




- @weixin_36296444
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
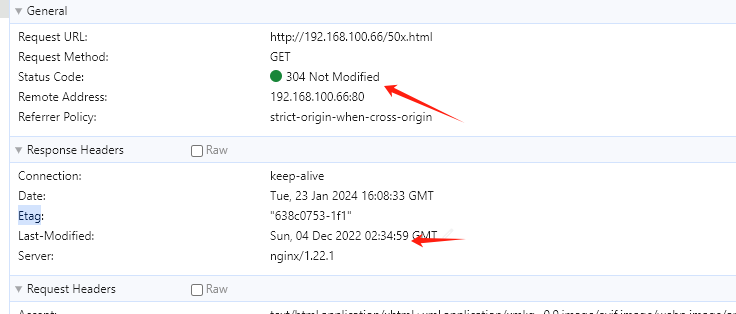
nginx客户端协商缓存用nginx作为静态资源服务器,默认就走的协商缓存,同一个资源再次访问状态码是304登录后复制location / {roothtml;add_header aaaaa 11111;autoindex on;...
本文介绍了如何在星图GPU平台上自动化部署🌿 Phi-3 Forest Laboratory | 森林晨曦实验室镜像,实现AI模型的多样化输出。该镜像支持通过调节Temperature参数,在'森林严谨版'(精准技术解释)与'山涧创意版'(生动类比输出)间灵活切换,适用于学术研究、创意写作等场景,满足不同内容创作需求。
本文介绍了如何在星图GPU平台上自动化部署Git-RSCLIP镜像,用于遥感图像的高精度英文标签优化与地物分类。通过规范化提示词写法(如添加传感器类型、空间关系、季节特征等),用户可显著提升分类准确率,典型应用于卫星影像中的农田、水体、城市区域等遥感地物识别任务。
本文介绍了如何在星图GPU平台上自动化部署🔄 coze-loop - AI 代码循环优化器镜像,实现Python代码质量的智能提升。通过本地化、离线化的AI分析,该镜像可对现有代码进行效率优化、可读性增强及潜在Bug修复,典型应用于开发阶段的代码审查前预检与工程实践教学。
本文介绍了如何在星图GPU平台上自动化部署coze-loop - AI 代码循环优化器镜像,实现对老旧循环代码的智能重构。用户可一键优化‘魔法数字’类代码,显著提升可读性、运行效率与健壮性,典型应用于Code Review预审、技术债清理及工程师协作编程场景。
本文介绍了如何在星图GPU平台上自动化部署🔄 coze-loop - AI 代码循环优化器镜像,实现本地化Python代码智能重构。用户可一键启动服务,针对实际开发中的数据清洗、函数封装等典型场景,快速获取兼顾性能、可读性与健壮性的优化方案,显著提升日常编码质量与效率。
本文介绍了如何在星图GPU平台上自动化部署OFA图像英文描述(ofa_image-caption_coco_distilled_en)镜像,快速搭建AI图像描述服务。该方案基于Docker与Supervisor,实现了一键部署与进程自管理,可广泛应用于电商平台自动为商品图片生成英文描述等场景,显著提升内容创作效率。
本文介绍了如何在星图GPU平台自动化部署Git-RSCLIP图文检索模型,实现遥感图像的零样本分类与检索。该模型可快速识别土地利用类型,如区分河流、森林和城市区域,大幅提升环境监测和灾害评估的效率。
本文介绍了如何在星图GPU平台上自动化部署AudioLDM-S (极速音效生成)镜像,为Java开发者提供快速集成方案。通过该平台,开发者可轻松搭建AI音效生成服务,并将其应用于游戏、视频制作等场景,实现根据文本描述快速生成环境音效或背景音乐。
本文介绍了如何在星图GPU平台上一键自动化部署Qwen3-ASR-1.7B语音识别模型v2,快速构建企业级语音处理服务。该模型支持多语言实时语音转写,典型应用于跨国企业会议自动转录和纪要生成,保障数据安全与处理效率。