




- @gao_dou
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了基于鸿蒙ArkTS开发冰箱除味盒记录应用的实现方案。系统通过days、odor、changes三个状态变量记录使用天数、异味等级和更换次数,业务规则设定60天使用周期或4级异味触发更换提醒。应用采用ArkUI声明式框架和@State状态管理,实现数据更新与界面自动同步。文章详细阐述了数据结构、业务逻辑、交互刷新机制及边界条件处理,展示了从状态建模到界面呈现的完整开发流程,体现了鸿蒙应用开

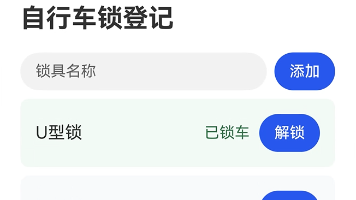
本文介绍了基于鸿蒙ArkTS开发的自行车锁登记应用实现。项目通过状态管理(@State)维护锁具名称和状态列表,核心功能包括:新增锁具(默认未锁定)、锁定状态切换、空名称过滤等。系统采用声明式UI实现自动刷新,通过数组切片操作触发列表重渲染,确保界面与状态同步。文章详细阐述了业务对象建模、状态管理、核心算法、边界处理等关键实现细节,并提供了默认数据示例(U型锁锁定状态、钢缆锁未使用)。整个应用遵循
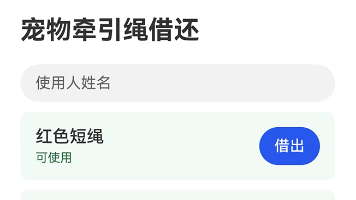
本文介绍了基于鸿蒙 ArkTS 的宠物牵引绳借还系统实现。系统通过状态管理(holder、items)和核心算法(借用人校验、双分支状态机)实现牵引绳的借出与归还功能。交互界面展示使用人、状态和当前使用数量,采用声明式 UI 自动刷新。系统包含边界保护机制,确保空姓名不能借出等业务规则的严格执行。文章详细解析了数据结构、业务规则、交互机制和边界处理,并配有开发环境示意图,展示了利用 ArkTS 和
本文介绍了使用鸿蒙ArkTS开发床品收纳容量计算应用的实践。该项目通过状态管理(capacity、quilts、pillows、sheets)实现收纳容量计算功能,核心算法采用被子30L、枕头12L、床单4L的权重计算公式。应用界面展示已用容量与收纳袋容量的比较结果,当超出容量时提示分袋收纳。文章详细阐述了业务对象建模、状态管理、输入控件交互等15个维度的实现方案,强调通过声明式UI和状态驱动实现

本文介绍了基于鸿蒙ArkTS开发的隔热手套清洁应用,实现了使用次数和污渍程度的智能提醒功能。系统通过uses、stains、count三个核心状态变量管理数据,当使用达到10次或污渍达到4级时触发清洗提示。清洗后数据重置(次数归零、污渍降为1级)并累计清洗次数。应用采用ArkUI声明式框架,通过@State实现状态管理,确保界面自动刷新。项目重点处理了业务规则、边界条件和交互逻辑,包括阈值判断、数

本文介绍了基于鸿蒙ArkTS框架开发的杯垫库存管理系统实现方案。项目通过@State管理状态数据(name和items数组),核心功能包括:1)空值校验和新增杯垫(add方法);2)修改库存数量(change方法);3)实时统计低库存类别(filter方法)。系统采用声明式UI自动刷新界面,默认展示软木杯垫(6个)和硅胶杯垫(4个)的库存状态,当数量≤1时会标记为低库存。文章详细分析了15个实现维

本文介绍了使用鸿蒙ArkTS开发窗帘绑带库存管理应用的过程。系统通过@pairs和@used状态变量管理绑带总数和使用数量,可用量通过Math.max(pairs-used,0)动态计算。核心功能包括:1)使用Slider控件调整数量;2)备用绑带不足时提示预警;3)声明式UI自动刷新。应用采用ArkUI框架实现状态与界面的双向绑定,通过边界条件保护确保业务逻辑稳定性,默认展示总绑带4对、使用中2

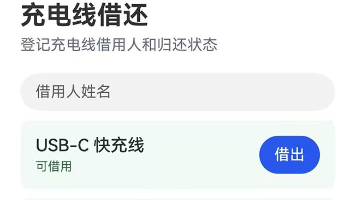
本文介绍了基于鸿蒙ArkTS开发的充电线借还管理系统。系统采用ArkUI框架和@State状态管理,核心功能包括姓名校验、借还状态切换和借出统计。数据结构由holder和cables组成,Cable对象保存名称、持有人及借出状态。业务规则通过toggle操作实现:对已借出项执行归还并清空持有人,对可借出项要求输入姓名后完成借出。系统实现了声明式UI刷新,自动更新持有人信息、借还状态和借出数量显示。
本文介绍了基于鸿蒙ArkTS开发的沙拉分量计算应用。系统通过状态管理(people、greens、protein、result)实现核心计算功能,采用双乘法规则(人数×蔬菜/蛋白克数)生成总量结果,并处理整数范围等边界条件。应用包含输入控件交互、事件回调机制和声明式UI刷新,默认以2人份(蔬菜120g/人、蛋白80g/人)为初始数据,实时显示计算结果。设计上强调数据一致性、业务规则清晰性和边界保护

本文介绍了基于鸿蒙ArkTS实现的居家拖鞋库存管理系统。系统通过ArkUI框架和@State状态管理,分类统计成人、儿童和客用拖鞋数量(默认值分别为4、2、2双)。核心功能包括总量自动计算(total=adult+child+guest)、客用库存预警(少于2双时提示补充)和交互式数量调整(通过Slider控件)。系统采用声明式编程实现状态自动刷新,确保界面与数据同步,并通过分类统计、阈值检测等边
