
写文章




- @qq_49826430
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
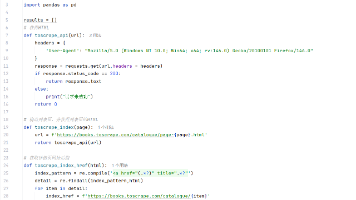
详情页的爬取(正则)
本文介绍了一个爬取书籍网站数据的Python爬虫程序。程序采用模块化设计,主要包含以下功能:1)通过toscrape_api函数获取网页HTML;2)使用toscrape_index函数构建列表页URL;3)通过正则表达式提取详情页链接;4)获取详情页内容并解析书名、价格、库存等信息;5)将结果保存为CSV文件。程序采用生成器优化性能,包含反爬机制,并通过主函数main()协调各功能模块。最终实现
爬取百度热搜小说名、作者、类型(xpath)
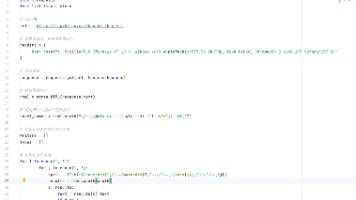
文章介绍了使用Python爬取百度小说排行榜的基本流程:1)通过requests.get()发送请求并设置User-Agent伪装头;2)使用etree.HTML解析网页;3)通过xpath定位目标元素,其中小说名直接获取,作者和类型因标签相同需用双层循环处理;4)用text()方法提取内容。文中强调xpath定位需借助浏览器开发者工具(F12),并建议初学者先掌握一种解析方法。
到底了