




- @weixin_39400721
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文介绍了在Windows环境下让AMD显卡(如RX6600XT)运行Ollama大模型时调用GPU的方法。由于官方Windows版Ollama对部分AMD GPU架构支持不完整,导致默认仅使用CPU。解决方案包括替换ROCm运行库(6.4.2版本)、更新rocblas计算库等步骤,使RX6000/7000系列显卡能以GPU运行模型,性能提升约10倍(从2-3 token/s提升至20-35

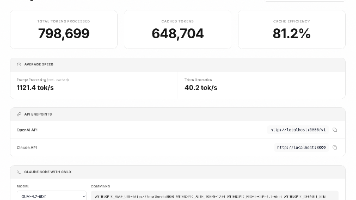
摘要: oMLX针对本地LLM在Agent框架(如OpenClaw)中的性能瓶颈,提出两级KV Cache架构(RAM+SSD),通过持久化复用中间计算结果,显著优化长上下文推理。相比传统方案需重复prefill(30-90秒/次),oMLX支持增量计算,后续请求降至约5秒。其核心创新在于将KV Cache从临时内存升级为可复用资产,结合模型量化与分层内存策略,使本地推理达到工程可用水平,尤其适合
摘要:本文介绍了在Windows环境下让AMD显卡(如RX6600XT)运行Ollama大模型时调用GPU的方法。由于官方Windows版Ollama对部分AMD GPU架构支持不完整,导致默认仅使用CPU。解决方案包括替换ROCm运行库(6.4.2版本)、更新rocblas计算库等步骤,使RX6000/7000系列显卡能以GPU运行模型,性能提升约10倍(从2-3 token/s提升至20-35
本文提供了OpenClaw工具的两种卸载方法:当CLI仍可用时,可通过自带命令openclaw uninstall一键卸载,或分步停止服务、删除配置;若CLI已丢失但服务仍在运行,则需按操作系统(macOS/Linux/Windows)分别手动清理服务进程。特别提醒注意多profile配置、远程模式及源码安装等特殊情况的残留清理,确保完全卸载。文末强调操作顺序的重要性,避免因步骤错误导致卸载不彻底