
linux heap堆分配
转自:http://www.mamicode.com/info-detail-652351.htmlheap堆分配在用户层面:malloc函数用于heap内存分配void* malloc(size_t size);进程的虚拟内存地址布局: 对用户来说,主要关注的空间是User Space。将User Space放大后,可以
转自:http://www.mamicode.com/info-detail-652351.html
heap堆分配在用户层面:malloc函数用于heap内存分配
void* malloc(size_t size);
进程的虚拟内存地址布局:

对用户来说,主要关注的空间是User Space。将User Space放大后,可以看到里面主要分为如下几段:
- Code:这是整个用户空间的最低地址部分,存放的是指令(也就是程序所编译成的可执行机器码)
- Data:这里存放的是初始化过的全局变量
- BSS:这里存放的是未初始化的全局变量
- Heap:堆,这是我们本文重点关注的地方,堆自低地址向高地址增长,后面要讲到的brk相关的系统调用就是从这里分配内存
- Mapping Area:这里是与mmap系统调用相关的区域。大多数实际的malloc实现会考虑通过mmap分配较大块的内存区域,本文不讨论这种情况。这个区域自高地址向低地址增长
- Stack:这是栈区域,自高地址向低地址增长
heap内存从低地址向高地址生长:malloc函数主要是用于虚拟内存线性地址的分配

另外需要注意的是,由于Linux是按页进行内存映射的,所以如果break被设置为没有按页大小对齐,则系统实际上会在最后映射一个完整的页,从而实际已映射的内存空间比break指向的地方要大一些。但是使用break之后的地址是很危险的(尽管也许break之后确实有一小块可用内存地址)
进程所面对的虚拟内存地址空间,只有按页映射到物理内存地址,才能真正使用。受物理存储容量限制,整个堆虚拟内存空间不可能全部映射到实际的物理内存。Linux维护一个break指针,这个指针指向堆空间的某个地址(线性地址空间)。从堆起始地址到break之间的地址空间为映射好的,可以供进程访问;而从break往上,是未映射的地址空间,如果访问这段空间则程序会报错,即是经典的segmentation fault。
从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk()和mmap()(不考虑共享内存)。
1、brk是将数据段(.data)的最高地址指针_edata往高地址推;
2、mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。
这两种方式分配的都是虚拟内存,没有分配物理内存(不准确,系统调用会执行内核函数,分配内存),在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
这两种进程分配内存方式的区别:
1、对于大块内存申请,glibc直接使用mmap系统调用为其划分出另一块虚拟地址,供进程单独使用;在该块内存释放时,使用unmmap系统调用将这块内存释放(虚拟和物理内存都释放),这个过程中间不会产生内存碎块等问题。
2、针对小块内存的申请,在程序启动之后,进程会获得一个heap底端的地址,进程每次进行内存申请时,glibc会将堆顶向上增长来扩展内存空间,也就是我们所说的堆地址向上增长。在对这些小块内存进行操作时,便会产生内存碎块的问题。实际上brk和sbrk系统调用,就是调整heap顶地址指针(break指针)。
(注意这里所说的内存碎片还是根据物理内存所说的)
由brk分配的heap堆内存是什么时候释放呢?
当glibc发现堆顶有连续的128k的空间是空闲的时候,它就会通过brk或sbrk系统调用,来调整heap顶的位置,将占用的内存返回给系统。这时,内核会通过删除相应的线性区,来释放占用的物理内存。
下面我要讲一个内存空洞的问题:
一个场景,堆顶有一块正在使用的内存,而下面有很大的连续内存已经被释放掉了,那么这块内存是否能够被释放?其对应的物理内存是否能够被释放?
很遗憾,不能。
这也就是说,只要堆顶的部分申请内存还在占用,我在下面释放的内存再多,都不会被返回到系统中,仍然占用着物理内存。为什么会这样呢?
根源:这主要是与内核在处理堆的时候,过于简单,它只能通过调整堆顶指针的方式来调整调整程序占用的线性区;而又只能通过调整线性区的方式,来释放内存。所以只要堆顶不减小,占用的内存就不会释放。
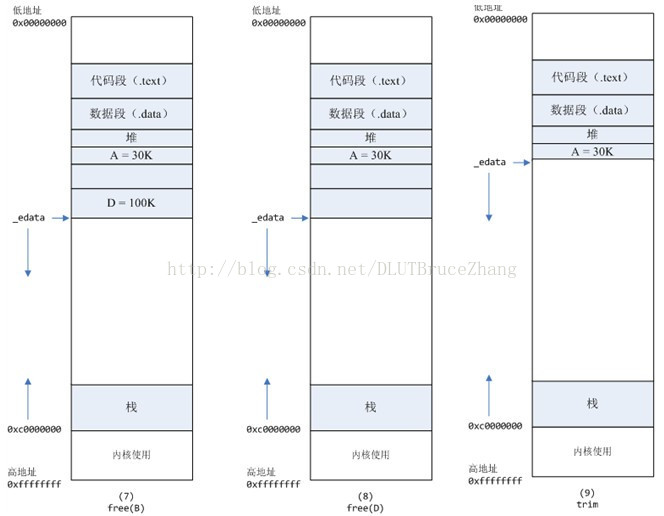
A和D之间的B已经通过free(B),但是此时C的物理内存和线性内存都没有被释放,只是被标记为已经释放的空间,但是break指针没有移动,edata==break?没有回溯。在大多数malloc实现中,free函数释放的内存并不直接归还操作系统(也就是释放物理内存),而是挂接到freelist数组中。 B对应的虚拟内存和物理内存都没有释放,因为只有一个_edata指针,如果往回推,那么D这块内存怎么办呢?
所以如果下次有新的虚拟内存地址分配:首先会查看freelist数组中有没有用过的但是被free的合适空间,如果有,就返还这个线性地址空间。如果没有就从break指针位置开始分配
综上:虚拟线性地址空间也有可能产生碎片(这里所说的碎片就是由于free的内存的虚拟空间没有释放,导致下次分配虚拟空间时候,不能被使用),线性空间和物理内存是一起释放的
内存碎片和内存空洞都是一个意思
问题:既然堆内内存brk和sbrk不能直接释放,为什么不全部使用 mmap 来分配,munmap直接释放呢?
既 然堆内碎片不能直接释放,导致疑似“内存泄露”问题,为什么 malloc 不全部使用 mmap 来实现呢(mmap分配的内存可以会通过 munmap 进行 free ,实现真正释放)?而是仅仅对于大于 128k 的大块内存才使用 mmap ?
其实,进程向 OS 申请和释放地址空间的接口 sbrk/mmap/munmap 都是系统调用,频繁调用系统调用都比较消耗系统资源的。并且, mmap 申请的内存被 munmap 后,重新申请会产生更多的缺页中断。例如使用 mmap 分配 1M 空间,第一次调用产生了大量缺页中断 (1M/4K 次 ) ,当munmap 后再次分配 1M 空间,会再次产生大量缺页中断。缺页中断是内核行为,会导致内核态CPU消耗较大。另外,如果使用 mmap 分配小内存,会导致地址空间的分片更多,内核的管理负担更大。同时堆是一个连续空间,并且堆内碎片由于没有归还 OS ,如果可重用碎片,再次访问该内存很可能不需产生任何系统调用和缺页中断,这将大大降低 CPU 的消耗-----malloc的优势。 因此, glibc 的 malloc 实现中,充分考虑了 sbrk 和 mmap 行为上的差异及优缺点,默认分配大块内存 (128k) 才使用 mmap 获得地址空间,也可通过 mallopt(M_MMAP_THRESHOLD, <SIZE>) 来修改这个临界值。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)