

Introduction
Many schools across the world have transitioned into fully online experiences with the recent pandemic. With each school's backend stack witnessing new highs in usage, serverless solutions are more important than ever. Here's a walkthrough on how to create a robust school management system using Auth0 for identity management and FaunaDB as a serverless database. FaunaDB allows us to create globally distributed databases with virtually no traffic limits. You can perform as many reads/writes as you desire.
The School Management System we're building (named "skulment") has three categories of users: students, teachers and managers. Below is a basic description of what each role should be able to do.
Users
Students should be able to:
register/unregister for courses
see courses they registered for
see the teachers assigned to each of their courses
Teachers should be able to:
see all students taking their course
see all the courses they manage
Managers should be able to:
read and modify Student, Course and Teacher resources
This is a basic set of rules for each role. In a real-world scenario, there would be more protections and rules on each role. We will work with this for simplicity sake.
Architecture
For many years now, No-SQL databases have severely lacked relational database features. The ability to model relationships allows for healthy and stable maturation of databases, as applications are iterated on. FaunaDB's founders knew that support for relational data was a must if FaunaDB were to be competitive.
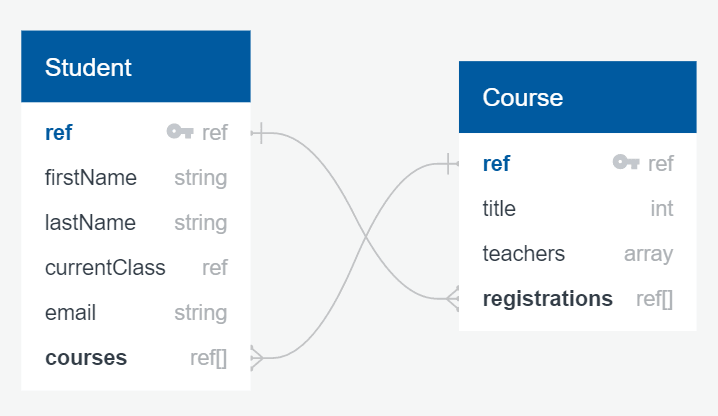
In this application, we'll be modelling for one-to-many and many-to-many relationships. Aside from our users, we'll also need to model for Courses and Classes. Below is a diagram of our soon to be school management system. Please note that real-world usage will likely involve larger data structures, but for the sake of this example, we'll keep things simple.
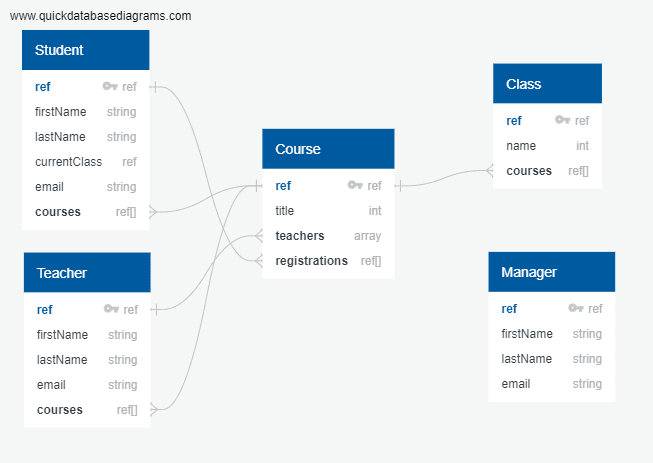
Relationships
Students to Courses (Many : Many): A student can have many courses and a course can have many students
Teachers to Courses (Many : Many): A teacher can have many courses and a course can have multiple teachers
Class to Courses (1 : Many): A course can only belong to one class and a class can have many courses
Getting Started
We're going to start with our backend resources, FaunaDB and Auth0 in particular, and then make our way to the more front-facing elements of this project, with ReactJS. For convenience sake, I've written an example environment file (.env) which you can copy to create your own, along with a node.js script to scaffold the backend. To use them, you will need to clone my repo and initialize the frontend like so:
git clone https://github.com/vicradon/skulment-demo.git
cd skulment-demo
yarn # or `npm i` if you prefer
cp .env.example .env
Database Setup
FaunaDB as a serverless database allows us to focus on our business logic and worry less about setup and maintenance. Creating a database is as simple as running a CreateDatabase({name:"some_db"}) command. All maintenance is taken care of behind the scenes by engineers and automated DevOps at FaunaDB. The hassles associated with other databases, such as choosing regions and configuring storage, are nonexistent with FaunaDB; which is global/multi-region by default
Create a fauna account here if you don't have one already. We'll make use of the fauna shell which allows us to create/modify resources on FaunaDB. Note that Fauna also has a web shell in the cloud console, with a great user interface for debugging FQL.
npm install -g fauna-shell
fauna cloud-login
Great! Now, let's create our first database.
fauna create-database skulment_demo && fauna shell skulment_demo
This launches a repl-like environment where we can execute FQL queries. While many databases which don’t have SQL interfaces opt for simple CRUD APIs, FaunaDB offers the Fauna Query Language (FQL), a functional database query language. If you’re familiar with SQL, here’s a fantastic comparison between the two. FaunaDB turns our data into an API either through its GraphQL client or through FQL. This means you don’t have to build APIs from scratch, just to use your database in an application! We can now create our first collection.
CreateCollection({ name: "Students" })
# Should return something like this…
# {
# ref: Collection("Students"),
# ts: 1600697704360000,
# history_days: 30,
# name: "Students"
# }
This will create a Collection named Students. A FaunaDB Collection is similar to a table in a relational database. However, it stores documents instead of rows and has loose data structure requirements by default (enforcement can be built). We will now create other Collections in the shell, just as we did before.
# `fauna shell skulment_demo` if not in shell already
CreateCollection({name: "Teachers"});
CreateCollection({name: "Managers"});
CreateCollection({name: "Courses"});
CreateCollection({name: "Classes"});
All 5 of our Collections are currently empty. Let's see how we can fill the void by adding a student to the Students collection.
Create your first document!
We will add a student document to the Students collection using the FQL Create function.
Create(Collection("Students"), {
data: {
firstName: "Wangari",
lastName: "Maathai",
email: "wangari.maathai@skulment.edu",
},
});
# should return something like this
# {
# ref: Ref(Collection("Students"), "277574932032913921"),
# ts: 1600974933615000,
# data: {
# firstName: 'Wangari',
# lastName: 'Maathai',
# email: 'wangari.maathai@skulment.edu',
# }
# }
Refs
When we inspect the returned JSON, we see a ref field. A reference (or "ref" for short) is a native FaunaDB object used to uniquely identify a Document along with its Collection and can be used much like a foreign key. The 18 digit number within the ref is the document's id. Although it's possible to extract a document's id and store it for other purposes, it's highly encouraged to keep it paired with its respective Collection name, as the id alone isn't enough to be a pointer or retrieve a Document.
Using the Paginate and Documents functions, we can retrieve the ref of our recently created Student (since it's the only document in the collection so far).
Paginate(Documents(Collection("Students")))
# Should return something like this
# { data: [ Ref(Collection("Students"), "277574932032913921") ] }
If we pretend that our database is a physical library, where you can read or borrow books, and that all of its books are collections: the Collection function returns a book's location (or "ref") in the library, the Documents function opens the book, and the Paginate function reads a page from the book. However, in this case, a book's page is an array of document refs, not the entirety of a document's data. Note that Paginate can return data other than refs when using custom Indexes (more on this later). For now, we can read an entire document by copy-pasting our first Student's ref into a Get function.
Get(Ref(Collection("Students"), "277574932032913921"))
NB: The ref that should be in your Get function should be the one from your terminal, not the one above.
Update and Delete
To mutate this document, we use the Update function. The Update function takes in a ref and the fields to be written to and returns the modified document.
Update(Ref(Collection("Students"), "277574932032913921"), {
data: {
email: "wangari-nobel@skulment.edu"
}
}
)
# returns the full document
To delete this document we call the FQL delete function on its ref like so
Delete(Ref(Collection("Students"), "277574932032913921"))
Populate Collections with demo data
Now that we know how to CRUD documents using FQL, we will use the populate-collections.js script, in the scripts directory of the project, to populate all of the newly created collections with demo data; creating:
- 50 students
- 10 teachers
- 2 managers
- 20 courses and
- 6 classes.
Since we are using a script, it means we are manipulating the database outside the shell. For this, we need the FaunaDB JavaScript driver and a server key.
The JavaScript driver is an npm package that allows us to use FQL within a JavaScript file. The server key is a key that bypasses all permission checks within its database. It must be handled with care.
You can always invalidate server keys with the Delete function or on the Fauna dashboard if they have been compromised. See image below.
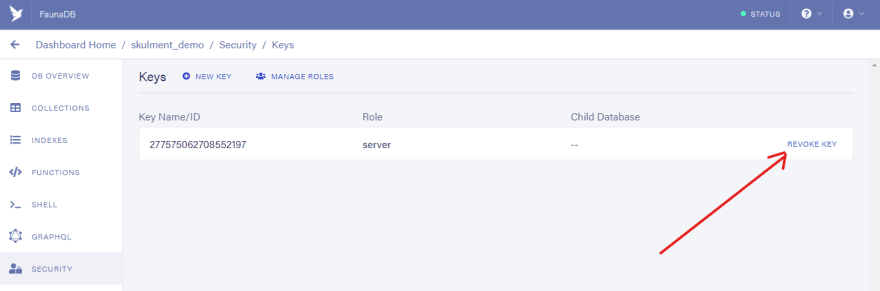
Run this command in the shell and copy the secret from the result.
CreateKey({ role: "server" })
# Returns something like this
# {
# ref: Ref(Keys(), "278091949991264787"),
# ts: 1601468000353000,
# role: 'server',
# secret: 'fnAD2_sntiACE_xHweiTXMNvy7Z4vJ2OkA7yZAd1', # copy this
# hashed_secret: '$2a$05$AjuS2MrHwgBCUKepWp/KLOniI4hinzLbUqIHf1PZsOlu3qbSncgr.'
# }
Paste the secret into the FAUNA_SERVER_SECRET key of your .env file. Afterwards, open a new terminal and run the command below from where you cloned into the repo earlier.
node scripts/populate-collections
# outputs
# Successfully created collections on FaunaDB
If no errors are thrown, you should be able to see the generated documents in the newly created collections
Map(
Paginate(Documents(Collection("Students"))),
Lambda("ref", Get(Var("ref")))
);
# Run this for any collection you'd like, to verify the script worked
The populate-collections script was a pleasure to write because FQL is a well-designed language, where functional programmers will feel right at home. Although we used the JavaScript driver, FaunaDB also offers drivers for other languages, such as Scala, Go, Python, Java, etc. Because FQL is so flexible and accommodating, developers can shift a majority of their business/backend logic onto Fauna’s servers, where FQL is executed in fully ACID distributed transactions. Composition and code reuse is also a breeze with User Defined Functions (UDF) and Indexes, more on these later. With FQL, it’s never been easier to write serverless backend code; yes, even easier than traditional serverless functions, as deployment processes are nonexistent.
Indexes
If we don’t know a document’s ref, we can use other fields such as email or firstName to search for a document, using a FaunaDB Index. Indexes can also be used to sort and reverse the refs and data of specific documents. Finally, they can also impose constraints, such as uniqueness, preventing duplicate results from being returned. Learn more about indexes here.
Index example: getting a user by email
The user documents of this app are in the Students, Teachers and Managers collections. This means that in building this index, we will include those collections as the index's source, which is to be searched on. The fields to be searched will be put in the terms property. The user's email is searched in the data.email property of their document, which in FQL, is written as an array path: ["data", "email"].
CreateIndex({
name: "users_by_email",
source: [
{collection: Collection("Students")},
{collection: Collection("Teachers")},
{collection: Collection("Managers")},
],
terms: [{ field: ["data", "email"] }]
});
# should give a result similar to
# {
# ref: Index("users_by_email"),
# ts: 1601538868340000,
# active: false,
# serialized: true,
# name: "users_by_email",
# source: [
# {
# collection: Collection("Students")
# ...
This index might take some time to build because we already have some data in the searchable collections. You can check the progress of the build on the Fauna dashboard or by the "active" field on the index's document (all records in FaunaDB are documents, even native ones!).
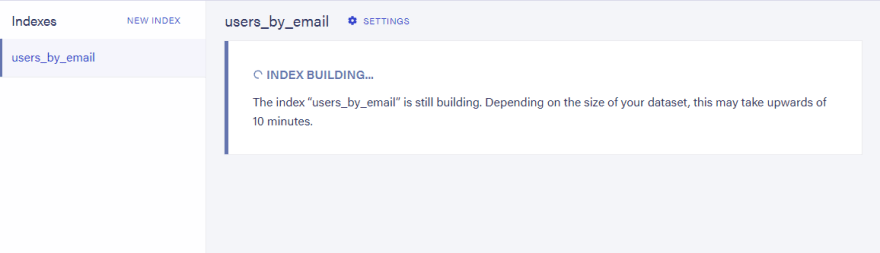
When the index is ready for use, we can get one of the created users using the FQL Match function and the user's email.
# Can also be used with "teacher1@skulment.edu" and "manager1@skulment.edu"
Get(Match(Index("users_by_email"), "student1@skulment.edu"))
# Should return something like this
# {
# ref: Ref(Collection("Students"), "277574932032913921"),
# ts: 1600974933615000,
# data: {
# "firstName": 'Student',
# "lastName": 'Default',
# "email": 'student1@skulment.edu',
# "currentClass": Ref(Collection("Classes"), "277915816413890055"),
# "courses": [
# Ref(Collection("Courses"), "277915818192273921")
# ]
# }
# }
Notice the currentClass and courses fields. They both contain refs, which in this case, are essentially foreign keys. They establish Student - Class and Student - Course relationships. The populate-collections script we used earlier, passed course and class refs to the code responsible for creating students, establishing their relationships.
Aside from our use case, Indexes can have many more applications, such as text search, sorting, reversing and even geo-search!
Auth0 Setup
Now that we've set up the foundation of our database, we need to write the logic that will handle authentication on Auth0. Auth0 allows us to define authentication rules which will restrict authentication to emails present on the FaunaDB database. Within the same rule, we will generate a FaunaDB secret and attach it to their user document (e.g. Teacher). The secret will ensure that users are only able to read/mutate resources defined within their role (more on this later).
To get started, create a free Auth0 account here and create a single page application. You can choose any name for your tenant and app. After your application has been created, create a new empty rule.
Complete the rule creation by inserting this piece of code which returns a user object + Fauna secret. We will need to add our Fauna database server secret in Auth0's environmental configuration, similar to what I did below.
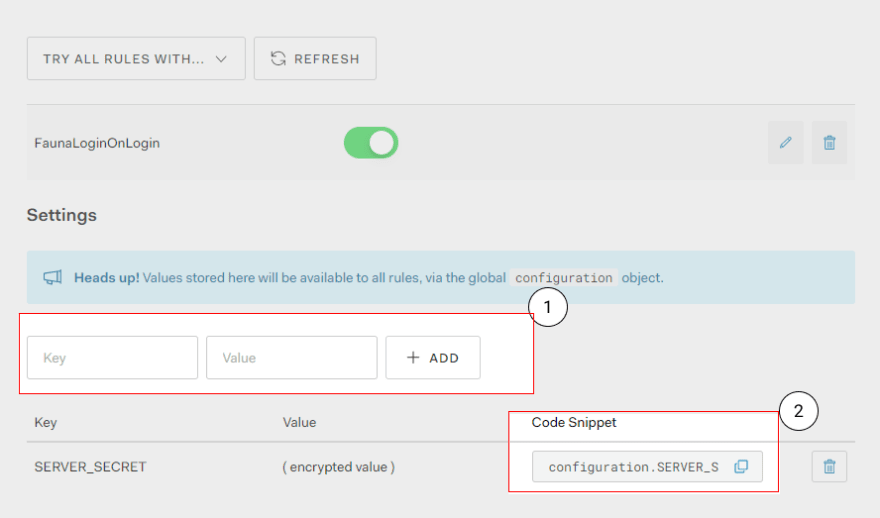
Sections of the script
Let's break the script into sections to be able to understand what it does.
Section 1: Initialization
async function loginFaunaOnUserLogin(user, context, callback) {
const { Client, query:q } = require("faunadb@2.11.1"); // from Auth0 registry. See https://auth0.com/docs/rules
const client = new Client({
secret: configuration.SERVER_SECRET,
});
// more code below...
The first few lines are for set up. We require the FaunaDB javascript driver and also set up our client using our Fauna server secret.
Section 2: Generate credential if user's document exists
// inside loginFaunaOnUserLogin(), more code above...
try {
/* return user document if present in the database */
let user_from_fauna;
try {
user_from_fauna = await client.query(
q.Get(q.Match(q.Index("users_by_email"), user.email))
);
} catch (error) {
throw new Error("No user with this email exists");
}
/* create a secret from the user's ref in the Tokens collection */
const credential = await client.query(
q.Create(q.Tokens(null), { instance: user_from_fauna.ref })
);
// more code below...
In the second section, we check that the user trying to sign-in is in the database. This check is done using the users_by_email index. The FQL Match function helps us match search queries to an index. The FQL Get function is then used to return the matched results, in this case, a user document. A credential is created for a specific user, using the Create function on the Tokens collection. Now we will extract the secret from the credential object which users will use to make DB queries.
Section 3: Attach user_metadata to returned object
/* Attach the secret, user_id and role to the user_metadata */
user.user_metadata = {
secret: credential.secret,
user_id: credential.instance.id,
role: user_from_fauna.ref.collection.id.toLowerCase().slice(0, -1),
};
/* The custom claim allows us to attach the user_metadata to the returned object */
const namespace = "https://fauna.com/"; // fauna because we are using FaunaDB
context.idToken[namespace + "user_metadata"] = user.user_metadata;
auth0.users
.updateUserMetadata(user.user_id, user.user_metadata)
.then(() => callback(null, user, context))
.catch((err) => callback(err, user, context));
} catch (err) {
callback(err, user, context);
}
}
In this section, we attach the secret, user_id and user's role to the user's metadata object. Afterwards, we use a custom claim to attach user_metadata to the returned user object. A custom claim is necessary because Auth0 will filter out any non-namespaced values. Finally, we exit using the callback.
Connecting the React app to Auth0
Now we need to tell Auth0 about our React app. Navigate to your application settings tab on the Auth0 dashboard and add the URL (http://localhost:3000) to the
- Allowed Callback URLs
- Allowed Logout URLs
- Allowed Web Origins fields
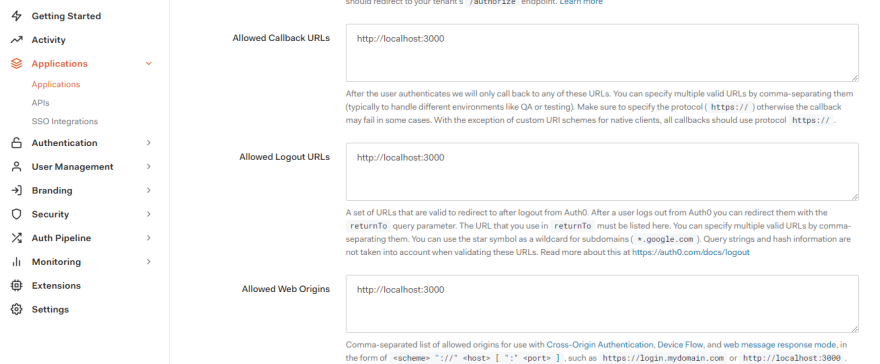
Ensure you click the Save Changes button at the bottom of the page.
You need the Client ID and the Domain from the top of the application settings page. Copy those values and fix them in REACT_APP_CLIENT_ID and REACT_APP_DOMAIN keys of the .env file of your React application.
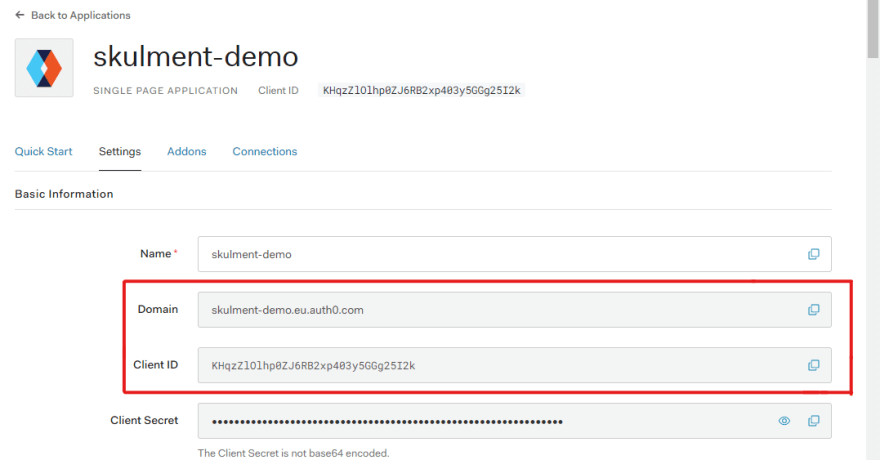
Restart your development server to ensure the environment variables are picked up.
npm start
Student Section
Authenticating a student
In building out this section, we will create a Student role and construct functions concerning course registration. Recall that the populate-collections script created students, teachers and managers for us to test with. Run the development server and authenticate a student using these details.
Email: student1@skulment.edu
Password: Test1234
After successful signup, try accessing the courses route.

You should see two permission denied toasts. This is because we haven't given this student the privilege to read from the courses collection. To assign this privilege, we use a custom role.
Defining the student's role
The Student role is a custom role that sets resource access rules for a student. In addition to its authentication system, FaunaDB offers an authorization system out of the box which implements Attribute Based Access Control (ABAC). The secret/role attached to a user is only able to do what its rules say. If we don't define a Student role, a user will not be able to do anything with their secret.
The Student role defined below gives a student these privileges:
Reading from and writing to the Courses collection
Reading from the Teachers collection
Reading from the Classes collection
Reading from and writing to the Students collection
The Student role is created using the CreateRole FQL function.
CreateRole({
name: "Student",
privileges: [
{
resource: Collection("Courses"),
actions: { read: true, write: true },
},
{
resource: Collection("Teachers"),
actions: { read: true },
},
{
resource: Collection("Classes"),
actions: { read: true },
},
{
resource: Collection("Students"),
actions: { read: true, write: true },
},
],
membership: [{ resource: Collection("Students") }],
});
# should return something similar to
# {
# ref: Role("Student"),
# ts: 1601542095001000,
# name: "Student",
# privileges: [
# {
# resource: Collection("Courses"),
# actions: {
# read: true,
# write: true
# }
# },
# {
# resource: Collection("Teachers"),
# actions: {
# ...
The Student role is assigned to all members of the Students collection. Try navigating to the courses route to see if the toasts are still thrown. Everything should be working now.
Students are only permitted to read and modify courses, not create them. We can test this restriction, by trying to create a Course. First, obtain the current logged in user’s secret from the running app on the browser.
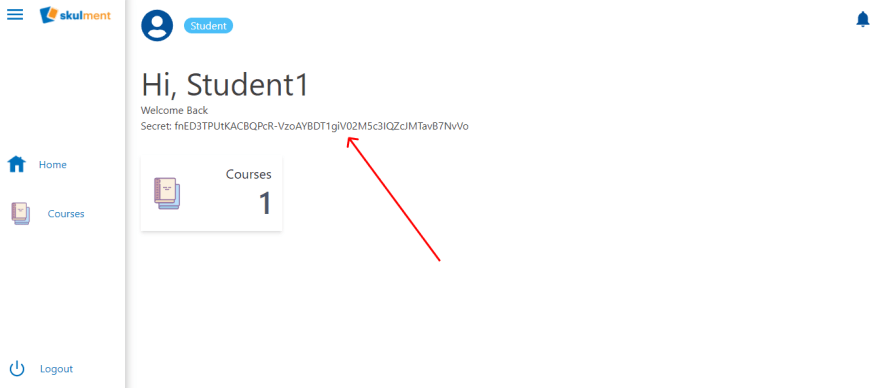
Then fix it in the CURRENT_USER_SECRET key of the .env file. Open a file called create_course_test.js from your scripts directory. Verify that we are attempting to create a document in the Courses collection. Run this script using node scripts/create_course_test. What's the result? Was an error thrown? Check the error description looks similar to
[PermissionDenied: permission denied] {
description: 'Insufficient privileges to perform the action.',
Now run retrieve_courses_test.js. Was any error thrown? All the course documents refs should be retrieved with no errors thrown. It means our role is working.
NB: you should never display a secret in your application. The user's secret displayed here was displayed for convenience sake. You can remove the lines rendering this secret to the UI.
Registering courses
Great job so far. Fun fact! Transactions in FaunaDB avoid pessimistic locks, and instead, use a novel form of optimistic locking inspired by Calvin. . Simply put, this allows for massive concurrency. So at the start of a new semester, where our database could experience a lot of writes, students will be able to register for courses without concurrency errors, delays, etc.. Additionally, if our school supports remote international students, they won’t unfairly experience high latencies when racing to register for a popular course, due to FaunaDB’s globally distributed nature. Now, let’s build some UI!
Select component
We will build our course registration component such that it will support simultaneous course registrations. For this, we will use react-select. In the RegisterCourseModal component, look for a form and add this component below the placeholder text.
<Select
closeMenuOnSelect={false}
components={animatedComponents}
isMulti
options={courses}
value={selected_courses}
onChange={handleChange}
/>
// more code below
We also need to include the onChange handler used by react-select. Add this to the RegisterCourseModal component.
const handleChange = (values, actionMeta) => {
if (actionMeta.action === "remove-value") {
setSelectedCourses(
selected_courses.filter((course) => course !== actionMeta.removedValue)
);
}
if (actionMeta.action === "select-option") {
setSelectedCourses(values);
}
};
We added the if checks so we can remove selected courses. We don’t want students to have to refresh if they want to unselect a course they picked.
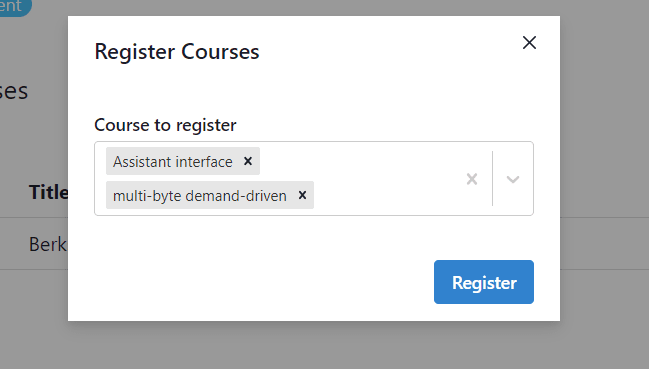
Logic for registering courses
We will now add some logic for registering courses. The codeblock below creates a User Defined Function (UDF). UDFs are great for code we want to keep away from malicious users on the frontend or code involving protected resources. If you're coming from SQL databases, you’ll notice that they are similar to stored procedures. To call a UDF, we use the FQL Call function with params, if any.
Call(Function("some_function_name"), [...params])
Let's analyze the UDF below.
An array of course refs is constructed from the input array of course ids
The registered courses of the student making the request are obtained in the Select function. Identity is used here to get the student's ref. So instead of us passing the student's ref to the UDF, we use Identity. This ensures that a student cannot register courses for other students.
The registrable courses array is obtained by checking courses which aren't contained in the student's courses array.
The (updatedCourseArray) is created by combining the registered and registrable courses arrays.
The updates are done in the Do function. The student's courses array is updated first, before the individual courses to be registered.
Updates to the individual courses are done in the Map function. The student's ref (gotten using Identity) is appended to the registrations array of each registrable course
CreateFunction({
name: "register_course",
body: Query(
Lambda(
"course_ids",
Let(
{
courseRefs: Map(
Var("course_ids"),
Lambda("course_id", Ref(Collection("Courses"), Var("course_id")))
),
registeredCourses: Select(["data", "courses"], Get(Identity()), []),
registrableCourses: Difference(Var("courseRefs"), Var("registeredCourses")),
updatedCourseArray: Append(Var("registeredCourses"), Var("registrableCourses")),
updateOperations: Do([
Update(Identity(), {
data: { courses: Var("updatedCourseArray") },
}),
Map(Var("registrableCourses"), Lambda("ref", Let(
{
registrations: Select(['data', 'registrations'], Get(Var('ref'))),
updatedRegistrations: Append(Var('registrations'), [Identity()])
},
Update(Var('ref'), {
data: { registrations: Var("updatedRegistrations") },
})
)))
])
},
Map(Var("registrableCourses"), Lambda("ref", Get(Var("ref"))))
)
)
),
});
# returns something similar to
# {
# ref: Function("register_course"),
# ts: 1601556750630000,
# name: 'register_course',
# body: Query(Lambda(["course_id", "student_id"], ... ))))
# }
In plain English, this UDF receives an array of course_ids, then updates the registrations and courses arrays of the courses and student documents with refs. In this manner, a many-many relationship is established between the Courses and Students collections.
Now that we have a UDF to handle course registration, we need to update the Student role with the privilege of calling this UDF.
Let(
{
prevPrivileges: Select(["privileges"], Get(Role("Student"))),
newPrivileges: [
{
resource: Function("register_course"),
actions: { call: true },
},
],
},
Update(Role("Student"), {
privileges: Append(Var("prevPrivileges"), Var("newPrivileges")),
}),
);
# output similar to that from UDF creation
Handle registration
So far, we’ve added a select component and defined a UDF. Now we need a trigger for the UDF. We do that in the handleSubmit function. For this project, database queries are written in functions using the FaunaDB JavaScript driver/client. To follow this pattern, we define a function in the Pages/Student/functions.js file called registerCourses.
export const registerCourses = async (courses, secret) => {
const client = new faunadb.Client({ secret });
const course_ids = courses.map((course) => course.value);
const response = await client.query(
q.Call(q.Function("register_courses"), course_ids)
);
return response;
};
As you can see from the function, we initialize a new Client using the user’s secret. Our register_courses UDF requires an array of course ids, so we extract the course ids from the courses parameter. We then query FaunaDB by calling the register_courses UDF with the course_ids as a parameter, where we then wait for the result and store it in response. Finally, we return the response which is the result of the UDF execution.
Navigate back to the RegisterCourseModal component and add this code to the handleSubmit handler.
setRegistering(true);
event.preventDefault();
// new code
registerCourses(selected_courses, secret)
.then((newCourses) => {
toast.success("courses registered successfully");
setRegistering(false);
setCourses([]);
setSelectedCourses([]);
addToCourses(newCourses);
onClose();
})
.catch((error) => {
setRegistering(false);
toast.error(error.message);
});
Try registering a course now
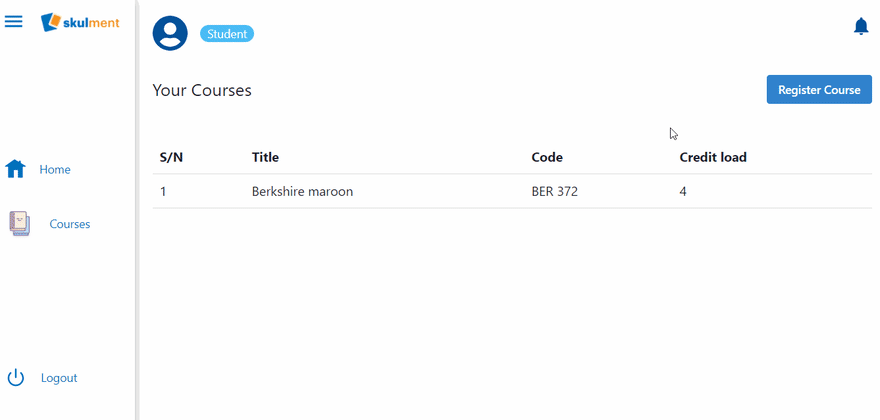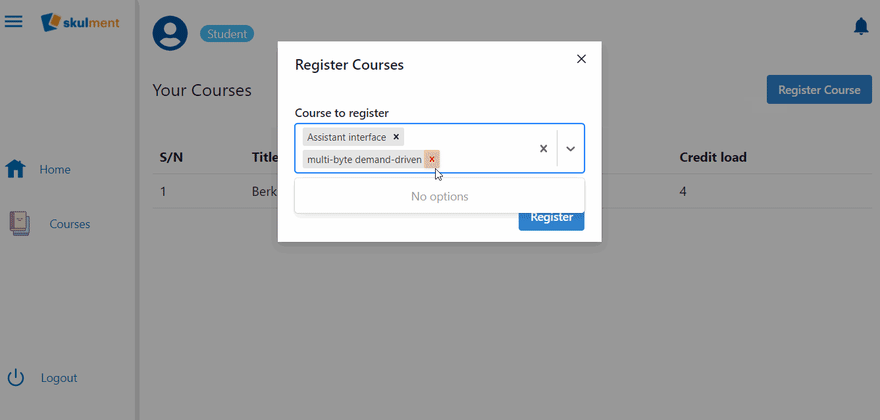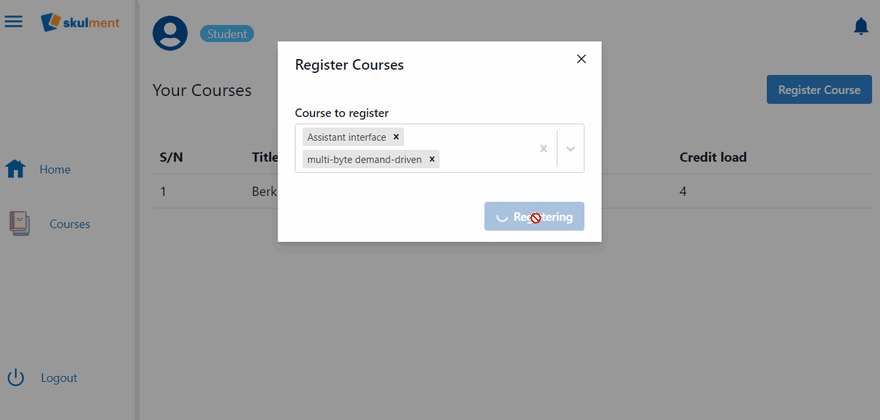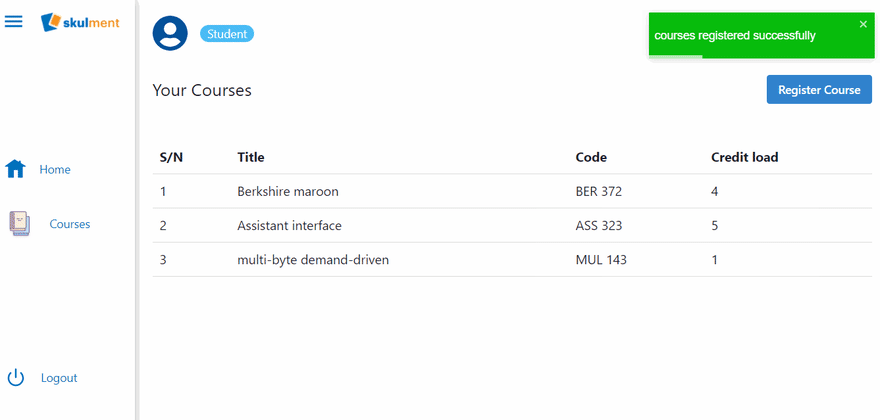
Great! Students can now register for courses.
Unregistering courses
Unregistering courses follow a similar logic to registering courses. The major difference is using the Difference function to return refs not equal to passed in course’s ref.
CreateFunction({
name: "unregister_course",
body: Query(
Lambda(
"course_id",
Let(
{
courseRef: Ref(Collection("Courses"), Var("course_id")),
courses: Select(["data", "courses"], Get(Identity()), []),
registrations: Select(
["data", "registrations"],
Get(Var("courseRef")),
[]
),
updatedCourseArray: Difference(Var("courses"), [Var("courseRef")]),
updatedRegistrationsArray: Difference(Var("registrations"), [
Identity(),
]),
},
Do([
Update(Identity(), {
data: { courses: Var("updatedCourseArray") },
}),
Update(Var("courseRef"), {
data: { registrations: Var("updatedRegistrationsArray") },
}),
])
)
)
),
});
Now, all we need to do is update the Student role to call this UDF, just like we did before. Afterwards, try unregistering a course.
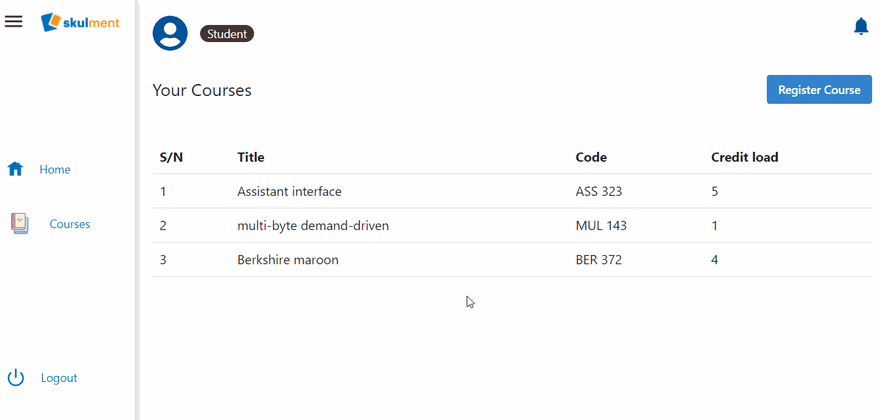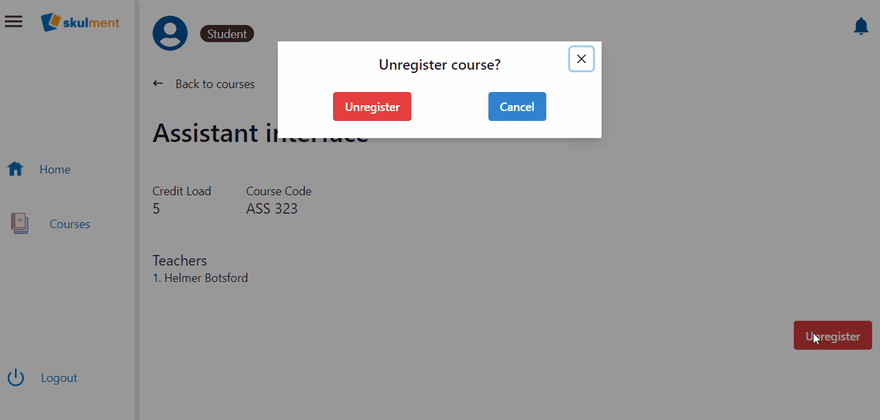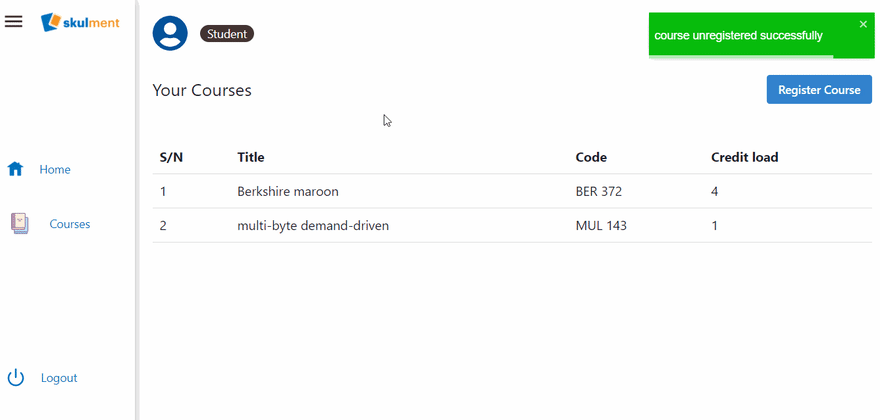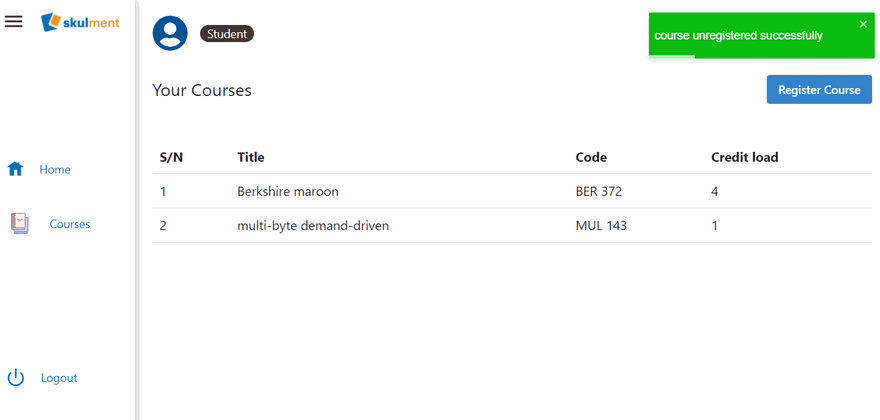
Andddd, we are done with this section! Congrats on making it this far!
Teachers section
To get started, signup a teacher with these details
Email: teacher1@skulment.edu
Password: Test1234
Now, create the Teacher role
CreateRole({
name: "Teacher",
privileges: [
{
resource: Collection("Courses"),
actions: { read: true },
},
{
resource: Collection("Students"),
actions: { read: true },
},
{
resource: Collection("Classes"),
actions: { read: true },
},
{
resource: Collection("Teachers"),
actions: {
read: true,
write: Query(
Lambda("ref", Equals(Identity(), Var("ref")))
),
},
},
],
membership: [
{
resource: Collection("Teachers"),
},
],
});
# The output should be similar to that from the Student role creation
Teacher's dashboard
At the moment, we get a 'permission denied' toast on the dashboard.
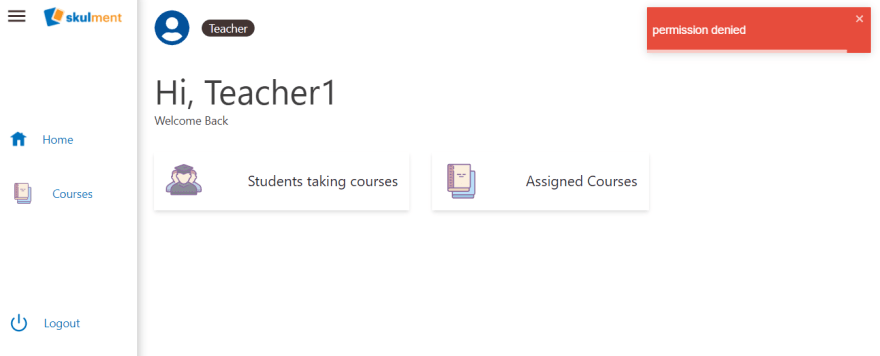
The teacher's dashboard is meant to show the count of the students taking a teacher's courses and the number of courses assigned to the teacher. One way to meet the first requirement is to use a combination of reduce and count. Like the block below. We define a lambda within the reduce that performs a sum between the accumulator and a courses' registrations count.
student_count: q.Reduce(
q.Lambda(
["acc", "ref"],
q.Add(
q.Var("acc"),
q.Count(
q.Select(["data", "registrations"], q.Get(q.Var("ref")), [])
)
)
),
0,
q.Var("course_refs")
)
While the approach above will work, we are better off using an index. An index is a faster way to run queries because we are only searching for the required fields.
CreateIndex({
name: "students_taking_course_by_teacher",
source: Collection("Courses"),
terms: [{ field: ["data", "teachers"] }],
values: [{ field: ["data", "registrations"] }]
})
This index searches the teachers field of a course's document. It then returns the registrations of the course, in this case, the student refs. You may wonder how an index can search an array. When an array is provided as a term, each array element is searched just as scalar fields would be searched. Now, all we need to do is apply the FQL Count function to the returned student refs. The FQL Count function is an aggregate function, similar to Max, Min and Sum. Because FQL offers so many functions, we don't have to do any heavy lifting on our app. All the heavy lifting is done in the cloud by FaunaDB. This means our app stays fast.
Before we proceed, give the teacher the privilege of calling this index the same way we did before (using prevPrivileges and newPrivileges). Finally, verify that these numbers appear on the dashboard.

Managers Section
Managers should be able to perform CRUD operations on Courses, Teachers, Students and Classes. Let's begin by creating the manager role.
CreateRole({
name: "Manager",
privileges: [
{
resource: Collection("Courses"),
actions: { read: true, write: true, create: true, delete: true },
},
{
resource: Collection("Teachers"),
actions: { read: true, write: true, create: true, delete: true },
},
{
resource: Collection("Students"),
actions: { read: true, write: true, create: true, delete: true },
},
{
resource: Collection("Classes"),
actions: { read: true, write: true, create: true, delete: true },
},
],
membership: [
{
resource: Collection("Managers"),
},
],
});
# output should be similar to that of the role creation from the Student and Teacher roles
If we look closely at the manager role, we see that a manager has CRUD privileges on four collections, but it stops at that. A manager cannot create new roles, indexes, collections or databases. The rule of thumb is to only give users the privileges they require. We can have peace of mind that no lousy manager will mess with the school’s database. If by chance one did, FaunaDB allows us to recover historical data and restore our database.
Now, register a manager on the frontend using the following details
Email: manager1@skulment.edu
Password: Test1234
You should be able to see the students, teachers and courses count on the dashboard home page.

Course Deletion
Course deletion is not a straightforward delete operation due to interconnected refs. When a student registers a course, the course ref is saved to their document. The same thing occurs when a course is assigned to a teacher. To ensure that a ref is completely eradicated when deletion occurs, we must handle the logic ourselves in a UDF.
CreateFunction({
name: "cascade_delete_course",
body: Query(
Lambda(
"course_id",
Let(
{
course_ref: Ref(Collection("Courses"), Var("course_id")),
course: Get(Var("course_ref")),
registrations: Select(["data", "registrations"], Var("course"), []),
class_ref: Select(["data", "availableFor"], Var("course")),
teachers: Select(["data", "teachers"], Var("course"), []),
removeRefFromTeachers: Map(
Var("teachers"),
Lambda(
"teacher_ref",
Let(
{
courses: Select(["data", "courses"], Get(Var("teacher_ref")), []),
updated_courses_for_teacher: Difference(Var("courses"), [Var("course_ref")])
},
Update(Var("teacher_ref"), {
data: { courses: Var("updated_courses_for_teacher") },
})
)
)
),
removeRefFromStudents: Map(
Var("registrations"),
Lambda(
"student_ref",
Let(
{
courses: Select(["data", "courses"], Get(Var("student_ref"))),
updated_courses_for_student: Difference(Var("courses"), [Var("course_ref")])
},
Update(Var("student_ref"), {
data: { courses: Var("updated_courses_for_student") },
})
)
)
),
removeRefFromClasses: Let(
{
courses: Select(["data", "courses"], Get(Var("class_ref"))),
updated_courses_for_class: Difference(Var("courses"), [Var("course_ref")])
},
Update(Var("class_ref"), {
data: { courses: Var("updated_courses_for_class") },
})
),
deleteCourse: Delete(Var("course_ref")),
},
{ status: "success" }
)
)
)
});
Now, give the Manager role the privilege to call this UDF using the prevPrivileges - newPrivileges pattern, like we've done before. Finally, we can test our UDF by assigning a course to a teacher, then deleting that course on the UI. The course's reference will be removed from the teacher's assigned courses. See the demonstration below.
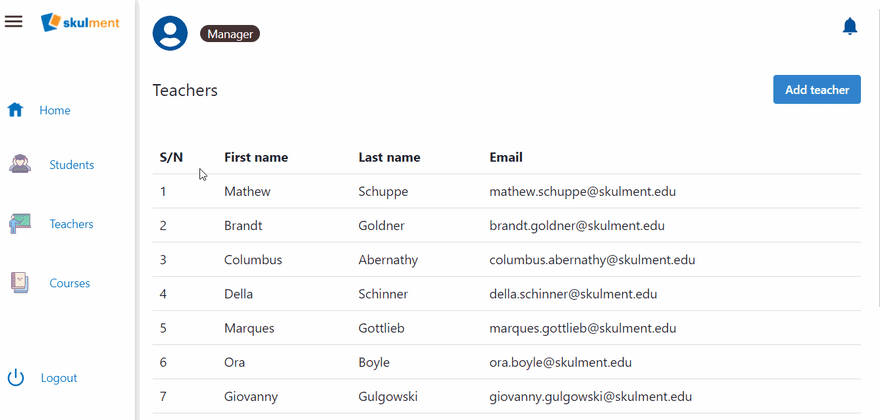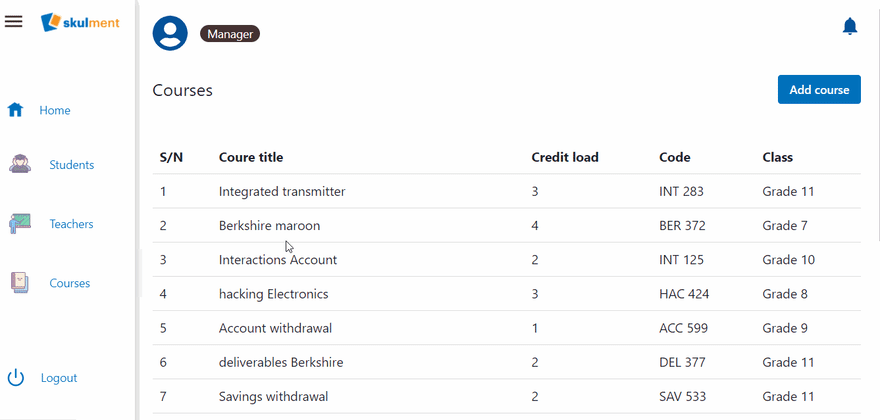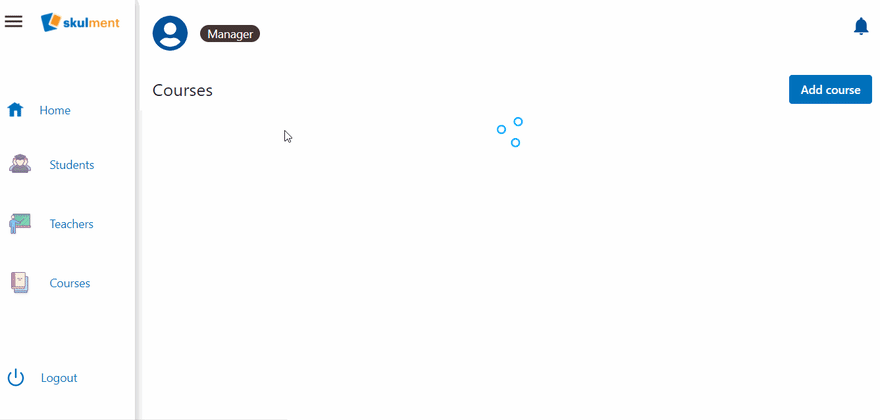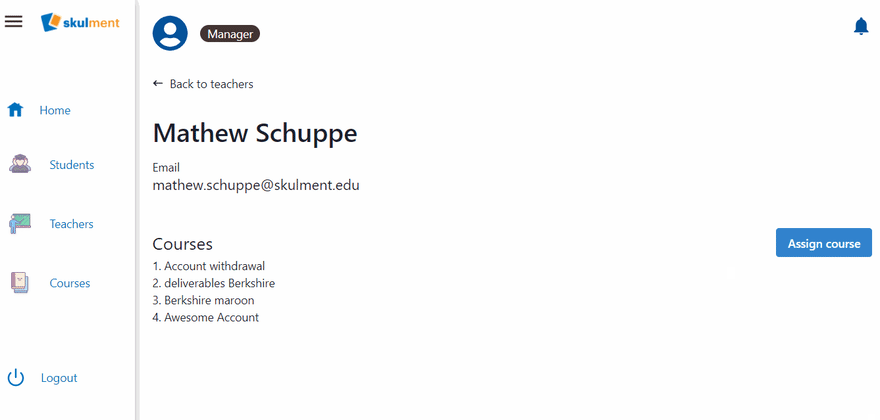
Wrap up

Wow, wow, wow! You made it to the end. I'm so proud of you! Give yourself a pat on the back. It's been a long journey of roles, UDFs and awesomeness. Let's review what we learned in this article
Setting up a FaunaDB database
Using Auth0 rules
Working with FaunaDB Indexes
Working with roles in FaunaDB
Creating and calling UDFs
At this point, we have an MVP-like app. But our app is lacking some essential features such as student assignments, assessment interfaces, notifications and fine-grained role protections. I challenge you to add these functionalities on your own. You can DM me your creations @vicradon on Twitter. You can also open a pull request on the repo.
If you’ve worked with other databases, you’ve probably noticed that FaunaDB allows you to get started as fast as possible. It doesn’t just end there. As our school admits more students and student numbers reach the thousands, we won’t have to worry about scalability because FaunaDB is designed to scale automatically. If it hasn’t struck you yet, we just built a full-stack app with authentication and access control, all without building an old-school backend! I hope you see the power FaunaDB provides, for developing robust applications with global coverage and low latencies.
Where to go from here?
To properly learn FQL you can take a look at this 5 part series. After getting your hands dirty with FQL, you should check out this post on a Twitter clone known as Fwitter. Fwitter was built with the intention of showing developers how FaunaDB can be applied to a real-world project, like this one. You could also peruse this Awesome FaunaDB Github repo for FaunaDB resources created by the community.
Thanks for reading. Adios!




 已为社区贡献7744条内容
已为社区贡献7744条内容

所有评论(0)