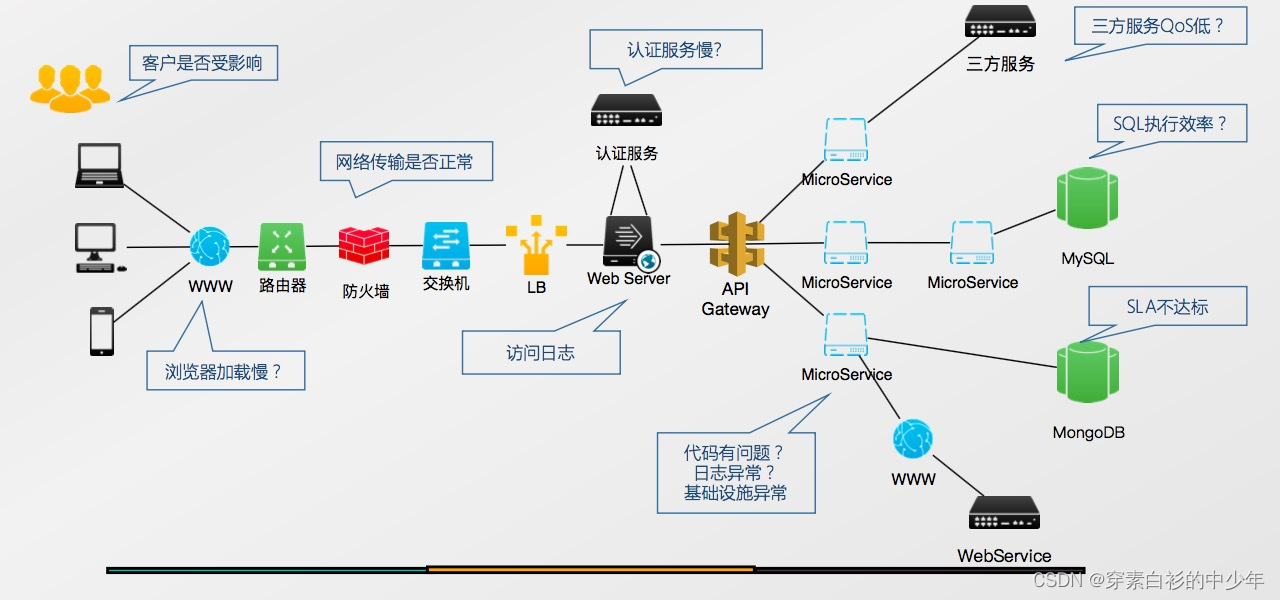
1.文档阅读
数据库监控_诗雨时的博客-CSDN博客_数据库监控原理
数据库监控, 数据库监控工具 - ManageEngine Applications Manager
PHP性能监控 | PHP应用性能监控器 - ManageEngine Applications Manager
APM,应用性能管理,应用性能监控 - Applications Manager
https://ningxiaofa.blog.csdn.net/article/details/103597683
https://ningxiaofa.blog.csdn.net/article/details/106497512
https://ningxiaofa.blog.csdn.net/article/details/106238780
https://ningxiaofa.blog.csdn.net/article/details/123521975
https://ningxiaofa.blog.csdn.net/article/details/124832916
https://ningxiaofa.blog.csdn.net/article/details/122000930
2.整理输出
服务监控的重要性
服务监控是现代IT基础设施中不可或缺的一部分。通过实时监控服务的运行状态、性能和可用性,可以及时发现潜在问题,确保系统稳定运行。服务监控不仅有助于预防故障,还能提高运维效率,降低业务中断风险。
常见的服务监控工具
Prometheus:一款开源的监控系统,支持多维数据模型和强大的查询语言。适用于云原生环境和微服务架构。
Grafana:可视化工具,可与多种数据源集成,如Prometheus、InfluxDB等。提供丰富的仪表盘和告警功能。
Zabbix:企业级监控解决方案,支持网络、服务器和应用程序的监控。具备自动发现和告警机制。
服务监控的关键指标
CPU使用率:反映服务器处理能力的使用情况。过高的CPU使用率可能导致性能下降。
内存使用率:监控内存占用情况,避免因内存不足导致服务崩溃。
磁盘空间:确保磁盘有足够的存储空间,防止因磁盘满导致服务不可用。
网络流量:监控进出流量,识别异常流量或网络拥塞。
响应时间:衡量服务处理请求的速度,直接影响用户体验。
实施服务监控的最佳实践
明确监控目标:根据业务需求确定关键指标,避免过度监控或遗漏重要指标。
设置合理的告警阈值:避免频繁误报或漏报。阈值应根据历史数据和业务特点动态调整。
定期审查监控配置:随着业务发展,监控需求可能变化。定期审查和优化监控配置。
集成日志管理:结合日志分析工具,如ELK Stack,提供更全面的故障排查能力。
服务监控的未来趋势
AI驱动的监控:利用机器学习算法预测潜在故障,实现智能告警和自愈。
无服务器监控:随着无服务器架构的普及,监控工具需要适应这种新型部署模式。
边缘计算监控:边缘设备的增多要求监控工具支持分布式和低延迟的监控需求。
通过以上方法和工具,可以有效构建一个全面的服务监控体系,确保业务的高可用性和稳定性。
2.1 是什么
简单说: 为了保证服务的高可用性,高稳定性,高性能,而采用的各种手段。
2.2 为什么需要「应用场景」
见上面
简单说: 为了效益最大化;
2.3 什么时候出现「历史发展」
服务本身要求,只不过逐渐变得开始全面复杂。
2.4 如何实践
服务监控的核心目标
确保服务可用性、性能稳定性和快速故障恢复。需覆盖基础设施、应用层、业务指标等维度,通过数据采集、告警、可视化实现闭环管理。
明确监控范围
基础设施监控:CPU、内存、磁盘、网络等硬件资源使用率。
应用性能监控:接口响应时间、错误率、线程池状态、JVM/GC指标(如Java服务)(这里因服务不同而异)。
业务指标监控:订单量、用户活跃度、支付成功率等核心业务指标。
依赖服务监控:数据库、缓存、消息队列等中间件的健康状态。
搭建监控系统
数据采集:
- 使用Prometheus、Telegraf等工具采集指标数据,或通过代码埋点上报业务指标。
- 日志监控通过ELK(Elasticsearch+Logstash+Kibana)或Grafana Loki实现。
存储与查询:
- 时序数据存储推荐Prometheus + Thanos(长期存储),或InfluxDB。
- 日志存储使用Elasticsearch或ClickHouse。
可视化与告警:
- 通过Grafana配置仪表盘,展示关键指标趋势。
- 告警规则配置在Prometheus Alertmanager或PagerDuty,触发条件需避免噪音(如持续5分钟超阈值)。
示例Prometheus告警规则:
groups:
- name: service_errors
rules:
- alert: HighErrorRate
expr: rate(http_requests_total{status=~"5.."}[5m]) > 0.1
for: 10m
labels:
severity: critical
annotations:
summary: "High error rate on {{ $labels.instance }}"
关键实践原则
分层分级:区分核心服务与非核心服务,设置不同告警优先级。例如支付服务错误率告警应优先于日志采集延迟告警。
SLO/SLA驱动:
- 定义服务级别目标(SLO),如“99.9%的API响应时间<500ms”。
- 基于SLO计算错误预算(Error Budget),指导监控阈值设置。
根因分析(RCA):
- 为高频告警配置自动化诊断链路,如通过日志关联或调用链追踪(Jaeger/SkyWalking)快速定位问题模块。
持续优化
告警去噪:
- 合并同类告警,避免“告警风暴”。
- 引入机器学习(如异常检测算法)降低误报率。
混沌工程:
- 通过Chaos Mesh或Gremlin模拟故障,验证监控覆盖率和告警有效性。
成本控制:
- 压缩低价值监控数据(如非核心服务的分钟级指标降为小时级)。
- 使用采样策略减少日志存储量。
后续补充
... |


 12
12 0
0


 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)