




- @m0_64363449
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AI已融入供应链的几乎所有解决方案中,成为提升销售额和利润率、同时引发人们浓厚兴趣的手段。在竞争日益激烈的环境中,许多企业为抢占先机或保持竞争力,纷纷急于采用AI技术,但有时方式过于表面、效果不佳,最终未能创造真正的价值。例如,在供应链应用领域,只有一小部分AI应用能通过显著的投资回报率创造真正的价值,AI已成为现实,但许多解决方案无法有效满足企业需求,更不用说克服实际的供应链挑战了,因此,关键是

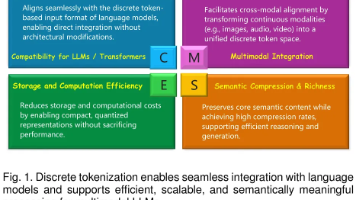
作为多模态 LLM 的底层桥梁,Discrete Tokenization 的重要性会随着模型能力边界的拓展而不断提升。此综述提供了首个全景化、系统化的离散化参考,不仅梳理了八类核心技术,还围绕输入数据的模态与模态组合构建了完整的应用全景,从单模态到双模态,再到多模态融合,形成了清晰的技术脉络。这是首个以输入模态为主线构建内容结构的系统化综述,为研究者提供了按模态快速检索方法与应用的技术地图。
本系列的第一部分回顾了大规模视频语言预训练的进展、应用、数据集和技术。该任务使用弱字幕和视频进行表征学习。预训练和微调是深度学习中的一种标准学习范式,用于在大型数据集上对模型进行预训练,然后在较小的数据集上针对特定任务进行微调。这消除了为不同任务训练新模型的需要,并降低了计算成本。预训练通常使用自监督学习在 ImageNet 等大型数据集上进行,而无监督学习在自然语言处理 (NLP) 和计算机视觉

执行自定义脚本来完成特定操作。
你是否曾想过让强大的开源大模型(LLM)更懂你的专业领域,或者更能模仿你的写作风格?微调(Fine-Tuning)就是实现这一目标的钥匙。过去,微调是资源雄厚的大公司的专利,动辄需要数十张GPU和复杂的分布式训练知识。本文将手把手带你,用一个消费级GPU(甚至CPU!),在1小时内完成属于你自己的模型微调。准备工作:安装核心工具 在开始之前,我们需要准备好两样核心工具:Ollama: 用于本地拉取

想象一下,你请来一位博学多才的通用助理,他上知天文下知地理,但对你的行业术语和业务流程一无所知。“微调”就像是送这位助理去参加你行业的“岗前培训”,让他快速掌握专业知识和表达方式。比如说,如果你在医疗行业,通用AI可能知道“CT”是什么,不一定清楚“增强扫描与平扫的适应区别”。但通过微调,我们可以让AI学习大量医疗文献、诊断指南和病历数据,让它不仅能听懂专业术语,还能按医生的思维模式回答问题。
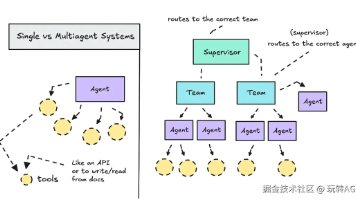
最近,我开始尝试构建不同类型的 Agentic AI 系统,最让我着迷的,是“单智能体(Single-Agent)”和“多智能体(Multi-Agent)”的差异。说实话,在没真正动手之前,我也只是听过这些概念,觉得听起来很玄。直到我用和亲自搭建了两个版本,一个“单兵作战”,一个“多智能体协作”,结果真的让我彻底改观。我想造一个能帮我追踪科技趋势的“研究助手 Agent”。它的任务很简单:每天帮我
AI大模型(Large AI Models / Large-scale AI Models) 是指拥有亿级以上参数的深度学习模型。AI大模型利用深度学习算法和人工神经网络技术等AI技术,通过学习大量的数据提升预测能力,其性能与模型的参数规模、数据集大小和训练用的计算量之间存在幂律关系。从应用领域角度分类,AI大模型分为通用大模型、垂直大模型;按输入数据类型,AI大模型分为单模态大模型、多模态大模型

通过 RAG,语言模型可以使用从矢量数据库中检索到的信息(预计是可靠的)来确保其响应基于现实世界的知识和背景,从而降低出现幻觉的可能性。正如本文前面所讨论的,向量数据库帮助我们以向量的形式存储信息,其中每个向量捕获有关被编码文本的语义信息。作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。例如,由于 LLM 是使
Happy-LLM》项目是一个系统性的 LLM 学习教程的开源项目,旨在帮助学习者深入理解大语言模型的核心原理和训练过程,并能够亲手搭建和训练一个 LLM。适合大学生、研究人员和 LLM 爱好者阅读,建议具备一定的编程经验(尤其是 Python)和深度学习基础。
