




- @m0_38031488
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
神经网络中的计算通常以浮点数计算(Float32)进行,模型量化是指以较低的精度损失将这些浮点数计算近似为更低比特的计算,如Float16、Int8等。从而降低模型存储大小、降低显存占用、提升推理性能。在不同的需求下,选择不同的量化方案。

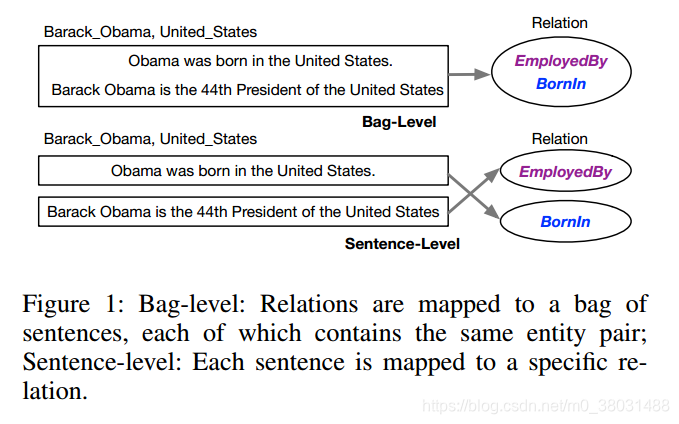
Reinforcement Learning for Relation Classification from Noisy Data摘要:目前存在的关系抽取方法大多是依赖于远程监督假设的,即所有包含两个相同实体的句子都只表达一种关系。但是这些方法都是在包级别上做关系抽取,不能明确的映射出单句和关系之间的联系,并且由远程监督产生的错误标签还在影响着模型的精度。该文在含有噪声的数据集上提出了一...
论文链接:Graph Convolutional Networks for Text ClassificationIdea:基于一个数据集内的共现词和文档构建一个文本异构图网络。在文本图网络中,单词和文档向量初始化形式为one-hot,在文档已知类标签的监督下,联合学习单词和文档的向量化表示。图网络能够有效的处理关系型(结构化)数据,可以以图的形式保留全局性结构化信息在图...

是杭州深度求索人工智能基础技术研究有限公司的简称,同时DeepSeek也是该公司研发的通用人工智能开源大模型平台。DeepSeek完全基于自研训练框架、自建智算集群和万卡算力等资源,在短时间内取得了显著的研发成果。它通过大幅度缩减以往大模型所需要的庞大算力,直接把大模型的成本降了下来。
FFmpeg 是一个领先的多媒体框架,能够解码、编码、转码、复用、解复用、流化、过滤和播放几乎所有人类和机器创建的格式。本指南将详细介绍如何在 CentOS 8.5.2111 系统上从源代码编译并安装 FFmpeg 6.1.1 版本。从源代码编译安装可以确保您获得最新版本的功能,并可以根据您的特定需求进行定制。本博客主要依赖于生成,我通过 manus 给出的方案逐步运行并安装成功,并且我也对比了下
当前主流的 LLM 主要采用 Decoder-only 为基础的模型结构。这意味着无论是在训练还是推理阶段,序列的生成都是逐个 token 进行的。在生成每个 token 时,模型需要频繁地进行访存操作,加载 KV Cache,往往成为训练或推理过程中的瓶颈。通过优化解码阶段,可以将单个 token 的生成转变为多个 token 的生成,从而提升训练和推理的性能。具体而言,在训练阶段,通过一次生成
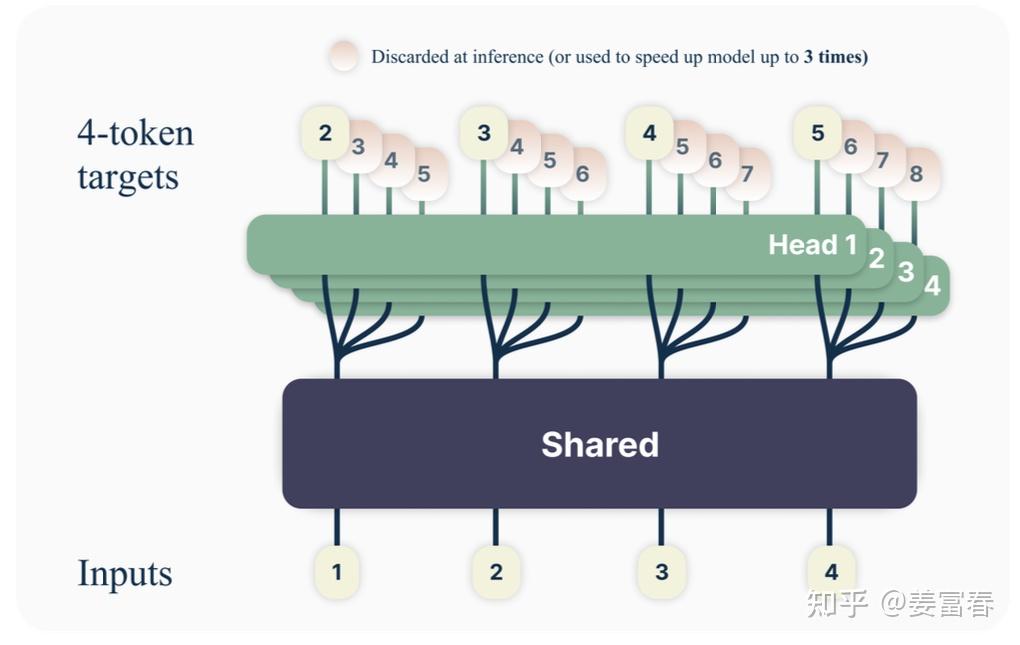
为什么现在的大模型大都是 decoder only 架构?这个问题想来稀松平常,经常能看到各大社区中的众多回答,但对于该问题的了解也非常碎片化,今天就系统的对该问题进行归纳梳理。

在搜索引擎应用中,分页查询是一种常见需求。Elasticsearch 提供了多种分页方式以应对不同场景。本文将结合实际应用场景,介绍三种常用的分页查询方法。
在 Transformer 模型中,mask 机制是一种用于在 self-attention 中的技术,用以控制不同 token 之间的注意力交互。Mask 机制经常被用于NLP任务中,按照作用总体来说可以分成两类。

是杭州深度求索人工智能基础技术研究有限公司的简称,同时DeepSeek也是该公司研发的通用人工智能开源大模型平台。DeepSeek完全基于自研训练框架、自建智算集群和万卡算力等资源,在短时间内取得了显著的研发成果。它通过大幅度缩减以往大模型所需要的庞大算力,直接把大模型的成本降了下来。