Wall-EveWall-Eve概览视频(可选)
我的提交概述
Wall-Eve 是一个 Web 应用程序,旨在为 Eve Online 游戏的市场提供聚合数据。
Eve Online 及其市场的快速介绍
Eve Online 是一款 MMORPG,它提供了一个 API,允许第三方开发者从游戏中获取和处理大量数据。它提供了一个很好的机会来构建有趣的应用程序,我们可以与其他玩家分享。
游戏的核心之一是交易,它有自己的端点,我们可以在其中获得订单,其当前价格为玩家买卖的不同对象。
市场分为区域(您可以将其视为州或国家/地区),每个区域包含许多人们将购买和出售的地方(如城市)。
这将把我们引向何方?
希望构建市场工具的开发人员将主要与从某个地区返回订单的端点进行交互。
问题是此端点不按项目返回聚合数据,而是按所有订单返回。这意味着您可能需要提取超过 300 页的 10000 个条目,然后将它们聚合起来才能使用它们。
它可能有点乏味,因为它通常需要使用并发,一种能够处理大量数据的语言。
由于这个原因,我想知道是否不可能提供一个 API 来返回已经聚合的数据,并且可以使用一些查询参数对其进行过滤。让我们看看 Redis 如何在这方面为我提供帮助。
应用设计
基本设计很简单,我们需要定期从游戏提供的端点获取数据,所以我有最新的数据。然后我只需通过 API 提供数据,并使用用户在请求中输入的值过滤其输出。
有了这个描述,我们已经定义了 2 个服务:
-
将显示数据的 API
-
一个索引器,它将获取一个区域的数据
即使这两个服务就足够了,我们也缺乏正确控制索引的能力。
让我们谈谈我想到的更复杂的设计。
Eve Online 的部分地区交易速度较慢,被很多交易者忽视。这意味着这些地区的数据不一定需要像游戏的主要市场一样立即更新。这将有助于尽可能减少 I/O。
我希望能够安排索引,因此我可以优先考虑哪些区域将被快速拉取,哪些区域将延迟更长的时间。随之出现了 2 个新服务:
-
一个调度器,它将确定下一次索引的时间
-
一个延迟器,它将使延迟的作业保持在队列中,直到它们由于处理我在这里做了 2 个服务,所以它们可以相互独立地进化
但我仍然有一个问题。如何确定要索引的区域的优先级?
我需要能够确定哪个区域是重要的,为此我将简单地听取对 API 的调用。如果通过API频繁访问某个区域,则表明数据需要保持更新。否则,我们可以将索引延迟多一点,人们不会注意到它。
又来了一项服务:
- 一个Heartbeat,它将监听对API的调用并存储它们,以便我们以后可以使用它们
但是,如果这样做,如果有人为索引速度较慢的区域调用 API,则他可能拥有太旧的数据,可能在很长一段时间内都不会更新。
如果需要,我需要能够赶上索引,因此即使前几个命中包含旧数据,以下命中也会有新数据。这导致了我们最后一个服务的创建:
- 一个刷新,它还将监听对 API 的调用并确定我们是否需要赶上数据
我现在有 6 项服务希望一起工作。
技术实现
我需要使用一些 Redis 功能才能使这些服务协同工作。这是服务的架构
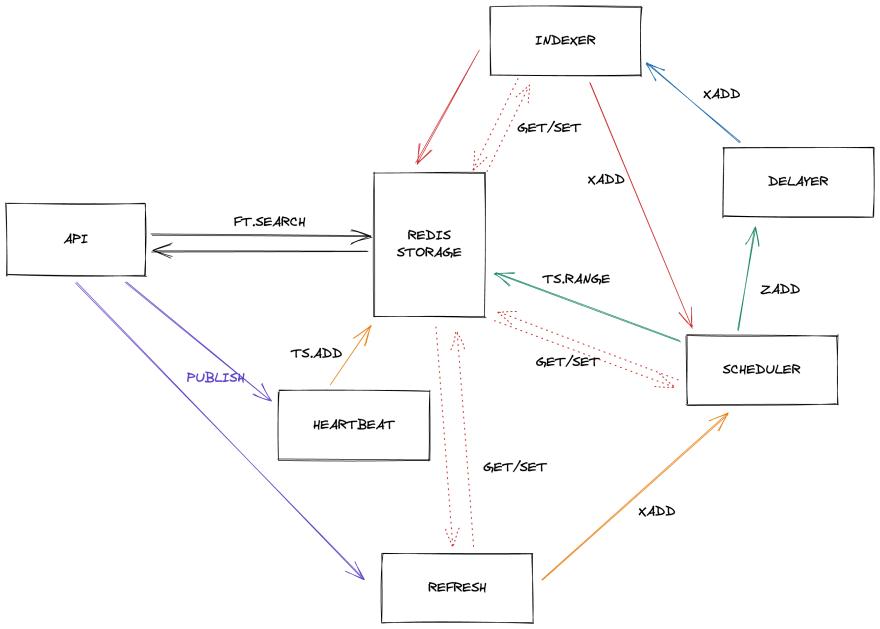
下面是对工作流程和服务之间交互的描述。
1.索引
这个服务监听一个流indexationAdd,一旦有消息到达,就会开始索引。
该任务可能有点慢,需要 1 或 2 分钟,因此 Indexer 可以分组工作以更快地消耗流。
索引需要获取一个区域的所有订单,还需要获取一些其他数据,例如它所在的位置的名称、项目的名称和其他一些名称。我们可以通过游戏的 API 获取它们,但是为了减少 I/O,我们会将它们存储在 Redis 中,以便以后可以更快地访问它们。
完成后,索引会将数据存储到 Redis 中。数据基本上是按项目和位置汇总的,我们保留最高买入价和最低卖出价以及所有其他额外数据。通过这样做,我们可以在他们不同的位置获得所有物品的价格。
为了存储这些数据,我们使用 JSON 堆栈,因此我们可以有一个索引并简化以后的搜索。
我们还将这些条目的 TTL 设置为 24 小时。通过这样做,我们确信未更新的数据将从 Redis 中删除,并且还充当过时的缓存,以防索引工作流出现问题。
最后,服务将带有区域的事件发送到流indexationFinished
2.调度
调度程序监听发送到流indexationFinished的事件,一旦消息到达,它将确定在什么时间开始为给定区域建立新索引。
为此,它将读取存储到与该区域相关的时序表中的数据,以计算新索引何时到期。
对于这个演示,我保持数学简单。但想法是,如果在最后 5 分钟内有 API 调用,则需要在 5 分钟内安排索引。如果最近一小时有 API 调用,则索引需要安排在 10 分钟内。否则,我们将其延迟 1 小时。
然后将此信息存储在排序集中,其分数等于先前计算的时间戳。
3.延迟器
我们现在有一个排序集中的任务,我们需要确定何时真正开始索引。由于集合中的数据以最低时间戳排序,我可以只取第一项并查看开始索引的时间是否正确。
如果没问题,延迟器将发送一个带有流indexationAdd中区域的事件,并从排序集中删除该条目。
4. API
现在后台任务正在运行,我们可以将聚合数据显示给 API 的用户。
为此,我们提供了一个端点/market,它需要location作为查询参数并接受一些其他查询参数来帮助过滤返回的数据。
//List of query parameters
location #regionName, systemName, locationName, regionId, systemId, locationId
minBuyPrice
maxBuyPrice
minSellPrice
maxSellPrice
进入全屏模式 退出全屏模式
这些条目将与 Redis 的搜索引擎一起用于以下索引
FT.CREATE denormalizedOrdersIx
ON JSON
PREFIX 1 denormalizedOrders:
SCHEMA
$.regionId AS regionId NUMERIC
$.systemId AS systemId NUMERIC
$.locationId AS locationId NUMERIC
$.typeId AS typeId NUMERIC
$.buyPrice AS buyPrice NUMERIC
$.sellPrice AS sellPrice NUMERIC
$.buyVolume AS buyVolume NUMERIC
$.sellVolume AS sellVolume NUMERIC
$.locationName AS locationName TEXT
$.systemName AS systemName TEXT
$.regionName AS regionName TEXT
$.typeName AS typeName TEXT
$.locationNameConcat AS locationNameConcat TEXT
$.locationIdTags AS locationIdTags TAG SEPARATOR ","
进入全屏模式 退出全屏模式
// Search with query parameter location that is a string
FT.SEARCH denormalizedOrdersIdx @locationNameConcat:(Dodixie IX Moon 20) @buyPrice:[5000000.00 10000000] @sellPrice:[6000000 20000000] LIMIT 0 10000
// Search with query parameter location that is a number
FT.SEARCH denormalizedOrdersIdx @locationIdsTag:{60011866} @buyPrice:[5000000.00 10000000] @sellPrice:[6000000 20000000] LIMIT 0 10000
进入全屏模式 退出全屏模式
有了它,我们可以轻松地只提供用户想要的数据。
正如我们所见,查询参数 location 接受字符串或数字。这样做是为了减少用户获取他正在搜索的区域、系统或位置的确切 ID 的需要。
对 API 进行的每个调用都会将带有该区域的事件apiEvent发布到 pub/sub。
5.心跳
该服务仅在调用 API 时侦听发布到apiEvent中的事件以保存到与区域相关的时序表中。
6.刷新
正如我们之前看到的,来自没有大量访问的区域的数据是索引器的速度很慢。
为了帮助减少这个问题,我看看一个地区是否需要追赶。
为此,我查看调度程序创建的排序集indexationDelayed,如果该区域存在一个条目,并且在现在(收到事件时)和接下来的 5 分钟之间得分。
如果没有,我将事件发送到带有区域的流indexationCatchup中,因此调度程序可以安排新的索引。
为了防止过多的追赶,我还在 10 分钟内存储了该地区所要求的追赶
7.安排追赶
这部分工作流程也是由调度器完成的。它还监听indexationCatchup,一旦收到事件,我们直接在流indexationAdd中创建一个条目,以便索引可以尽快开始。
投稿类别:
微服务专家
我的项目的视频解释器
使用的语言
戈朗
链接到代码
 hyoa/wall-eve
hyoa/wall-eve
Wall-Eve
Wall-Eve 是一个提供来自游戏 Eve-Online 市场的聚合数据的 API。
Eve-Online 是一款 MMORPG,其中交易是游戏的一个重要方面。开发人员提供了很多端点来帮助第三方工具的开发,但市场的端点不提供聚合数据,这意味着大多数创建市场应用程序的开发人员必须提取数据,聚合然后使用它。
Wall-Eve 是解决这个问题的一个可能方法。它聚合数据并让人们使用此应用程序公开的 API 检索信息。他们甚至可以使用一些查询参数进行过滤。
应用程序将定期刷新数据以提供最新数据信息。

概述视频(可选)
这是一个简短的视频,解释了该项目以及它如何使用 Redis:
工作原理
检查dev.to以获得关于如何工作的详细帖子......
在 GitHub 上查看
其他资源/信息
你在这里玩它:
http://api.wall-eve.tech/market
http://swagger.wall-eve.tech/
-
查看Redis OM,用于将 Redis 用作多模型数据库的客户端库。
-
使用RedisInsight在 Redis 中可视化您的数据。
-
注册一个免费的 Redis 数据库.

Redis社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献1540条内容
已为社区贡献1540条内容

所有评论(0)