




- @weixin_42641909
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
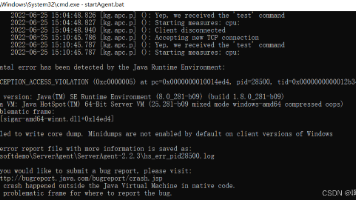
下载网址:https://github.com/cnstar9988/sigar/raw/master/sigar-amd64-winnt.dll。windows系统(尤其windows10,windows11系统)与Angent内自带的sigar-amd64-winnt.dll冲突。综述, 报错问题已解决, 博主遇到过这个问题,但有的小伙伴儿可能不会遇到,跟电脑系统有关 ,如果遇到这个问题,可以
1. Redis是什么Redis 是 C 语言开发的一个开源的(遵从 BSD 协议)高性能键值对(key-value)的内存数据库,可以用作数据库、缓存、消息中间件等。它是一种 NoSQL(not-only sql,泛指非关系型数据库)的数据库。Redis作为一个内存数据库,具有如下有特点:性能优秀, 数据在内存中, 读写速度非常快, 并支持10W QPS(每秒查询效率).单进程单线程, 是线程安
1. sql基础)建表语句--建表--学生表CREATE TABLE `Student`(`s_id` VARCHAR(20),`s_name` VARCHAR(20) NOT NULL DEFAULT '',`s_birth` VARCHAR(20) NOT NULL DEFAULT '',`s_sex` VARCHAR(10) NOT NULL...
1. Spark设置日志级别前言Spark有多种方式设置日志级别,这次主要记录一下如何在Spark-submit设置Spark日志级别,本文介绍三种方式需求因为Spark的日志级别默认为INFO(log4j.rootCategory=INFO, console),这样在运行程序的时候有很多我不需要的日志信息都打印出来了,看起来比较乱,比较烦,抓不住重点,而我只想把warn和error打印...
1. 基本命令ls -R 树结构显示某文件夹下的所有文件(包括子文件夹 )touch 文件名创建文件mv2.txt3.txt重命名mv2.txtbbb/3.txt2.txt剪切到bbb/目录下并重新命名为3.txtcp -r aaa/bbb/递归复制aaa/目录到bbb/目录下mvaaa/bbb/...
学习目标掌握倒排索引原理了解Lucene的作用了解Field字段的选择掌握Lucene创建索引基本API掌握Lucene查询基本API1. 了解搜索技术1.1 搜索引擎什么是搜索引擎?搜索引擎的原理可以看到搜索引擎的功能主要是三部分:爬行和抓取数据(爬虫多用Python来编写、但是Java也能实现)对数据做预处理(提取文字、中文分词、建立倒排索引)提供搜...
1. Kafka的分区数是不是越多越好?1.1 分区多的优点Kafka使用分区将topic的消息打算到多个分区分布保存在不同的broker上,实现了producer和consumer消息处理的高吞吐量。Kafka的producer和consumer都可以多线程地并行操作,而每个线程处理的是一个分区的数据。因此分区实际上是调优Kafka并行度的最小单元。对于producer而言,它实际上...