
从 system_call走进linux系统调用
慕课18原创作品转载请注明出处 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000、课程实验:添加系统调用到MenuOS,并用GDB跟踪调试。一、将系统调用uname 添加到MenuOS1、在test.c中添加使用了系统调用uname 的函数的C语言版本和 汇编版本(具体内容)操作很简单
慕课18原创作品转载请注明出处 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
<一>、课程实验:添加系统调用到MenuOS,并用GDB跟踪调试。
一、将系统调用uname 添加到MenuOS
1、在test.c中添加使用了系统调用uname 的函数的C语言版本和 汇编版本(具体内容)
操作很简单,只要把上次的代码直接copy过来(改一下函数名和返回值、参数就可以了),这里就不再罗嗦,直接给出改好的(在csdn里面排版很不方便,就直接用图片了 ):
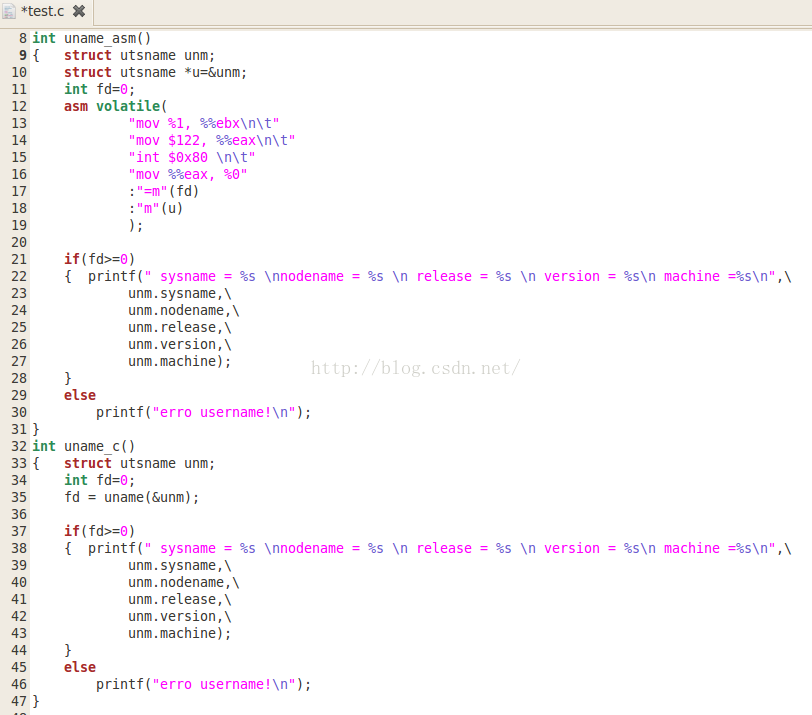
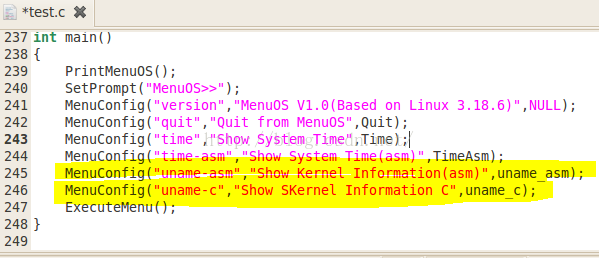
2、将函数代码添加到test.c中后,就重新打包我们的文件系统
- 进入到目录menu中:
- 编译:输出文件为init,-m32 表示 编译成32位,-lpthread 表示的是加载静态库pthread.a
- 打包为文件系统镜像“root@CaiLP:~/linuxkernel/menu# find . | cpio -o -Hnewc |gzip -9 > ../rootfs.img ”
- 用qemu 模拟启动内核,并用rootfs.img 初始化ram disk(-initrd)“ qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img ”
操作结果如图所示:
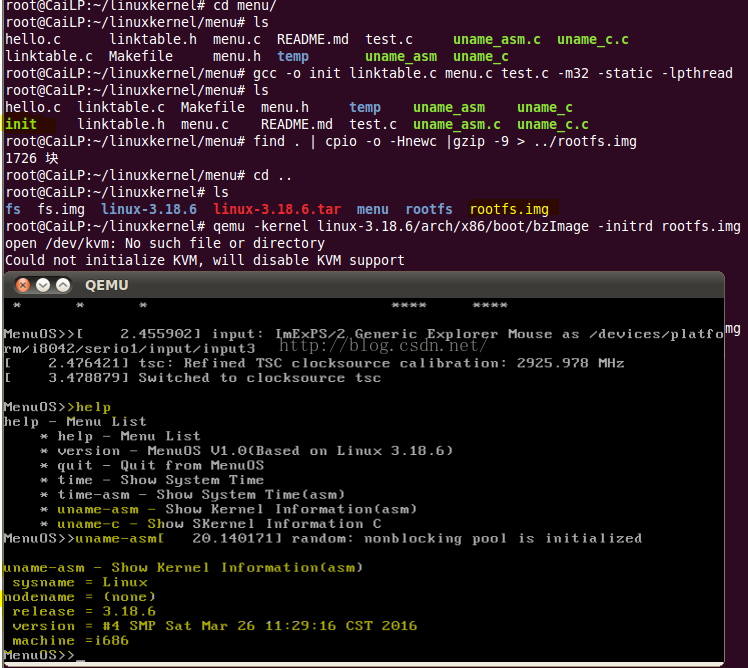
从图中可以看到,内核已经被加载,我们的文件系统也已经被运行,输入help,显示了但钱支持的所有命令,并且我们新添加的uname-asm 和uname-c也已经可用。
输入 uname-asm 后终端打印出了内核的相关参数信息。
3、用GDB跟踪系统调用
- 在终端输入:qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S (指令的解释请参看上一篇 这里不赘述)
- 然后在打开一个终端,输入gdb;
- 在新打开的终端中输入:file vmlinux 加载符号集
- 输入 target remote:1234 链接端口
- 输入 :break sys_newuname 调用uname系统调用处设置断点, sys_newuname 为uname在内核中的调用名。
操作的结果如图所示: 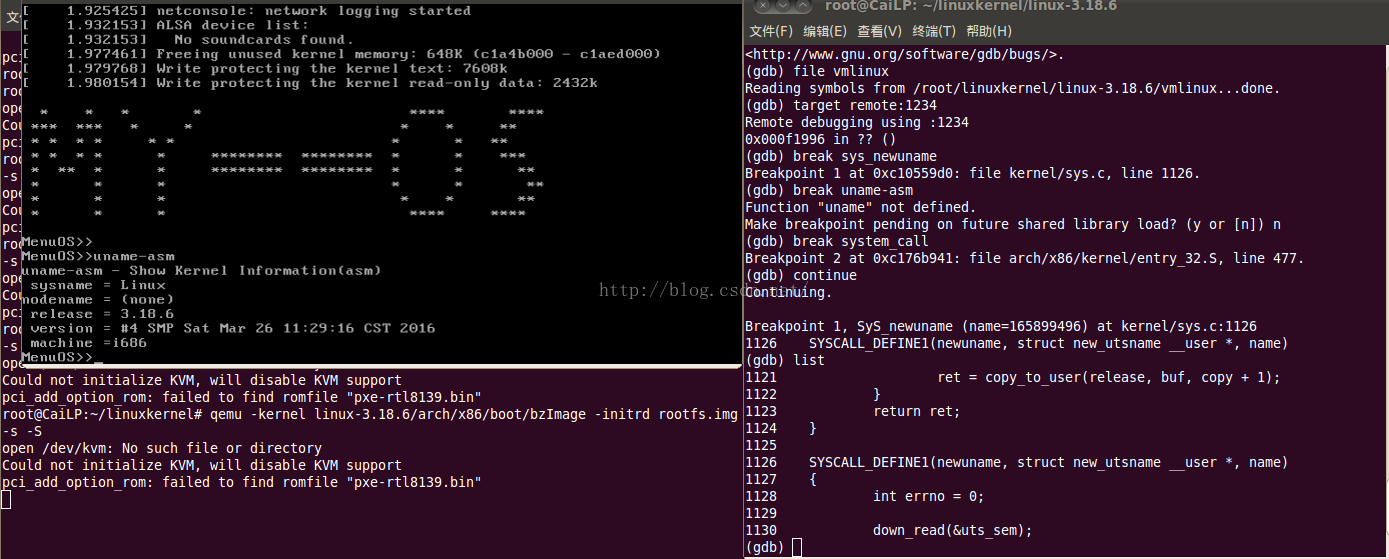
如果继续单步运行,接下来的代码无法调试
关于System_call的调试
Linux的内核和System Call不好调试。简单来说,如果想在本机调试system call,那么当你进入system call时,系统已经在挂起状态了。如下所说:
Debugging on Linux is implemented via the ptrace(2) system call; ptrace can only inspect and stop processes running in userspace. I would expect that FreeBSD's process debugging mechanism is similar, and only designed to work on userspace processes: because the OS kernel will acquire and release locks as well as respond to interrupts quickly, designing the kernel to allow full-featured debugging from userspace seems very unlikely.
如果想要跟踪调试system_call(kgdb),可以使用:

- UML方式
- 使用串口/别的机器
PS:具体参考:http://stackoverflow.com/questions/5999205/cannot-step-into-system-call-source-code,这里不再赘述。
二、system_call 汇编代码分析
system_call 是由汇编语言编写,放在linux-source-2.6.32/arch/x86/kernel/entry_32.S ,linux-source-2.6.32是linux源码解压后的文件夹。
ENTRY(system_call)
RING0_INT_FRAME
ASM_CLAC
pushl_cfi %eax
SAVE_ALL
GET_THREAD_INFO(%ebp)
testl $_TIF_WORK_SYSCALL_ENTRY,TI_flags(%ebp)
jnz syscall_trace_entry
cmpl $(NR_syscalls), %eax
jae syscall_badsys
syscall_call:
call *sys_call_table(,%eax,4)
syscall_after_call:
movl %eax,PT_EAX(%esp)
syscall_exit:
LOCKDEP_SYS_EXIT
DISABLE_INTERRUPTS(CLBR_ANY)
TRACE_IRQS_OFF
movl TI_flags(%ebp), %ecx
testl $_TIF_ALLWORK_MASK, %ecx
jne syscall_exit_work
restore_all:
TRACE_IRQS_IRET
restore_all_notrace:
#ifdef CONFIG_X86_ESPFIX32
movl PT_EFLAGS(%esp), %eax
movb PT_OLDSS(%esp), %ah
movb PT_CS(%esp), %al
andl $(X86_EFLAGS_VM | (SEGMENT_TI_MASK << 8) | SEGMENT_RPL_MASK), %eax
cmpl $((SEGMENT_LDT << 8) | USER_RPL), %eax
CFI_REMEMBER_STATE
je ldt_ss
#endif
restore_nocheck:
RESTORE_REGS 4
irq_return:
INTERRUPT_RETURN
.section .fixup,"ax"
ENTRY(iret_exc)
pushl $0 # no error code
pushl $do_iret_error
jmp error_code
.previous
_ASM_EXTABLE(irq_return,iret_exc)
#ifdef CONFIG_X86_ESPFIX32
CFI_RESTORE_STATE
ldt_ss:
#ifdef CONFIG_PARAVIRT
cmpl $0, pv_info+PARAVIRT_enabled
jne restore_nocheck
#endif
#define GDT_ESPFIX_SS PER_CPU_VAR(gdt_page) + (GDT_ENTRY_ESPFIX_SS * 8)
mov %esp, %edx
mov PT_OLDESP(%esp), %eax
mov %dx, %ax
sub %eax, %edx
shr $16, %edx
mov %dl, GDT_ESPFIX_SS + 4
mov %dh, GDT_ESPFIX_SS + 7
pushl_cfi $__ESPFIX_SS
pushl_cfi %eax
DISABLE_INTERRUPTS(CLBR_EAX)
lss (%esp), %esp
CFI_ADJUST_CFA_OFFSET -8
jmp restore_no-check
#endif
CFI_ENDPROC
ENDPROC(system_call)
这汇编代码很复杂,很多宏定义交错在一起,逐条的分析难度很大,但是有一些重点的模块还是可以猜出大概的意思(有不正确的地方请指正!)
1、在进入system_call 后,正式切换到系统调用例程之前,是一大堆的入栈操作如:pushl: %eax 。SAVE_ALL //SAVE_ALL 是一个处理过程,也定以在entry.S中,进行的也是一堆的入栈操作,将各种寄存器的值保存到堆栈中,以备返回用户程序时恢复现场。压入堆栈的顺序对应着结构体struct pt_regs ,当出栈的时候,就将这些值传递到结构体struct pt_regs里面的成员,从而实现从汇编代码向C程序传递参数。struct pt_regs 位于:linux/arch/x86/include/asm/ptrace.h。
2、GET_THREAD_INFO 宏获得当前进程的thread_info结构的地址,获取当前进程的信息。
3、CFI_ADJUST_CFA_OFFSET X 是存储单元对其指令,CFI是Canonical Format Indicator 标准格式指示位的缩写。所以后面遇到CFI开头的指令,我们都把它当成是“修饰性”的指令,对整体的功能框架不影响。(不确定,理解错了请指正)
push_cfi 的定义在:linux-3.18.6/arch/x86/include/asm/dwarf2.h
.macro pushl_cfi reg pushl \reg CFI_ADJUST_CFA_OFFSET 4 .endm
4、testl $_TIF_WORK_SYSCALL_ENTRY,TI_flags(%ebp)
jnz syscall_trace_entry #比较结果不为零的时候跳转。
# system call tracing in operation / emulation
#thread_inof结构中flag字段的_TIF_SYSCALL_TRACE或_TIF_SYSCALL_AUDIT
#被置1。如果发生被跟踪的情况则转向相应的处理命令处。
_TIF_WORK_SYSCALL_ENTRY是定义的一个宏,在文件 arch/x86/include/asm/thread_info.h 中定义如下:
/* work to do in syscall_trace_enter() */
#define _TIF_WORK_SYSCALL_ENTRY \
(_TIF_SYSCALL_TRACE | _TIF_SYSCALL_EMU | _TIF_SYSCALL_AUDIT | _TIF_SECCOMP | _TIF_SINGLESTEP | _TIF_SYSCALL_TRACEPOINT)
TIF 是Thread Information Flags 的缩写。
5、cmpl $(nr_syscalls), %eax
jae syscall_badsys
test逻辑与运算结果为零,就把ZF(零标志)置1;
cmp 算术减法运算结果为零,就把ZF(零标志)置1.
//NR_syscalls是一个宏定义,在文件 kernel/asm-offsets.s中: NR_syscalls $358 sizeof(syscalls),保存的是当前内核支持的系统调用的总数,这里与%eax的值进行比较是为了判断进程提供的调用号是否超出范围。
对用户态进程传递过来的系统调用号的合法性进行检查。如果不合法则跳转到syscall_badsys标记的命令处。
6、比较结果大于或者等于最大的系统调用号的时候跳转,合法则跳转到相应系统调用号所对应的服务例程当中,也就是在sys_call_table表中找到了相应的函数入口点。由于sys_call_table表的表项占4字节,因此获得服务例程指针的具体方法是将由eax保存的系统调用号乘以4再与sys_call_table表的基址相加。
call *sys_call_table(,%eax,4)
movl %eax,PT_EAX(%esp) # store the return value 返回值默认都是保存在%eax中带出来。
sys_call_table位于:linux/arch/x86/kernel/syscall_table_32.S
7、执行完处理程序后:
syscall_exit:
LOCKDEP_SYS_EXIT
DISABLE_INTERRUPTS(CLBR_ANY) # make sure we don't miss an interrupt setting need_resched or sigpending between sampling and the iret
TRACE_IRQS_OFF
movl TI_flags(%ebp), %ecx // 检查任务标记,退出系统调用之前,检查是否需要处理信号
testl $_TIF_ALLWORK_MASK, %ecx # current->work
jne syscall_exit_work //如果需要就转去执行退出相关的操作,否则继续执行 restore all准备退出。
CLBR_ANY在文件:/arch/x86/include/asm/paravirt_types.h中定义如下:#define CLBR_ANY ((1 << 4) - 1)
8、 从标号restaore_all 往后就都是执行退出调用相关的操作,只不过,在这个过程中做了很多的检查性工作。
关于任务的堆栈的详细解释,可以查看下一篇:任务的堆栈,里面介绍了堆栈的基础相关知识,以及用户态堆栈与内核态堆栈的区别与联系。
三、总结:执行系统调用的流程:
先给出一个很不错的图:
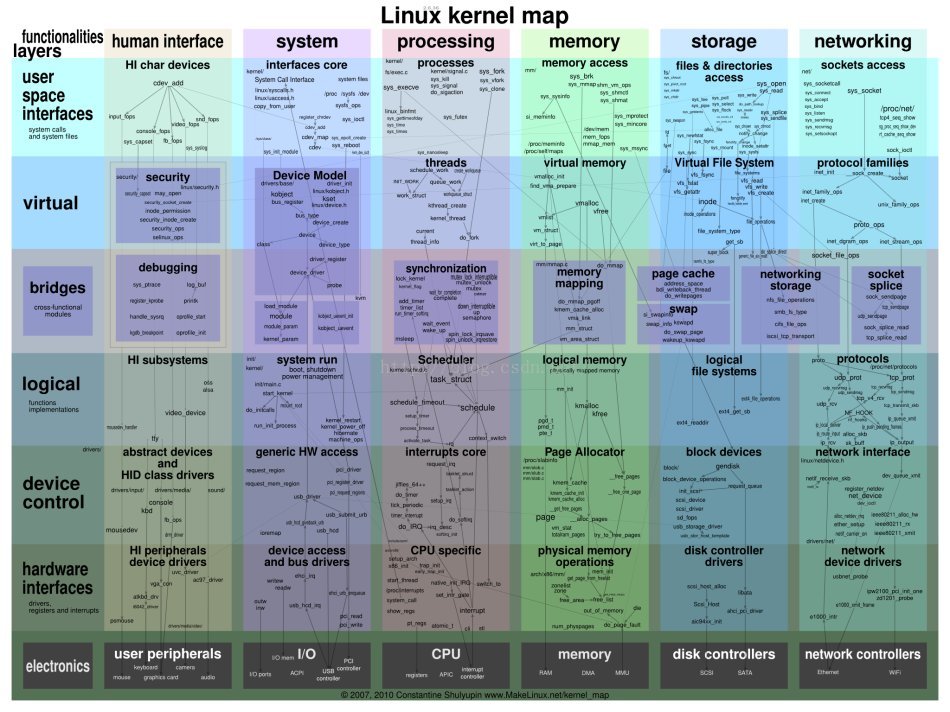
高清版本的可以访问http://www.makelinux.net/kernel_map/
下面是应用程序与内核之间的一个大的关系:
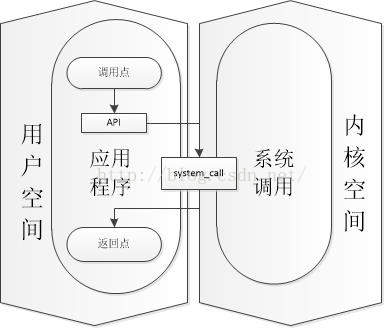
下面看一下进入system_call后,内核的工作过程:
1、系统调用的整个过程从轮廓上来看,跟之前的任务调度基本一致:
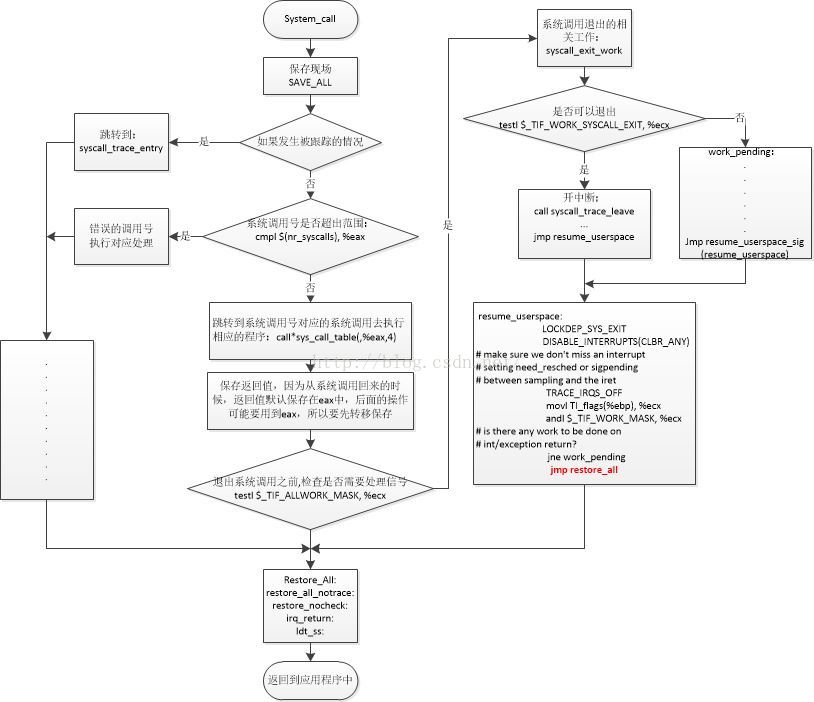
- SAVE ALL保存现场进入内核空间
- ............
- 执行处理程序
- ............
- RESTORE_ALL恢复现场,返回用户空间
不同的是,由于要进入到内核空间操作,除了上下文的切换以外,还要做很多安全性的检查;而且内核是所有任务共有的,这个任务可以调用内核,那个任务也可以调用内核,在优先级不同时,就可能会嵌套发生;因此系统调用要复杂得多。
2、与用户态的函数库调用执行过程相比,系统调用执行过程的有四点主要的不同:
- 不是通过“CALL”指令而是通过“INT”指令发起调用;
- 不是通过“RET”指令,而是通过“IRET”指令完成调用返回;
- 当到达内核态后,操作系统需要严格检查系统调用传递的参数,确保不破坏整个系统的安全性;
- 执行系统调用可导致进程等待某事件发生,从而可引起进程切换;
linux内核水太深,还需继续探讨!有理解不对的地方希望大家指正!
参考:
http://www.makelinux.net/
http://www.makelinux.net/kernel_map/
http://www.jianshu.com/p/765fc517612f
http://www.cnblogs.com/zhuyp1015/archive/2012/05/29/2524936.html (牛)
http://blog.csdn.net/adc0809608/article/details/7417180
https://en.wikipedia.org/wiki/System_call
更多推荐
 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)