




- @oTengYue
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
决策树学习算法包含特征选择、决策树的生成与决策树的剪枝。特征选择作为第一步,在整个决策树的构建起到至关重要的作用。特征选择在于选取对训练数据具有分类能力的特征,这样可以提高决策树学习的效率。
搞机器学习也有一段时间了,每次部署GPU开发环境就是一场战争,先记录一下基本步骤,结合网上资料和个人实践整理如下:1、检查BIOS启动项,关闭一些选项在开机启动项的Security选项中检查UEFI是否开启,如果开启的话请立马关掉它(重要)在开机启动项的Boot选项中检查Secure Boot是否开启,如果开启的话请立马关掉它(重要)2、安装相关依赖sudo apt-ge...
搞机器学习也有一段时间了,每次部署GPU开发环境就是一场战争,先记录一下基本步骤,结合网上资料和个人实践整理如下:1、检查BIOS启动项,关闭一些选项在开机启动项的Security选项中检查UEFI是否开启,如果开启的话请立马关掉它(重要)在开机启动项的Boot选项中检查Secure Boot是否开启,如果开启的话请立马关掉它(重要)2、安装相关依赖sudo apt-ge...
yolov3训练日志可视化主要为loss和iou曲线的可视化,这些是我们查看训练效果的重要依据,首先看一个批次的日志输出:说明:一个批次有16*3条信息,每组包含三条信息,分别是:Region 82 Avg IOU:Region 94 Avg IOU:Region 106 Avg IOU:其中每行的参数意义如下:Avg IOU:当前迭代中,预测的box与标注...
文章目录一、分类二、BlockingQueue 阻塞队列三、ConcurrentLinkedQueue 非阻塞队列一、分类java中所有队列都继承至java.util.Queue接口,该接口定义了以下三组方法:方法名抛出异常返回特殊值插入add(e)offer(e)移除remove()poll()检查element()peek()Java提...
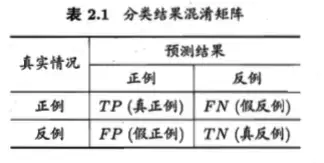
文章目录混淆矩阵ROCAOUPRCF1-Score多分类的F1-Score选择指标ROC 曲线和 AUC 常被用来评价一个 二值分类器 的优劣。混淆矩阵其中,TP(真正,True Positive)表示真正结果为正例,预测结果也是正例;FP(假正,False Positive)表示真实结果为负例,预测结果却是正例;TN(真负,True Negative)表示真实结果为正例,预测结果却是负例...
文章目录正则化L0范数L1范数L2范数elastic net总结讨论几个问题为什么L1稀疏,L2平滑?实现参数的稀疏有什么好处吗?参数值越小代表模型越简单吗?正则式的应用场景正则化正则化的作用实际上就是防止模型过拟合,提高模型的泛化能力。正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项(regularizer)或惩罚项(penalty term)。正则化一般是模型复杂度的单调递...
搞机器学习也有一段时间了,每次部署GPU开发环境就是一场战争,先记录一下基本步骤,结合网上资料和个人实践整理如下:1、检查BIOS启动项,关闭一些选项在开机启动项的Security选项中检查UEFI是否开启,如果开启的话请立马关掉它(重要)在开机启动项的Boot选项中检查Secure Boot是否开启,如果开启的话请立马关掉它(重要)2、安装相关依赖sudo apt-ge...
搞机器学习也有一段时间了,每次部署GPU开发环境就是一场战争,先记录一下基本步骤,结合网上资料和个人实践整理如下:1、检查BIOS启动项,关闭一些选项在开机启动项的Security选项中检查UEFI是否开启,如果开启的话请立马关掉它(重要)在开机启动项的Boot选项中检查Secure Boot是否开启,如果开启的话请立马关掉它(重要)2、安装相关依赖sudo apt-ge...
栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。栈内存堆内存基础类型,对象引用(堆内存地址)由new创建的对象和数组存取速度快相对于栈内存较慢数据大小声明周期必须确定分配的内存由java虚拟机自动垃圾回收