




- @volumeA
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Transformer模型中的位置编码与词嵌入相加不会破坏语义信息,主要原因在于:1. 高维空间特性使语义和位置信息可以分离;2. 位置编码采用正余弦函数,保证数值有界且位置唯一;3. 训练过程中模型会迫使两种信息在向量空间中趋于正交;4. 注意力机制能独立处理语义和位置关系。实验验证表明,BERT中词向量与位置向量的夹角接近90度,证实了这种正交性。这种设计使得Transformer既能保留语义
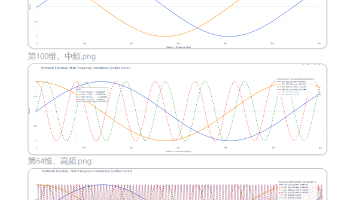
本文从理论到实践探讨了Embedding技术的本质及其在大模型中的应用。首先梳理了词向量发展历程,从One-Hot到Word2Vec再到BERT等模型的演进。然后从流形理论视角深入解析Embedding的本质,提出语义流形假说,认为高维数据实际上分布在内在维度低得多的几何结构上。在实践部分,重点分析了RAG系统中Embedding的应用,包括分块优化策略、混合搜索方法以及交叉编码器重排等技术,并通

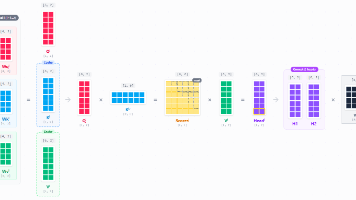
本文探讨了主流大模型从传统多头注意力(MHA)转向MQA、GQA、MLA等变体的优化逻辑,核心在于解码阶段的KV Cache及其引发的显存瓶颈问题。文章首先区分了推理的Prefill(并行计算全序列)和Decoding(增量生成)两个阶段,指出KV Cache通过缓存历史键值对避免重复计算,但同时也带来显存带宽压力。随后分析了MHA的计算流程,展示KV Cache如何以空间换时间优化解码效率。最终
本来没打算写这种经验性或者思考的内容。不过最近团队出故障比较多问的人比较多,想想以后还是开上一个分系列,说说一些经验和探索。这次算是一个抛砖引玉,希望大家都能基于自身能力认知来匹配团队规范,个人规范,以保证项目的可持续性。而不是继续堆积无法维护的屎山代码。(惨痛教训了)