而在于围绕 LLM 构建一套可控、可观测、可降级的工程体系。Prompt 工程是质量的关键杠杆,上下文窗口管理是稳定性的基础保障,流式响应是用户体验的底线要求,成本控制是商业可持续的必要条件。独立开发者应在 Demo 阶段就建立完整的接入架构,而非在上线后修补。将 LLM 视为"需要工程化约束的组件"而非"即插即用的黑盒",才能让 AI 能力真正为产品创
独立产品智能化的核心挑战不在于模型调用本身,而在于围绕 LLM 构建一套可控、可观测、可降级的工程体系。Prompt 工程是质量的关键杠杆,上下文窗口管理是稳定性的基础保障,流式响应是用户体验的底线要求,成本控制是商业可持续的必要条件。独立开发者应在 Demo 阶段就建立完整的接入架构,而非在上线后修补。将 LLM 视为"需要工程化约束的组件"而非"即插即用的黑盒",才能让 AI 能力真正为产品创
AI 交互体验优化的核心是弥合技术能力与用户感知之间的鸿沟。感知层通过流式渲染和思考状态可视化消除等待焦虑,信任层通过置信度标注和来源引用建立输出可信度,效率层通过意图预测和快捷指令降低交互摩擦。但优化存在边界:动画不应干扰内容阅读,标注不应增加认知负荷,预测不应侵入用户控制。AI 交互的最佳实践是"辅助而非替代"——在用户需要时提供帮助,在用户控制时保持克制,让 AI 的强大能力以优雅的方式融入
安全实践重要程度说明httpOnly Cookie优先高从根源防范XSS窃取Token有效期控制高Access Token 1h内,Refresh Token动态轮换刷新令牌轮换高一旦使用旧refresh token,吊销全部令牌CORS白名单中明确允许的跨域来源Token加密存储中localStorage加密后再存储多来源提取Token中Cookie/Header多种方式兼容SameSite策略
优势说明轻量级原生HTTP协议,无需额外协议握手自动重连EventSource内置断线重连机制单工推送完美匹配AI流式输出的单向场景浏览器兼容除IE外全部现代浏览器支持资源节约相比WebSocket节省服务端连接资源SSE是AI智能客服打字机效果的最佳技术选型。它利用HTTP长连接实现服务端到客户端的单向流式推送,配合Fetch API的ReadableStream可以实现更精细的控制。
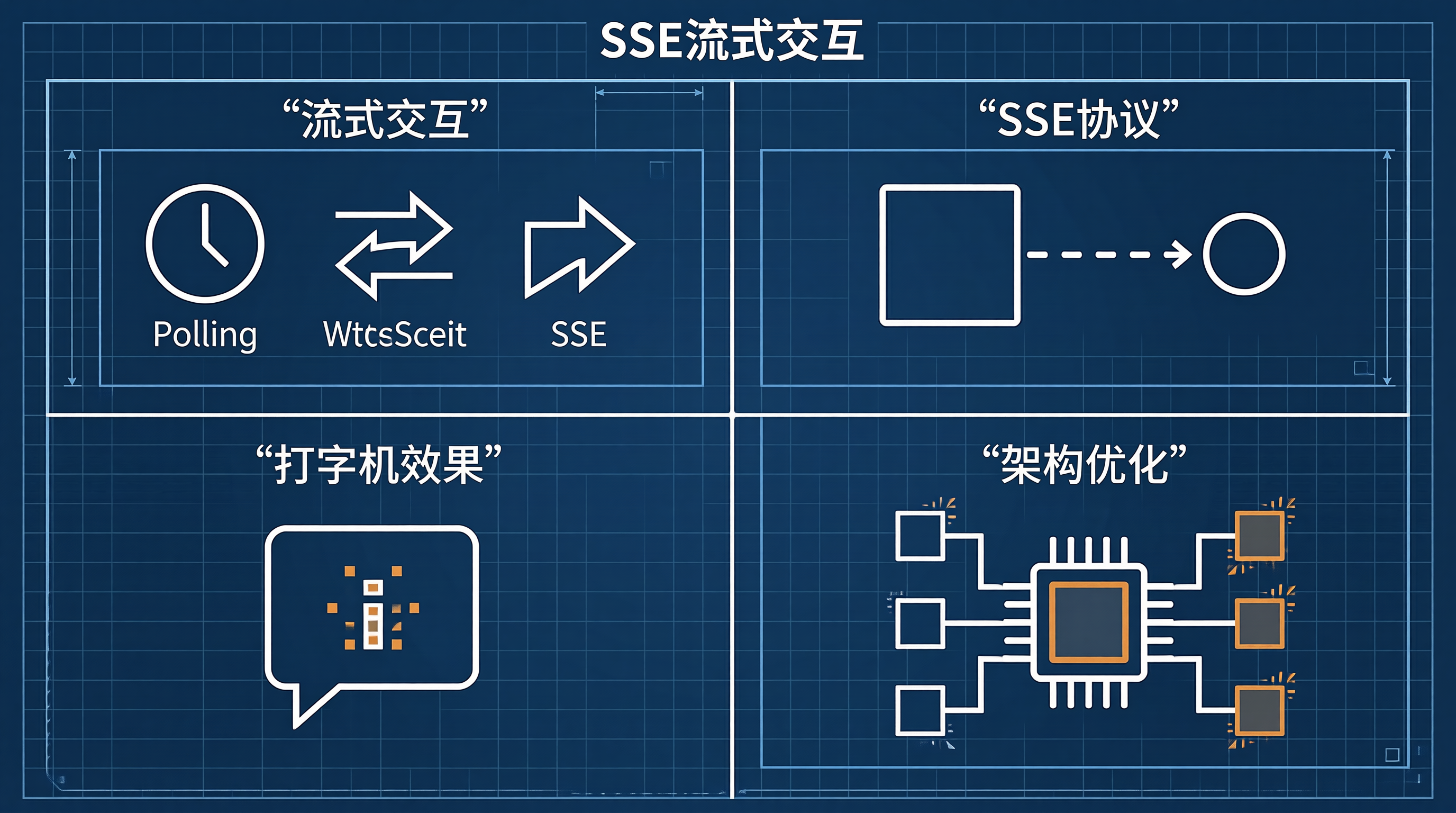
优势实现方式效果低延迟HTTP长连接 + 流式传输token间隔<10ms轻量级无需WebSocket握手连接建立<50ms前端友好天然浏览器支持可靠传输自动重连 + 事件ID断线自动恢复可扩展自定义事件类型灵活的业务适配SSE流式交互是AI智能客服打字机效果的最佳技术底座。通过合理的架构设计——服务端采用流式数据生产、中间件层做好缓冲控制、前端实现精细的渲染调度——能够在保证低延迟的同时提供流畅
智能客服系统对响应延迟有严格要求。用户期望在1-2秒内看到AI的回复,而每一轮对话需要依次完成:文本向量化、意图分类、知识库检索、答案生成等多个步骤。如果这些环节全部依赖服务端API,网络延迟和GPU排队会进一步增加响应时间。Transformers.js 将部分推理任务转移到用户终端,通过消除网络往返来降低延迟。但浏览器端的计算资源有限,能否在保证用户体验的前提下完成实时推理?
优势说明轻量高效基于HTTP协议,无需额外握手自动重连EventSource内置断线重连单向推送完美匹配AI流式输出场景实现简单前端几行代码即可接入资源友好相比WebSocket节省服务端资源技术有温度,代码有灵魂。当用户看到AI逐字输出回复时,那种"正在思考"的实时感,让冰冷的机器多了一份人性化的温度。这正是前端工程师用技术细节打磨用户体验的最佳诠释。