
Reflinks vs symlinks vs hard links,以及它们如何帮助机器学习项目
自古以来就有硬链接和符号链接,我们一直在使用它们,甚至没有考虑它。在机器学习项目中,它们可以帮助我们在设置新实验时快速有效地重新排列机器学习项目中的数据文件。然而,使用传统链接,我们冒着错误编辑污染数据文件的风险。在这篇博文中,我们将详细介绍使用链接的细节、现代文件系统中的一些很酷的新东西(引用链接),以及如何使用 DVC 的示例(数据版本控制,https://dvc.org/)利用这一点。
当我在学习机器学习时,我希望有一个工具可以让我们像进行常规软件工程项目一样检查 ML 项目。也就是说,要在任何给定时间检索项目的状态,根据项目的早期状态创建分支或标签(使用 Git),处理与同事的协作等等。让 ML 项目与众不同的是海量数据、数千张图像、音频或视频文件、经过训练的模型,以及使用 Git 等常规工具管理这些文件的难度。在我之前的文章中,我讨论了为什么Git 本身是不够的,为什么 Git-LFS 不是机器学习项目的解决方案,以及一些似乎对管理 ML 项目的工具有用的原则.
事实证明,DVC 非常擅长管理 ML 项目数据集和工作流程。它与 Git 协同工作,可以向您显示与任何 Git 提交对应的数据集的状态。只需检查一个提交,DVC 就可以重新排列数据文件以完全匹配提交时存在的内容。
速度相当神奇,考虑到可能几乎瞬间重新排列数千兆字节的数据。所以我想知道:DVC 是如何做到这一点的?
重新排列千兆字节训练数据的技巧
事实证明,DVC 重新排列数据和模型文件的速度与 Git 链接文件而不是复制文件一样快。当然,Git 在签出提交时会将文件复制到位,但 Git 通常处理相对较小的文本文件,而不是 ML 项目中使用的大型二进制 blob。像 DVC 那样链接文件非常快,可以在眨眼之间重新排列任意数量的文件,同时避免复制,从而节省磁盘空间。
实际上,使用文件链接技术对该领域来说并不是什么新鲜事。一些数据科学团队使用符号链接来节省空间并避免复制大型数据集。但是符号链接并不是唯一可以使用的链接。我们将从将文件复制到位的策略开始,然后使用硬链接和符号链接,最后使用一种新型链接 reflinks,它在文件系统中实现了Copy On Write 功能。我们将使用 DVC 作为工具如何使用不同链接策略的示例。
测试设置
由于我们将测试不同的链接策略,因此我们需要一个示例工作区。工作区是在我的笔记本电脑上设置的,这是一台 MacBook Pro,其中主驱动器使用APFS文件系统格式化。在 Linux 上使用XFS格式化的驱动器上进行了进一步的测试。
使用的数据是从两个不同的日子检索到的维基百科网站的两个“存根文章”转储。每个都是大约 38 GB 的 XML,为我们提供了足够类似于 ML 项目的数据。然后,我们设置了一个 Git/DVC 工作区,可以通过检查不同的 Git 提交在这两个文件之间切换。
$ ls -hl wikidatawiki-20190401-stub-articles.xml
-rw-r--r-- 1 david staff 35G Jul 20 21:35 wikidatawiki-20190401-stub-articles.xml
$ time cp wikidatawiki-20190401-stub-articles.xml wikidatawiki-stub-articles.xml
real 14m16.918s
...
作为基线测量,我们会注意到将这些文件复制到工作区大约需要 15 分钟。显然,如果在存储库中的提交之间切换需要 15 分钟,ML 研究人员的生活将不会很愉快。
相反,我们将探索 DVC 和其他一些工具使用的另一种技术 - 链接。所有现代操作系统都支持两种类型的链接:硬链接、符号链接。一种新型链接,Reflink(写时复制),开始在较新版本的 Mac OS X 和 Linux 中可用(为此需要所需的文件系统驱动程序)。我们将依次使用它们中的每一个,看看它们的工作情况如何。
DVC 在其文档中讨论了对应于三种链接类型的四种策略(第 4 种策略是仅复制文件)。使用的策略取决于文件系统的能力,以及“dvc config cache.type”命令是否改变了配置。
DVC 默认使用 reflinks,如果不可用,则回退到文件复制。它避免使用符号链接和硬链接,因为存在意外缓存或存储库损坏的风险。我们将在接下来的部分中看到所有这些。
使用文件复制的版本化数据集
签出 Git 标记时将文件复制到位的基本(或幼稚)策略等同于以下命令:
$ rm data/wikidatawiki-stub-articles.xml
$ cp .dvc/cache/40/58c95964df74395df6e9e8e1aa6056 data/wikidatawiki-stub-articles.xml
这将在任何文件系统上运行,但是复制文件需要很长时间,并且会消耗两倍的磁盘空间。
奇怪的文件名是怎么回事?它是 DVC 缓存中的文件名,十六进制数字是 MD5 校验和。 DVC 缓存中的文件由该校验和索引,允许同一文件有多个版本。DVC 文档包含有关 DVC 缓存实现的更多详细信息。
实际上,这就是它在 DVC 中的工作方式:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--OmQyDJyP--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_66%2Cw_880/https://thepracticaldev.s3 .amazonaws.com/i/1hox1cyly1dsnqxfp2tv.gif)
](https://res.cloudinary.com/practicaldev/image/fetch/s--OmQyDJyP--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_66%2Cw_880/https://thepracticaldev.s3 .amazonaws.com/i/1hox1cyly1dsnqxfp2tv.gif)
为了设置工作区,我们创建了两个 Git 标记,一个用于我们下载的每个文件。版本化数据集](https://dvc.org/doc/get-started/example-versioning)(或此替代教程)上的[DVC 示例应该让您了解设置工作区所涉及的内容。为了测试不同的文件复制/链接模式,我们首先更改 DVC 配置,然后检查给定的 Git 提交。运行“dvc checkout”会导致相应的数据文件插入到目录中。
哦,男孩,那肯定花了很长时间。这其中的 Git 部分非常快,但 DVC 花了很长时间。这符合预期,因为我们告诉 DVC 执行文件复制,并且我们已经知道使用 cp 命令复制文件大约需要 16 分钟左右。
至于磁盘空间,显然现在有两个数据文件副本。 DVC 缓存目录中有一个副本,另一个被复制到工作区中。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--yNsBtwem--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://imgs.xkcd.com /comics/porn_folder.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--yNsBtwem--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://imgs.xkcd.com /comics/porn_folder.png)
来源:https://www.xkcd.com/981/
使用硬链接和符号链接的版本化数据集
清楚地复制文件以处理数据集版本控制很慢,并且对磁盘空间的使用效率低下。自古以来就存在于类 Unix 环境中的一个选项是硬链接和符号链接。虽然 Windows 历史上不支持文件链接,但“mklink”也可以同时支持两种样式的链接。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--GjgWiJ2H--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev .s3.amazonaws.com/i/nt9y47pghodhzyixcgb4.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--GjgWiJ2H--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev .s3.amazonaws.com/i/nt9y47pghodhzyixcgb4.png)
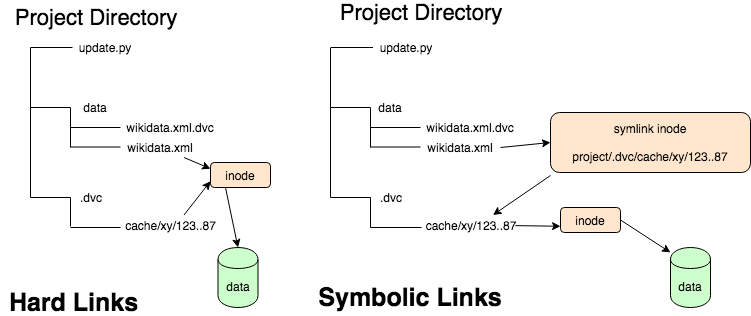
硬链接是文件系统 Unix 模型的副产品。我们认为的文件名实际上只是目录文件中的一个条目。目录文件条目包含文件名和“inode 编号”,它只是对 inode 表的索引。 Inode 表条目是包含文件属性和指向实际数据的指针的数据结构。硬链接只是两个具有相同 inode 编号的目录条目。实际上,它是出现在文件系统中两个位置的完全相同的文件。硬链接只能在给定的已安装卷内进行。
符号链接是一个特殊文件,其中属性包含指定链接目标的路径名。因为它包含路径名,所以符号链接可以指向文件系统中的任何文件,甚至可以跨挂载的卷或跨网络文件系统。
这种情况下的等效命令是:
$ rm data/wikidatawiki-stub-articles.xml
$ ln .dvc/cache/40/58c95964df74395df6e9e8e1aa6056 data/wikidatawiki-stub-articles.xml
这是一个硬链接。对于符号链接,请使用“ln -s”。
然后执行硬链接场景:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--S0-edCTG--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_66%2Cw_880/https:// thepracticaldev.s3.amazonaws.com/i/2fyvuusadfhhzjiqgwy6.gif)
](https://res.cloudinary.com/practicaldev/image/fetch/s--S0-edCTG--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_66%2Cw_880/https:// thepracticaldev.s3.amazonaws.com/i/2fyvuusadfhhzjiqgwy6.gif)
符号链接场景相同,但将cache.type设置为symlink。两种情况的时间相似。
两秒(或更少)肯定比复制文件所需的 16 分钟快得多。它发生得如此之快,我们使用“瞬时”这个词。文件链接比复制文件快得多。这是一个很大的胜利。
至于磁盘空间消耗,请考虑:
$ ls -l data/
total 8
lrwxr-xr-x 1 david staff 70 Jul 21 18:43 wikidatawiki-stub-articles.xml -> /Users/david/dvc/linktest/.dvc/cache/2c/82d0130fb32a17d58e2b5a884cd3ce
该链接占用的磁盘空间可以忽略不计。但是有一个皱纹需要考虑。
好的,看起来很棒,对吧?速度快,不占用额外空间......但是,让我们想想如果您在工作区中编辑data/wikidatawiki-stub-articles.xml会发生什么。因为该文件是 DVC 缓存中文件的链接,所以缓存中的文件会被更改,从而污染缓存。您需要采取额外措施,并学习如何避免该问题。DVC 文档提供了有关在使用 DVC 时避免该问题的说明。这意味着始终记住使用特定过程来编辑数据文件,虽然这不是破坏交易,但不太方便。更好的选择是使用 reflinks。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--afwSrBzL--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3 .amazonaws.com/i/x94lpqmuswdaizdq05vn.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--afwSrBzL--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3 .amazonaws.com/i/x94lpqmuswdaizdq05vn.png)
使用 Reflinks 的版本化数据集
硬链接和符号链接在 Unix/Linux 生态系统中已经存在很长时间了。我在 1984 年首次在 4.2BSD 上使用符号链接,而硬链接可以追溯到更早的时候。硬链接和符号链接都可以用来做 DVC 所做的事情,即在工作目录中快速重新排列数据文件。但是在过去的 35 多年里,文件系统肯定有过一两次的进步吗?
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--kFEZNFcM--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3.amazonaws .com/i/hda2xvpq1068vyjwfx4c.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--kFEZNFcM--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3.amazonaws .com/i/hda2xvpq1068vyjwfx4c.png)
确实有,Mac OS X “clonefile” 和 Linux “reflink” 功能就是例子。
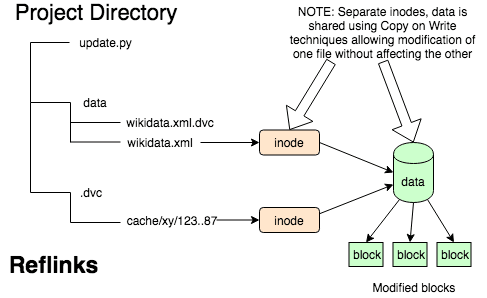
Copy On Write 链接(又名 reflinks)提供了一种解决方案,可以将文件快速链接到工作区,同时避免任何污染缓存的风险。硬链接和符号链接方法因其速度而大获成功,但这样做会冒着污染缓存的风险。使用 reflink,写时复制行为意味着如果有人要修改数据文件,缓存中的副本不会被污染。这意味着我们将拥有与传统链接相同的性能优势,以及数据安全性的额外优势。
也许,像我一样,你不知道什么是反射链接。这种技术意味着复制磁盘上的文件,使得“副本”是类似于硬链接的“克隆”。与两个目录条目引用同一个 inode 条目的硬链接不同,reflink 有两个 inode 条目,并且共享的是数据块。它的发生速度与硬链接一样快,但有一个重要的区别。对克隆文件的任何写入都会导致分配新的数据块来保存该数据。克隆的文件似乎已更改,而原始文件未修改。克隆非常适合复制数据集的情况,允许在不污染原始数据集的情况下修改数据集。
与硬链接一样,重新链接仅适用于给定的已安装卷。
Reflinks 在 Mac OS X 上很容易获得,在 Linux 上只需做一点工作。此功能仅在某些文件系统上受支持:
-
Linux
-
BTRFS
-
XFS
-
对不起
-
Mac OS X
-
APFS
macOS 上开箱即用地支持 APFS,Apple 强烈建议我们使用它。对于 Linux,XFS 是最容易设置的,如本教程所示。
对于 APFS,等效命令是:
$ rm data/wikidatawiki-stub-articles.xml
$ cp -c .dvc/cache/40/58c95964df74395df6e9e8e1aa6056 data/wikidatawiki-stub-articles.xml
使用-c选项,macOScp命令使用clonefile(2)系统调用。clonefile函数设置命名文件的 reflink 克隆。在 Linux 上,cp命令使用--reflink选项。
然后运行测试:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--iFWF0qPQ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_66%2Cw_880/https://thepracticaldev.s3 .amazonaws.com/i/l3hwn2uer6cubc1rlbra.gif)
](https://res.cloudinary.com/practicaldev/image/fetch/s--iFWF0qPQ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_66%2Cw_880/https://thepracticaldev.s3 .amazonaws.com/i/l3hwn2uer6cubc1rlbra.gif)
正如预期的那样,性能类似于硬链接和符号链接策略。我们了解到,反射链接与硬链接和符号链接一样快,并且磁盘空间消耗再次可以忽略不计。
关于此链接的酷炫之处在于,即使文件已连接,您也可以在不修改缓存中的文件的情况下编辑文件。更改的数据在后台被复制。
在 Linux 上,相同的场景以相似的性能运行。
结论
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--2dE_Mly6--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3.amazonaws .com/i/9duojm0vyjqm5vqnasm3.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--2dE_Mly6--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3.amazonaws .com/i/9duojm0vyjqm5vqnasm3.png)
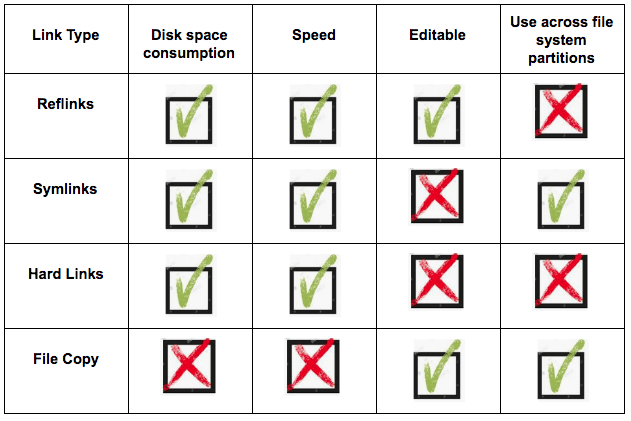
我们已经了解了如何有效管理大型数据集,这在机器学习项目中很常见。如果我们需要重新审视此类项目中的任何开发阶段,我们将需要一个系统来有效地重新排列大型数据集以匹配每个阶段。
我们已经看到可以保留在任何 Git 提交中存在的文件列表。使用该列表,我们可以将这些文件链接或复制到工作目录中。这正是 DVC 在项目中管理数据文件的方式。使用链接而不是文件复制,可以让我们在项目的修订版之间快速有效地切换。
Reflinks 是文件系统的一个有趣的新功能,它们非常适合这种情况。 Reflink 的创建速度与传统的硬链接和符号链接一样快,让我们可以快速复制文件或整个目录结构,同时消耗的额外空间可以忽略不计。而且,由于 reflink 会在链接文件中保留修改,因此它们为我们提供了比传统链接更多的可能性。在本文中,我们研究了在机器学习项目中使用 reflink,但它们也用于其他类型的应用程序。例如,一些数据库系统利用它们来更有效地管理磁盘上的数据。既然您已经了解了反射链接,那么您将如何使用它们呢?
更多推荐



 0
0 0
0- 0



 已为社区贡献12493条内容
已为社区贡献12493条内容

所有评论(0)