
Spark大数据处理(一) Spark的Scala和python脚本环境搭建
环境准备spark-hadoopjdk1.8Scalapython(因为我使用的是 ubuntu x64 linux, python在系统安装就已经配置好)安装linux下的第三方软件应该安装在/opt目录下,约定优于配置,遵循这一原则是良好的环境配置习惯。进入tgz包所在的目录将tgz包复制到我们的安装路径sudo mv .... /opt/然后进入/opt,对我们的安装包进行解压:ta
·
环境准备
- spark-hadoop
- jdk1.8
- Scala
- python(因为我使用的是 ubuntu x64 linux, python在系统安装就已经配置好)
安装
linux下的第三方软件应该安装在/opt目录下,约定优于配置,遵循这一原则是良好的环境配置习惯。进入tgz包所在的目录将tgz包复制到我们的安装路径
sudo mv .... /opt/然后进入/opt,对我们的安装包进行解压:
tar -zxvf ***.tgz 然后根据我们安装的路径设置环境变量
sudo vim /etc/profile我的配置文件给出,只需要修改相对应的SPARK_HOME,JAVA_HOME,SCALA_HOME即可
export PATH="/usr/local/netbeans/bin:$PATH"
#Seeting JDK environment variable
export JAVA_HOME=/opt/jdk1.8.0_77
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH
#Seeting Scala Scala环境变量
export SCALA_HOME=/opt/scala-2.11.8
export PATH=${SCALA_HOME}/bin:$PATH
#setting Spark Spark环境变量
export SPARK_HOME=/opt/spark-1.6.1-bin-hadoop2.6/
#PythonPath 将Spark中的pySpark模块增加的Python环境中
export PYTHONPATH=/opt/spark-1.6.1-bin-hadoop2.6/python 然后重启计算机使配置文件生效,进入spark的安装目录,进行测试
./bin/spark-shell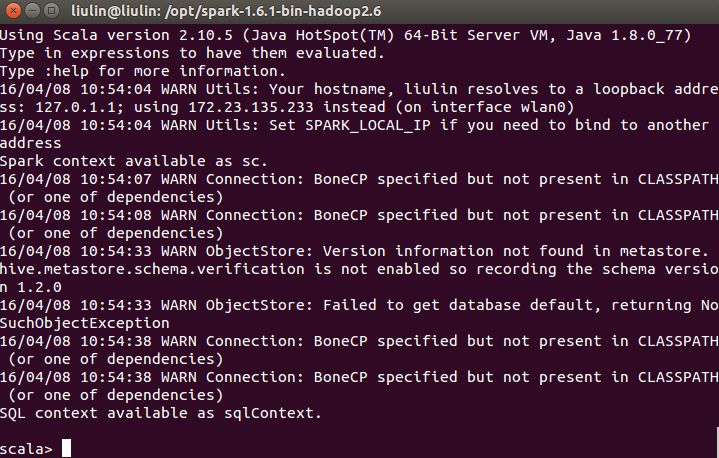
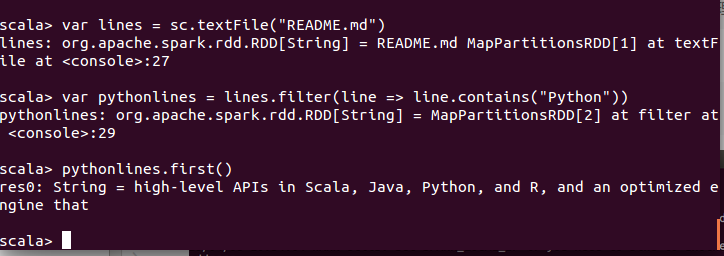
下面给出测试的代码
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)