
fork()和多线程
一、fork()函数 在操作系统的基本概念中进程是程序的一次执行,且是拥有资源的最小单位和调度单位(在引入线程的操作系统中,线程是最小的调度单位)。在Linux系统中创建进程有两种方式:一是由操作系统创建,二是由父进程创建进程(通常为子进程)。系统调用函数fork()是创建一个新进程的唯一方式,当然vfork()也可以创建进程,但是实际上其还是调用了fork()函数。fork()函数
#include <unistd.h>
// On success, The PID of the process is returned in the parent, and 0 is returned in the child. On failure,// -1 is returned in the parent, no child process is created, and errno is set appropriately.pid_t fork (void);
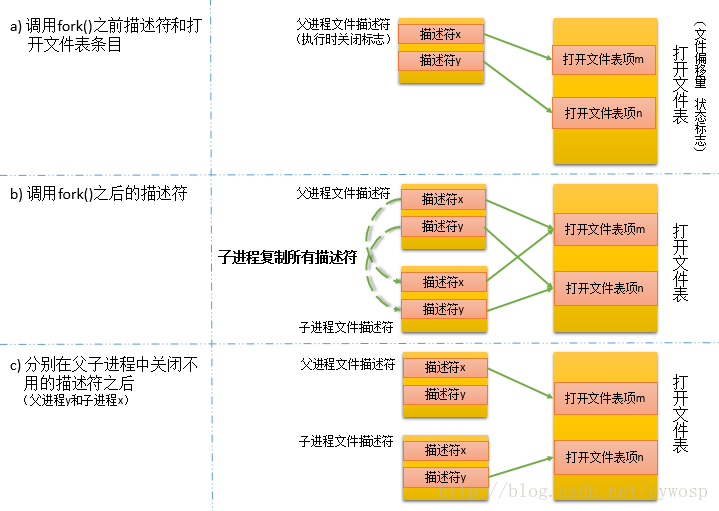
在Linux系统中,常常存在许多对文件的操作,fork()的执行将会对文件操作带来一些小麻烦。由于子进程会将父进程的大多数数据拷贝一份,这样在文件操作中就意味着子进程会获得父进程所有文件描述符的副本,这些副本的创建方式类似于dup()函数调用,因此父、子进程中对应的文件描述符均指向相同的打开的文件句柄,而且打开的文件句柄包含着当前文件的偏移量以及文件状态标志,所以在父子进程中处理文件时要考虑这种情况,以避免文件内容出现混乱或者别的问题。下图为执行fork()调用后文件描述符的相关处理及其变化:
1. 虽然只将发起fork()调用的线程复制到子进程中,但全局变量的状态以及所有的pthreads对象(如互斥量、条件变量等)都会在子进程中得以保留,这就造成一个危险的局面。例如:一个线程在fork()被调用前锁定了某个互斥量,且对某个全局变量的更新也做到了一半,此时fork()被调用,所有数据及状态被拷贝到子进程中,那么子进程中对该互斥量就无法解锁(因为其并非该互斥量的属主),如果再试图锁定该互斥量就会导致死锁,这是多线程编程中最不愿意看到的情况。同时,全局变量的状态也可能处于不一致的状态,因为对其更新的操作只做到了一半对应的线程就消失了。fork()函数被调用之后,子进程就相当于处于signal handler之中,此时就不能调用线程安全的函数(用锁机制实现安全的函数),除非函数是可重入的,而只能调用异步信号安全(async-signal-safe)的函数。fork()之后,子进程不能调用:
- malloc(3)。因为malloc()在访问全局状态时会加锁。
- 任何可能分配或释放内存的函数,包括new、map::insert()、snprintf() ……
- 任何pthreads函数。你不能用pthread_cond_signal()去通知父进程,只能通过读写pipe(2)来同步。
- printf()系列函数,因为其他线程可能恰好持有stdout/stderr的锁。
- 除了man 7 signal中明确列出的“signal安全”函数之外的任何函数。
2. 因为并未执行清理函数和针对线程局部存储数据的析构函数,所以多线程情况下可能会导致子进程的内存泄露。另外,子进程中的线程可能无法访问(父进程中)由其他线程所创建的线程局部存储变量,因为(子进程)没有任何相应的引用指针。
#include <pthread.h>
// Upon successful completion, pthread_atfork() shall return a value of zero; otherwise, an error number shall be returned to indicate the error.// @prepare 新进程产生之前被调用// @parent 新进程产生之后在父进程被调用// @child 新进程产生之后,在子进程被调用int pthread_atfork (void (*prepare) (void), void (*parent) (void), void (*child) (void));
IO模式设置网络编程常见问题总结—IO模式设置,阻塞与非阻塞的比较,recv参数对性能的影响—O_NONBLOCK(open使用)、IPC_NOWAIT(msgrcv)、MSG_DONTWAIT(recv使用)
非阻塞IO 和阻塞IO:
在网络编程中对于一个网络句柄会遇到阻塞IO 和非阻塞IO 的概念, 这里对于这两种socket 先做一下说明:
基本概念:
阻塞IO::
socket 的阻塞模式意味着必须要做完IO 操作(包括错误)才会
返回。
非阻塞IO::
非阻塞模式下无论操作是否完成都会立刻返回,需要通过其他方
式来判断具体操作是否成功。
IO模式设置:
SOCKET
对于一个socket 是阻塞模式还是非阻塞模式有两种方式来处理::
方法1、fcntl 设置;用F_GETFL获取flags,用F_SETFL设置flags|O_NONBLOCK;
方法2、recv,send 系列的参数。(读取,发送时,临时将sockfd或filefd设置为非阻塞)
方法一的实现
fcntl 函数可以将一个socket 句柄设置成非阻塞模式:
flags = fcntl(sockfd, F_GETFL, 0); //获取文件的flags值。
fcntl(sockfd, F_SETFL, flags | O_NONBLOCK); //设置成非阻塞模式;
flags = fcntl(sockfd,F_GETFL,0);
fcntl(sockfd,F_SETFL,flags&~O_NONBLOCK); //设置成阻塞模式;
设置之后每次的对于sockfd 的操作都是非阻塞的。
方法二的实现
recv, send 函数的最后有一个flag 参数可以设置成MSG_DONTWAIT
临时将sockfd 设置为非阻塞模式,而无论原有是阻塞还是非阻塞。
recv(sockfd, buff, buff_size,MSG_DONTWAIT); //非阻塞模式的消息发送
send(scokfd, buff, buff_size, MSG_DONTWAIT); //非阻塞模式的消息接受
普通文件
对于文件的阻塞模式还是非阻塞模式::
方法1、open时,使用O_NONBLOCK;
方法2、fcntl设置,使用F_SETFL,flags|O_NONBLOCK;
消息队列
对于消息队列消息的发送与接受::
//非阻塞 msgsnd(sockfd,msgbuf,msgsize(不包含类型大小),IPC_NOWAIT)
//阻塞 msgrcv(scokfd,msgbuf,msgsize(**),msgtype,IPC_NOWAIT);
读
阻塞与非阻塞读的区别: //阻塞和非阻塞的区别在于没有数据到达的时候是否立刻返回.
读(read/recv/msgrcv):
读的本质来说其实不能是读,在实际中, 具体的接收数据不是由这些调用来进行,是由于系统底层自动完成的。read 也好,recv 也好只负责把数据从底层缓冲copy 到我们指定的位置.
对于读来说(read, 或者recv) ::
阻塞情况下::
在阻塞条件下,read/recv/msgrcv的行为::
1、如果没有发现数据在网络缓冲中会一直等待,
2、当发现有数据的时候会把数据读到用户指定的缓冲区,但是如果这个时候读到的数据量比较少,比参数中指定的长度要小,read 并不会一直等待下去,而是立刻返回。
read 的原则::是数据在不超过指定的长度的时候有多少读多少,没有数据就会一直等待。
所以一般情况下::我们读取数据都需要采用循环读的方式读取数据,因为一次read 完毕不能保证读到我们需要长度的数据,
read 完一次需要判断读到的数据长度再决定是否还需要再次读取。
非阻塞情况下::
在非阻塞的情况下,read 的行为::
1、如果发现没有数据就直接返回,
2、如果发现有数据那么也是采用有多少读多少的进行处理.
所以::read 完一次需要判断读到的数据长度再决定是否还需要再次读取。
对于读而言:: 阻塞和非阻塞的区别在于没有数据到达的时候是否立刻返回.
recv 中有一个MSG_WAITALL 的参数::
recv(sockfd, buff, buff_size, MSG_WAITALL),
在正常情况下recv 是会等待直到读取到buff_size 长度的数据,但是这里的WAITALL 也只是尽量读全,在有中断的情况下recv 还是可能会被打断,造成没有读完指定的buff_size的长度。
所以即使是采用recv + WAITALL 参数还是要考虑是否需要循环读取的问题,在实验中对于多数情况下recv (使用了MSG_WAITALL)还是可以读完buff_size,
所以相应的性能会比直接read 进行循环读要好一些。
注意:: //使用MSG_WAITALL时,sockfd必须处于阻塞模式下,否则不起作用。
//所以MSG_WAITALL不能和MSG_NONBLOCK同时使用。
要注意的是使用MSG_WAITALL的时候,sockfd 必须是处于阻塞模式下,否则WAITALL不能起作用。
写
阻塞与非阻塞写的区别: //
写(send/write/msgsnd)::
写的本质也不是进行发送操作,而是把用户态的数据copy 到系统底层去,然后再由系统进行发送操作,send,write返回成功,只表示数据已经copy 到底层缓冲,而不表示数据已经发出,更不能表示对方端口已经接收到数据.
对于write(或者send)而言,
阻塞情况下:: //阻塞情况下,write会将数据发送完。(不过可能被中断)
在阻塞的情况下,是会一直等待,直到write 完,全部的数据再返回.这点行为上与读操作有所不同。
原因::
读,究其原因主要是读数据的时候我们并不知道对端到底有没有数据,数据是在什么时候结束发送的,如果一直等待就可能会造成死循环,所以并没有去进行这方面的处理;
写,而对于write, 由于需要写的长度是已知的,所以可以一直再写,直到写完.不过问题是write 是可能被打断吗,造成write 一次只write 一部分数据, 所以write 的过程还是需要考虑循环write, 只不过多数情况下一次write 调用就可能成功.
非阻塞写的情况下:: //
非阻塞写的情况下,是采用可以写多少就写多少的策略.与读不一样的地方在于,有多少读多少是由网络发送的那一端是否有数据传输到为标准,但是对于可以写多少是由本地的网络堵塞情况为标准的,在网络阻塞严重的时候,网络层没有足够的内存来进行写操作,这时候就会出现写不成功的情况,阻塞情况下会尽可能(有可能被中断)等待到数据全部发送完毕, 对于非阻塞的情况就是一次写多少算多少,没有中断的情况下也还是会出现write 到一部分的情况.
本文为转载 http://blog.csdn.net/s_k_yliu/article/details/6657956
更多推荐
 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)