- @WSK1454360679
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
核心定位:首次提出将目标检测视为「回归问题」,摆脱传统两阶段检测(如 R-CNN)的繁琐流程。关键改进 / 特点:用单一 CNN 网络完成「目标定位 + 类别预测」,无需分区域提取候选框,端到端训练 / 推理;将输入图片划分为 7×7 网格,每个网格预测 2 个边界框 + 类别概率;速度极快(45 FPS),但缺点明显:小目标检测差、定位精度低、召回率(漏检率)高。
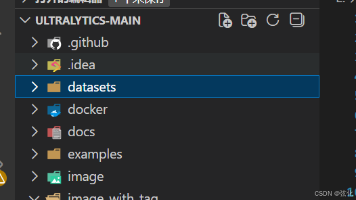
YOLO 系列模型(如 YOLOv8)训练前的数据集目录规范,核心作用是让模型能正确识别并关联 “图片 - 标签”,保证训练流程顺利启动,各部分解析如下:关键要求说明“一一对应” 的必要性:labels 目录下的标签文件名,必须与对应的 images 目录下的图片文件名完全一致(仅后缀不同,如fire_001.jpg对应fire_001.txt)。这是 YOLO 模型加载数据的核心规则 —— 模型
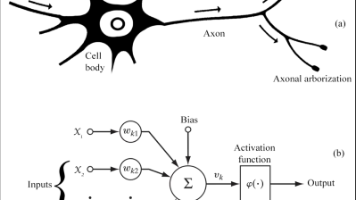
智能黑箱联结主义符号主义机器学习感知机线性不可分多层感知机神经网络卷积卷积神经网络神经网络结构设计拟合函数损失函数梯度下降反向传播对抗样本统计语言模型图片存储流型假设去噪函数扩散生成长程依赖
YOLO 系列模型(如 YOLOv8)训练前的数据集目录规范,核心作用是让模型能正确识别并关联 “图片 - 标签”,保证训练流程顺利启动,各部分解析如下:关键要求说明“一一对应” 的必要性:labels 目录下的标签文件名,必须与对应的 images 目录下的图片文件名完全一致(仅后缀不同,如fire_001.jpg对应fire_001.txt)。这是 YOLO 模型加载数据的核心规则 —— 模型
🔵 深蓝色(all classes):两类综合精确率曲线(将 fire 和 smoke 两个类别合并后,计算得到的整体精确率 - 置信度关系,代表模型在所有检测目标上的平均精确率表现。9 mAP@0.5:在「预测框与真实框重叠至少 50% 才算正确」的规则下,模型对所有待检测类别,综合【精确率(找的准)+ 召回率(找的全)】的平均得分。置信度 > 0.2 后,三条曲线均快速攀升并稳定在 接近 1