- @2401_87746054
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AI Agent 系统设计的核心,是把模型计划和工具执行分层。权限、校验、审计、预算和确认机制,比让模型更会说话更重要。Agent 能做事,系统就要更会兜底。
AI Agent 系统设计的核心,是把模型计划和工具执行分层。权限、校验、审计、预算和确认机制,比让模型更会说话更重要。Agent 能做事,系统就要更会兜底。
AI Agent 系统设计的核心,是把模型计划和工具执行分层。权限、校验、审计、预算和确认机制,比让模型更会说话更重要。Agent 能做事,系统就要更会兜底。
AI Agent 系统设计的核心,是把模型计划和工具执行分层。权限、校验、审计、预算和确认机制,比让模型更会说话更重要。Agent 能做事,系统就要更会兜底。
AI Agent 系统设计的核心,是把模型计划和工具执行分层。权限、校验、审计、预算和确认机制,比让模型更会说话更重要。Agent 能做事,系统就要更会兜底。
多 Agent 协作架构的本质是用"分工"换"质量",用"并行"换"延迟",但代价是系统复杂度的上升。核心设计原则有三条:第一,Agent 之间必须通过结构化消息通信,杜绝自然语言直传;第二,编排层必须具备超时熔断和重试能力,防止单点故障扩散;第三,必须从第一天就建立全链路追踪,否则上线后调试将是灾难。落地路线建议:从一个 Orchestrator + 2-3 个 Agent 的最小可用架构起步,
AI 任务调度引擎的核心目标是平衡延迟 SLA 与 GPU 资源利用率。三大核心机制——优先级调度防饿死、资源感知路由降成本、弹性伸缩提效率——各有适用场景和代价。冷启动延迟是弹性伸缩的最大制约,维持最小实例池是务实的妥协方案。请求复杂度预估的不确定性、多租户隔离的矛盾、以及系统复杂度的边际收益递减,都是设计调度引擎时必须面对的现实约束。调度引擎只在请求量大、模型多样、SLA 分级明确的场景下才有
向量数据库与 RAG 架构的核心挑战是检索精度与查询延迟的平衡。索引类型的选择决定了这个平衡点——IVF_FLAT 适合中等规模、精度优先的场景,HNSW 适合大规模、延迟优先的场景。混合检索通过结合向量检索和 BM25 关键词检索,弥补了纯向量检索对关键词不敏感的缺陷。落地时需要关注三个关键点:文本分块优先在句子边界切分,避免语义截断;元数据过滤应在向量检索之前执行,减少搜索空间;检索结果需要做
RAG 检索优化的核心是"粗排+精排"的两阶段策略。混合检索(向量+BM25)通过 RRF 融合两路结果,兼顾语义相似性和关键词精确匹配,是粗排阶段的最优方案。重排序器(Cross-Encoder)对候选文档做精细打分,是精排阶段的关键组件。召回率与延迟的权衡没有万能公式,需要根据业务场景选择索引参数——精确问答场景优先召回率,开放对话场景优先延迟。上下文裁剪是端到端延迟优化的最后一环,相关性打分
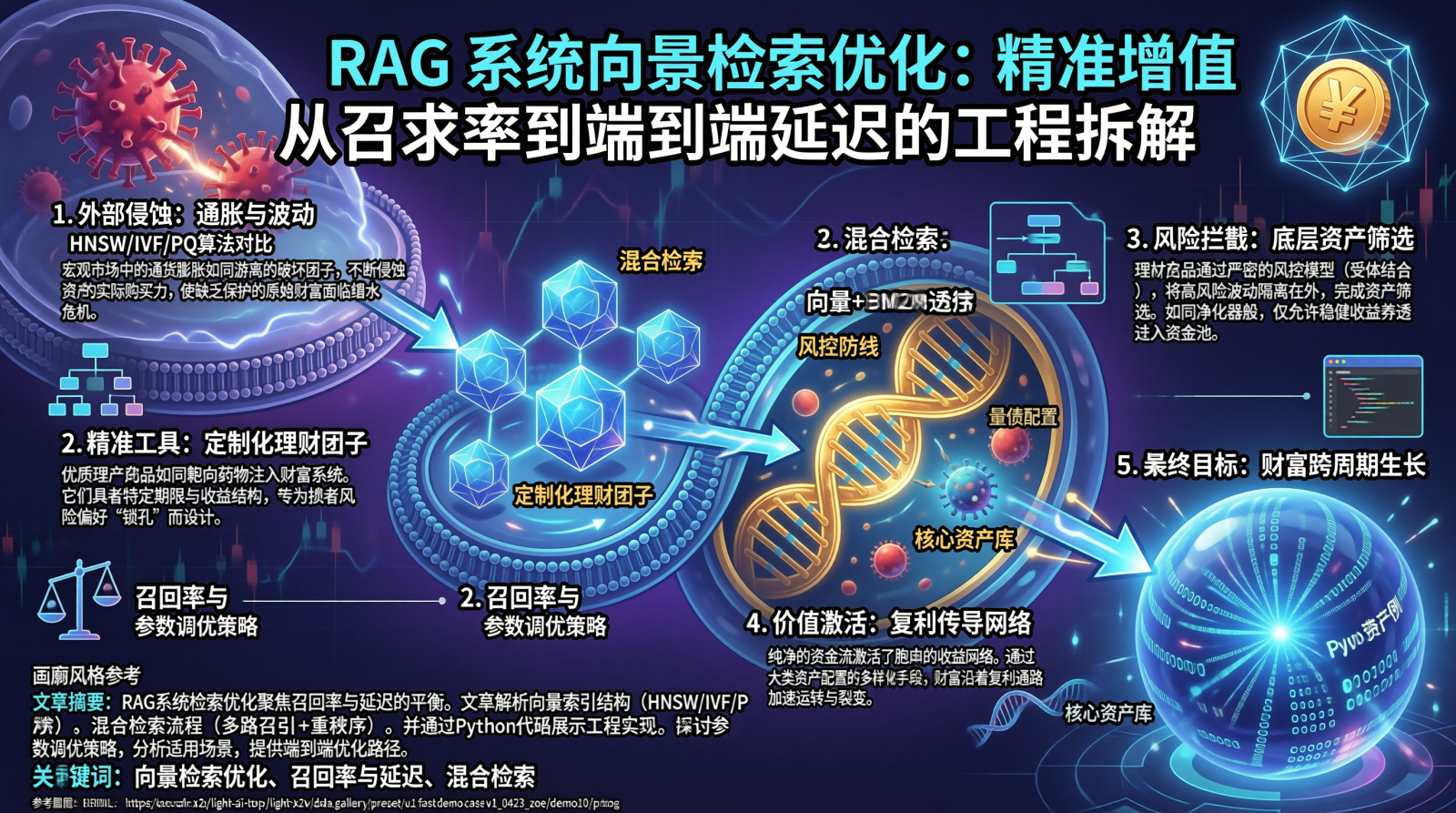
Agent 工具调用架构的核心挑战,不是"如何让模型调用工具",而是"如何在工具规模膨胀时保持选择精度与执行安全"。本文给出的解法是三层架构:语义嵌入 + 规则索引的混合路由解决选择精度问题,参数校验 + 危险分级的安全执行器解决执行安全问题。落地路线建议:第一阶段,工具数量小于 10 个时,直接使用静态绑定,所有工具 Schema 全量注入 Prompt;第二阶段,工具数量 10-50 个时,引