K8S基础
k8s 大全
dashboard登录秘钥查看
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep kubernetes-dashboard-admin-token | awk '{print $1}')
eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZC1hZG1pbi10b2tlbi1ncmc2NiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZC1hZG1pbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjJkMDE0ZTVmLThjY2EtMTFlYS04MmExLTAwNTA1NjI0YjJhZCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlLXN5c3RlbTprdWJlcm5ldGVzLWRhc2hib2FyZC1hZG1pbiJ9.lj8wYI4iN7TKKQoXzWus4nSE52RUSsfs1GUIwIoWXdkEmOhxjq4Y0mGlZi7Ktem8TGhzwsGpxhdgNtCBkSbo8DzwJxNZJNVZtbm4tjRj1e2QIQ1ZvdJjbIrC1PsX_4FXzsCj7BpTvujRHiQm_65EXt-gLDLHV5d5ohQ1QS-4a79RkEG4gXkvRfir3hkHCZar3JEG0QiXmwLlyi_VXVLl2Gqs2WSQVF0-PKjFdDDrczvb-C2iXZGSSfHwBdbmSg1u80Gf8kbIo3pTqEmy9z3j1ICVz0RIxuEQVgRP0AL092oziWPPGdlnbPK3hl_Wg67Q1hHe-EaTdtgVfgGGEqfzGQ
k8s与docker区别
docker部署mysql挂载本地就可以
k8S部署mysql需要有持久卷pv,需要把mysql文件挂载到持久卷上,因为pod可能会在任意一个节点
configmap pod的应用程序配置文件
容器->pod->rs->deploy->services
rc保证了pod运行的副本数
deploy保证了软件的升级与更新,回滚,参考 https://www.jianshu.com/p/6fd42abd9baa
K8S 端口
| 组件 | 端口 | 参数 | 默认值 | 协议 | 必须开启 | 说明 |
|---|---|---|---|---|---|---|
| kube-apiserver | 安全端口 | –secure-port | 6443 | HTTPS | 是 | - |
| kube-apiserver | 非安全端口 | –insecure-port | 8080 | HTTP | 否,0表示关闭 | deprecated |
| kubelet | 健康检测端口 | –healthz-port | 10248 | HTTP | 否,0表示关闭 | - |
| kube-proxy | 指标端口 | –metrics-port | 10249 | HTTP | 否,0表示关闭 | - |
| kubelet | 安全端口 | –port | 10250 | HTTPS | 是 | 认证与授权 |
| kube-scheduler | 非安全端口 | –insecure-port | 10251 | HTTP | 否,0表示关闭 | deprecated |
| kube-controller-manager | 非安全端口 | –insecure-port | 10252 | HTTP | 否,0表示关闭 | deprecated |
| kubelet | 非安全端口 | –read-only-port | 10255 | HTTP | 否,0表示关闭 | - |
| kube-proxy | 健康检测端口 | –healthz-port | 10256 | HTTP | 否,0表示关闭 | - |
| kube-controller-manager | 安全端口 | –secure-port | 10257 | HTTPS | 否,0表示关闭 | 认证与授权 |
| kube-scheduler | 安全端口 | –secure-port | 10259 | HTTPS | 否,0表示关闭 | 认证与授权 |
参考官网
https://kubernetes.feisky.xyz/concepts/components
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PQOU7ov0-1680158062096)(pic/K8S基础/image-20210222165810020.png)]
K8S常用命令
kubectl 命令行的语法
kubectl [command][TYPE] [NAME]
command: 例如create,delete,describe ,get ,apply ,label 等
常用操作
查看pod
kubectl get pod podname -n <namespaces>
进入pod容器中
kubectl exec -it podname /bin/bash
查看pod描述
kubectl describe po podname
kubectl delete pod PODNAME --force --grace-period=0
查看日志
1、查看指定pod的日志
kubectl logs -f <pod_name>
2、查看指定多个容器的pod中指定容器的日志
kubectl logs <pod_name> -c <container_name>
创建应用
kubectl create -f deployment.yaml
删除应用
kubectl delete -f deployment.yaml
查看节点 标签
kubectl get node/po/svc --show-labels
文件拷贝 注意 拷贝出来要指定文件吗
kubectl cp ${podname}:/opt/test.tar -c ${container} /bml_data/wjl/test.tar
kubectl输出格式
kubectl 命令可以用多种格式对结果进行显示,输出的格式通过-o参数指定:
$ kubectl [command][TYPE] [NAME] -o=<output_format>
根据不同子命令的输出结果,可选的输出格式如表2.12所示。
输出格式 说明
-o=custom-columns= 根据自定义列名进行输出,以逗号分隔
-o=custom-colimns-file= 从文件中获取自定义列名进行输出
-o=json 以JSON格式显示结果
-o=jsonpath= 输出jsonpath表达式定义的字段信息
-o=jsonpath-file= 输出jsonpath表达式定义的字段信息,来源于文件
-o=name 仅输出资源对象的名称
-o=wide 输出额外信息。对于Pod,将输出Pod所在的Node名
-o=yaml 以yaml格式显示结果
K8S高可用俩种方式
keepallived
对外暴露一个keepalived的虚拟ip(vip),这样数据会按照权重走到master,
master本地进行haproxy代理,负载均衡转发到三个master节点,这样就是实现了k8s高可用。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XlI0IhVZ-1680158062096)(./pic/K8S技术总结.assets/k8s高可用架构.png)]
利用k8s自身
kubectl label nodes node-1 node-role.kubernetes.io/master=
kubectl label nodes node-2 node-role.kubernetes.io/node=
kubectl label nodes node-3 node-role.kubernetes.io/node=
K8S 架构 与组件
架构图
架构一
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GOLJnfQE-1680158062097)(pic/K8S技术总结.assets/1349539-20190119143437957-1879674594.png)]
架构二
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hr15l0rM-1680158062097)(pic/K8S技术总结.assets/k8s.jpg)]
架构三
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jwl170rX-1680158062097)(pic/K8S技术总结.assets/architecture.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-axOnuX1j-1680158062098)(pic/K8S技术总结.assets/o7leok.png)]
K8S基本组件
以下是k8s全部组件
default myapp-deploy-5df64577c-4t8jf 1/1 Running 1 79d
default myapp-deploy-5df64577c-rcsd7 1/1 Running 1 78d
default nginx-56f766d96f-6vrxc 1/1 Running 1 79d
kube-system etcd-node-1 1/1 Running 16 92d
kube-system kube-apiserver-node-1 1/1 Running 17 92d
kube-system kube-controller-manager-node-1 1/1 Running 18 92d
kube-system kube-dns-86f4d74b45-7qwtj 3/3 Running 3 79d
kube-system kube-flannel-ds-amd64-k584w 1/1 Running 21 92d
kube-system kube-flannel-ds-amd64-mwh6l 1/1 Running 19 92d
kube-system kube-flannel-ds-amd64-wkmrd 1/1 Running 15 92d
kube-system kube-proxy-qfgwg 1/1 Running 17 92d
kube-system kube-proxy-sd4pv 1/1 Running 15 92d
kube-system kube-proxy-vxhv9 1/1 Running 19 92d
kube-system kube-scheduler-node-1 1/1 Running 16 92d
Master 组件:
kube-apiserver
如下可以看出只有一个容器
kube-system kube-apiserver-node-1 1/1 Running 17 92d
如果有三个 主节点
kube-system kube-apiserver-node-1 1/1 Running 17 92d
kube-system kube-apiserver-node-2 1/1 Running 17 92d
kube-system kube-apiserver-node-3 1/1 Running 17 92d
Kubernetes API 集群的统一入口,各组件的协调者,以RESTful API提供接口方式,所有的对象资源(比如pod,svc,pv等等)的增删改查和监听操作都交给APIServer处理后再提交给etcd数据库做持久化存储。
APIServer负责对外提供RESTful的Kubernetes API服务,它是系统管理指令的统一入口,任何对资源进行增删改查的操作都要交给APIServer处理后再提交给etcd。
kubectl是直接和APIServer交互的(Kubernetes提供的客户端工具,该工具内部就是对Kubernetes API的调用)。
只有API Server与存储通信,其他模块通过API Server访问集群状态。这样第一,是为了保证集群状态访问的安全。第二,是为了隔离集群状态访问的方式和后端存储实现的方式:API Server是状态访问的方式,不会因为后端存储技术etcd的改变而改变。加入以后将etcd更换成其他的存储方式,并不会影响依赖依赖API Server的其他K8s系统模块。
Kube-controller-manager
每一个主节点都有一个
kube-system kube-controller-manager-node-1 1/1 Running 18 92d
处理集群中常规后台任务,一个资源对应一个控制器,而controllerManager就是负责处理这些控制器的
kube-scheduler
每一个主节点都有一个
kube-system kube-scheduler-node-1 1/1 Running 16 92d
根据调度算法为新创建的pod选择一个Node节点,可以任意部署,可以部署在同一个节点上,也可以部署在不同的节点上
etcd
分布式键值存储系统,用于保存集群状态数据,比如Pod,Service等对象信息
kube-system etcd-node-1 1/1 Running 16 92d
Node组件:
kubelet
查看日志
journalctl -xefu kubelet
systemctl start kubelet;
kubelet 是Master在Node节点上的Agent,管理本机运行容器的生命周期,比如创建容器,Pod挂载数据卷,下载secret,获取容器和节点状态等工作,kubelet 将每个Pod转换成一组容器
kubelet是node的agent,当Scheduler确定在某个Node上运行Pod后,会将Pod的具体配置信息(image、volume等)发送给该节点的kubelet,kubelet会根据这些信息创建和运行容器,并向master报告运行状态。
在每个节点(node)上都要运行一个 worker 对容器进行生命周期的管理,这个 worker 程序就是kubelet。kubelet的主要功能就是定时从某个地方获取节点上 pod/container 的期望状态(运行什么容器、运行的副本数量、网络或者存储如何配置等等),并调用对应的容器平台接口达到这个状态。kubelet 还要查看容器是否正常运行,如果容器运行出错,就要根据设置的重启策略进行处理。kubelet 还有一个重要的责任,就是监控所在节点的资源使用情况,并定时向 master 报告。知道整个集群所有节点的资源情况,对于 pod 的调度和正常运行至关重要。
kube-proxy:
在Node节点上实现Pod网络代理,维护网络规则和四层负载均衡工作。实现让Pod节点(一个或者多个容器)对外提供服务
service在逻辑上代表了后端的多个Pod,外借通过service访问Pod。service接收到请求就需要kube-proxy完成转发到Pod的。每个Node都会运行kube-proxy服务,负责将访问的service的TCP/UDP数据流转发到后端的容器,如果有多个副本,
kube-proxy会实现负载均衡,有2种方式:LVS或者Iptables
Cluster IP是怎么被kube-proxy管理的
每个节点(node)都有一个组件kube-proxy,实际上是为service服务的,通过kube-proxy,实现流量从service到pod的转发,
它负责TCP和UDP数据包的网络路由,kube-proxy也可以实现简单的负载均衡功能。其实就是管理service的访问入口,包括集群内Pod到Service的访问和集群外访问service。 kube-proxy管理sevice的Endpoints,该service对外暴露一个Virtual IP,也成为Cluster IP, 集群内通过访问这个Cluster IP:Port就能访问到集群内对应的serivce下的Pod。
kube-proxy通过查询和监听API server中service和endpoint的变化。为每个service都建立了一个服务代理对象。并自动同步。服务代理对象是proxy程序内部的一种数据结构,它包括一个用于监听此服务请求的socketserver,socketserver的端口是随机选择的一个本地空闲端口。此外,kube-proxy内部也创建了一个负载均衡器-LoadBalancer,LoadBalancer上保存了service到对应的后端endpoint列表的动态转发路由表。而具体的路由选择则取决于Round Robin负载均衡算法及service的session会话保持这两个特性。
docker或rocket
容器引擎,运行容器
kube-dns
每个node节点都有一个
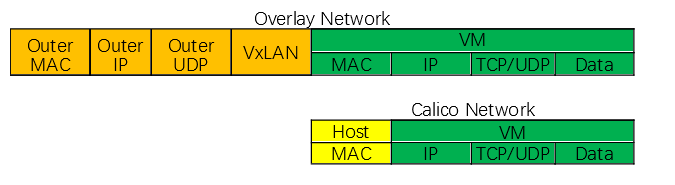
在k8s中使用Calico或者Flannel这种网络通信方案,这个方案提供了k8s集群中所有pod的ip互相通信的解决方案。
优点:简单
缺点:pod重启之后,ip是重新自动获取,不是pod的唯一标识
k8s提供的DNS名称和k8s集群默认的集群名字有关系,默认k8s集群的域名为cluster.local,则所有DNS的全名称都会以cluster.local为后缀。
服务注册过程指的是在服务注册表中登记一个服务,以便让其它服务发现。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HFDUAKTz-1680158068161)(null)]
Kubernetes 使用 DNS 作为服务注册表。
为了满足这一需要,每个 Kubernetes 集群都会在 kube-system 命名空间中用 Pod 的形式运行一个 DNS 服务,通常称之为集群 DNS。
kube-flannel
每个node节点都有一个
K8S原理
服务自动发现与DNS解析
因为Pod存在生命周期,有销毁,有重建,无法提供一个固定的访问接口给客户端。并且可能同时存在多个副本的。
kubernetes服务发现
1.环境变量:
Pod创建的时候,服务的ip和port会以环境变量的形式注入到pod里,比如pod创建时有一个redis-master服务,服务ip地址是10.0.0.11,port是6379,则会把下面一系列环境变量注入到pod里,通过这些环境变量访问redis-master服务。
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
2.dns:
K8s集群会内置一个dns服务器,service创建成功后,会在dns服务器里导入一些记录,想要访问某个服务,通过dns服务器解析出对应的ip和port,从而实现服务访问
bml的服务发现方式
bml@instance-q2pzfrcc bin]$ curl bml-image:8086
{"code":"AuthenticateError","message":"User authentication failed"}[bml@instance-q2pzfrcc bin]$
[bml@instance-q2pzfrcc bin]$ env | grep image
[bml@instance-q2pzfrcc bin]$ env | grep IMAGE
BML_IMAGE_SERVICE_PORT=8086
BML_IMAGE_PORT_8086_TCP=tcp://10.233.23.206:8086
BML_IMAGE_PORT_8086_TCP_PROTO=tcp
BML_IMAGE_SERVICE_PORT_LISTEN=8086
BML_IMAGE_PORT=tcp://10.233.23.206:8086
BML_IMAGE_PORT_8086_TCP_PORT=8086
BML_IMAGE_PORT_8086_TCP_ADDR=10.233.23.206
BML_IMAGE_SERVICE_HOST=10.233.23.206
[bml@instance-q2pzfrcc bin]$ ping bml-image
PING bml-image.default.svc.cluster.local (10.233.23.206) 56(84) bytes of data.
64 bytes from bml-image.default.svc.cluster.local (10.233.23.206): icmp_seq=1 ttl=64 time=0.077 ms
64 bytes from bml-image.default.svc.cluster.local (10.233.23.206): icmp_seq=2 ttl=64 time=0.051 ms
64 bytes from bml-image.default.svc.cluster.local (10.233.23.206): icmp_seq=3 ttl=64 time=0.052 ms
^C
--- bml-image.default.svc.cluster.local ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2032ms
rtt min/avg/max/mdev = 0.051/0.060/0.077/0.012 ms
[root@instance-q2pzfrcc ~]# kubectl get cm bml-image-config -o yaml
apiVersion: v1
data:
server.conf: |
--env=private
--listen-port=8086
--run-mode=debug
--audit-log-path=log/bml-image.AUDIT
--log-level=DEBUG
--docker-registry-addr=10.233.0.100:5000
--docker-registry-auth=787f5fe5195c40ef924ac8d67948e15a
--docker-registry-api-version=v2
--docker-api-version=1.32
--docker-image-max-size-gb=100
--image-build-type=DockerfileBuild,NotebookExport,TarPackageLoad
--docker-daemon-image=10.233.0.100:5000/docker:rootless
--user-id-in-k8s-job=601
--k8s-config=conf/kube.config
--local-storage-path=/mnt/docker-build
--auth-host=bml-user-manager
--auth-port=8080
--auth-conn-timeout-in-seconds=10
--image-server-access-key=9dd19a75-bc25-11e8-b3b2-90e2ba1fdc4c
--image-server-secret-key=9dd19a75-bc25-11e8-b3b2-90e2ba1fdc4c
--mysql-host=10.233.10.1
--mysql-port=8806
--mysql-user=bdl
--mysql-password=Bdl@Ape2018
--mysql-database=ape_online
--mysql-driver-params=charset=utf8
--storage-service-host=bml-unified-storage
--storage-service-port=8813
--storage-service-timeout=10
--notebook-service-host=bml-notebook-svc
--notebook-service-port=8097
--notebook-service-timeout=10
--resource-service-host=bml-resource
--resource-service-port=8448
--resource-service-timeout=10
--service-authentication-endpoints=192.168.0.4:8081
kind: ConfigMap
metadata:
creationTimestamp: "2020-10-29T08:06:52Z"
name: bml-image-config
namespace: default
resourceVersion: "9401369"
selfLink: /api/v1/namespaces/default/configmaps/bml-image-config
uid: 7dd20a09-e87d-4bd8-8890-34b909e24592
可以看出bml是通过dns来实现服务访问,因为代码里面读取的resource-service-host与端口的配置进行服务的访问。
dns解析
pod的dns解析
https://kubernetes.io/zh/docs/concepts/services-networking/dns-pod-service/
在集群中定义的每个 Service(包括 DNS 服务器自身)都会被指派一个 DNS 名称。
“正常” Service会以 my-svc.my-namespace.svc.cluster.local 这种名字的形式被指派一个 DNS A 记录。这会解析成该 Service 的 Cluster IP。
默认k8s集群的域名为cluster.local
k8s为service资源分配了DNS名称,通过DNS名称可以访问到service对用的pod。而通过statefulset创建的pod,并依赖service headless能实现给statefulset管理的pod提供固定的DNS名称pod-name.service-headless-name.namespace.svc.cluster-domain.example
参考https://blog.51cto.com/leejia/2584207
K8S证书
先从Etcd算起:
1、Etcd对外提供服务,要有一套etcd server证书
2、Etcd各节点之间进行通信,要有一套etcd peer证书
3、Kube-APIserver访问Etcd,要有一套etcd client证书
再算kubernetes:
4、Kube-APIserver对外提供服务,要有一套kube-apiserver server证书
5、kube-scheduler、kube-controller-manager、kube-proxy、kubelet和其他可能用到的组件,需要访问kube-APIserver,要有一套kube-APIserver client证书
6、kube-controller-manager要生成服务的service account,要有一对用来签署service account的证书(CA证书)
7、kubelet对外提供服务,要有一套kubelet server证书
8、kube-APIserver需要访问kubelet,要有一套kubelet client证书
#一般key是私钥,crt是公钥
加起来共8套,但是这里的“套”的含义我们需要理解。
同一个套内的证书必须是用同一个CA签署的,签署不同套里的证书的CA可以相同,也可以不同。例如,所有etcd server证书需要是同一个CA签署的,所有的etcd peer证书也需要是同一个CA签署的,而一个etcd server证书和一个etcd peer证书,完全可以是两个CA机构签署的,彼此没有任何关系。这算两套证书。
为什么同一个“套”内的证书必须是同一个CA签署的
原因在验证这些证书的一端。因为在要验证这些证书的一端,通常只能指定一个Root CA。这样一来,被验证的证书自然都需要是被这同一个Root CA对应的私钥签署,不然不能通过认证。
其实实际上,使用一套证书(都使用一套CA来签署)一样可以搭建出K8S,一样可以上生产,但是理清这些证书的关系,在遇到因为证书错误,请求被拒绝的现象的时候,不至于无从下手,而且如果没有搞清证书之间的关系,在维护或者解决问题的时候,贸然更换了证书,弄不好会把整个系统搞瘫。
master节点:
for i in $(find /etc/kubernetes -type f -name "*.crt");do echo "crt: $i" && openssl x509 -in $i -noout -text|grep Not; done
for i in $(find /etc/kubernetes -type f -name "*.pem");do echo "crt: $i" && openssl x509 -in $i -noout -text|grep Not; done
node节点:
openssl x509 -in /var/lib/kubelet/pki/kubelet-client-current.pem -noout -dates
etcd证书
kubectl create secret generic etcd-client-cert --from-file=etcd-ca=/etc/ssl/etcd/ssl/ca.pem --from-file=etcd-client=/etc/ssl/etcd/ssl/node-bmlc-test-cpu.bcc-bjdd.baidu.com.pem --from-file=etcd-client-key=/etc/ssl/etcd/ssl/node-bmlc-test-cpu.bcc-bjdd.baidu.com-key.pem
网络原理
只查看物理网卡
ls /sys/class/net/ | grep -v "`ls /sys/devices/virtual/net/`"
只查看虚拟网卡
ls /sys/devices/virtual/net/
查看所有网卡
ls /sys/class/net/
查看网卡下面的参数
ifconfig | grep -A 6 vethff22f52e
grep -C 5 foo 匹配foo字串那行以及上下5行
grep -B 5 foo 显示foo及前5行
grep -A 5 foo 显示foo及后5行
什么是cni (network plugin)
CNI**(container network interface)**
CNI插件是可执行文件,会被kubelet调用。启动kubelet --network-plugin=cni,–cni-conf-dir 指定networkconfig配置,默认路径是:/etc/cni/net.d,并且,–cni-bin-dir 指定plugin可执行文件路径,默认路径是:/opt/cni/bin;
CNI plugin 只需要通过 CNI 库实现两类方法, 一类事创建容器时调用, 一类是删除容器时调用.
CNI Plugin负责给容器配置网络,它包括两个基本的接口:
配置网络: AddNetwork(net NetworkConfig, rt RuntimeConf) (types.Result, error)
清理网络: DelNetwork(net NetworkConfig, rt RuntimeConf) error
t**ype CNI interface {
AddNetworkList(net *NetworkConfigList, rt *RuntimeConf) (types.Result, error)
DelNetworkList(net *NetworkConfigList, rt *RuntimeConf) error
AddNetwork(net *NetworkConfig, rt *RuntimeConf) (types.Result, error)
DelNetwork(net *NetworkConfig, rt *RuntimeConf) error
}
kubernetes配置了cni网络插件后,其容器网络创建流程为:
- kubernetes先创建pause容器生成对应的network namespace
- 调用网络driver,因为配置的是CNI,所以会调用CNI相关代码
- CNI driver根据配置调用具体的CNI插件
- CNI插件给pause容器配置正确的网络,pod中其他的容器都是用pause的网络
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MtgRaMuw-1680158062098)(pic/K8S基础/image-20210304112618461.png)]
k8s的网络基础实现
k8s的网络实现是通过iptables加路由的方式
iptables 五链四表
概览
我们知道kube-proxy支持 iptables 和 ipvs 两种模式;
Kubernetes 在版本v1.6中已经支持5000个节点,但使用 iptables 的 kube-proxy 实际上是将集群扩展到5000个节点的瓶颈。 在5000节点集群中使用 NodePort 服务,如果有2000个服务并且每个服务有10个 pod,这将在每个工作节点上至少产生20000个iptable 记录,这可能使内核非常繁忙。
启动ipvs的要求:
- k8s版本 >= v1.11
- 使用ipvs需要安装相应的工具来处理”yum install ipset ipvsadm -y“
- 确保 ipvs已经加载内核模块, ip_vs、ip_vs_rr、ip_vs_wrr、ip_vs_sh、
nf_conntrack_ipv4。如果这些内核模块不加载,当kube-proxy启动后,会退回到iptables模式。
表和链实际上是netfilter的两个维度。
table(表):iptables内置4个table,不同的table代表不同的功能,每个table可以包含许多chain,不同类型的table对所能包含的chain和策略中的target的使用做了限定,一些target不能在一些table中使用。用户不能自定义table;
chain(链):chain可用包括一系列的策略,通过配置不同的chain可以对不同作用的策略进行分类,iptables内置5个chain对应netfilter的5个hook,用户也可以自定义chain;
PREROUTING 路由前
INPUT 发到本机某进程的报文
OUTPUT 本机某进程发出的报文
FORWARD 转发
POSTROUTING 路由后
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g7dAgUaN-1680158062099)(pic/K8S基础/image-20210209153342379.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NO7IXNVg-1680158062099)(pic/K8S基础/image-20210218105557868.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eN9fBPx8-1680158062099)(pic/K8S基础/image-20210218170306054.png)]
1)当一个数据包进入网卡时,它首先进入PREROUTING链,内核根据数据包目的IP判断是否需要转送出去。
2)如果数据包就是进入本机的,它就会沿着图向下移动,到达INPUT链。数据包到了INPUT链后,任何进程都会收到它。本机上运行的程序可以发送数据包,这些数据包会经过OUTPUT链,然后到达POSTROUTING链输出。
3)如果数据包是要转发出去的,且内核允许转发,数据包就会如图所示向右移动,经过FORWARD链,然后到达POSTROUTING链输出。
参考https://www.cnblogs.com/kevingrace/p/6265113.html
具体的四表
- filter表——涉及FORWARD、INPUT、OUTPUT三条链,多用于本地和转发过程中数据过滤;(负责过滤工程,防火墙 )
- Nat表——涉及PREROUTING、OUTPUT、POSTROUT三条链,多用于源地址/端口转换和目标地址/端口的转换;
(网络地址转换功能 network address translate )
-
Mangle表——涉及整条链,可实现拆解报文、修改报文、重新封装,可常见于IPVS的PPC下多端口会话保持。
(拆解报文,做出修改,并重新封装 )
-
Raw表——涉及PREROUTING和OUTPUT链,决定数据包是否被状态跟踪机制处理,需关闭nat表上的连接追踪机制。
(关闭nat表上启用的连接追踪机制)
具体的五链
- INPUT——进来的数据包应用此规则链中的策略
- OUTPUT——外出的数据包应用此规则链中的策略
- FORWARD——转发数据包时应用此规则链路中的策略
- PREROUTING——对数据包作路由选择前应用此链中的规则(所有的数据包进来的时候都先由这个链处理)
- POSTROUTING——对数据包作路由选择后应用此链中的规则(所有的数据包出来的时候都先由这个链处理)
链表关系
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gLj1UFoZ-1680158062099)(./pic/K8S基础/image-20210209152020269.png)]
链表关系
PREROUTING 的规则可存在于:nat表、mangle表、raw表
INPUT 的规则可存在于:mangle表、filter表(nat表centos6没有,centos7有)
FORWARD 的规则可存在于:mangle表、filter表
OUTPUT 的规则可存在于:raw表、mangle表、nat表、filter表
POSTROUTING 的规则可存在于:mangle表、nat表
这个不用硬记,有方法的(iptables -t 表 -L)
当4张表出现在同一条链上的时候,优先级别是:
raw—>mangle—->nat—>filter
iptables语法格式
iptables [-t 表名] 选项 [链名] [条件] [-j 控制类型 ]
| -P | 设置默认策略 iptable |
|---|---|
| -F | 清空规则链 |
| -L | 查看规则链(查看详细规则是对-S的补充) |
| -A | 在规则链的末尾加入新规则 |
| -I | num 在规则链的头部加入新规则 |
| -D | num 删除某一条规则 |
| -s | 匹配来源地址 IP/MASK,加叹号“ !”表示除这个IP外 |
| -S | 使用 -S 命令可以查看这些rules是如何建立的 |
| -d | 匹配目标地址 |
| -i | 网卡名称 匹配从这块网卡流入的数据 入站口 |
| -o | 网卡名称 匹配从这块网卡流出的数据 出站口 |
| -p | 匹配协议,如tcp,udp,icmp |
| –dport num | 匹配目标端口号 |
| –sport num | 匹配来源端口号 |
如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HSe8ZLXv-1680158062100)(pic/K8S基础/image-20210209160733656.png)]
iptables处理动作除了 ACCEPT、REJECT、DROP、REDIRECT 、MASQUERADE 以外,还多出 LOG、ULOG、DNAT、RETURN、TOS、SNAT、MIRROR、QUEUE、TTL、MARK等。
详细参考https://blog.csdn.net/reyleon/article/details/12976341
增删改查
查看
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2PqdlHes-1680158062100)(pic/K8S基础/image-20210209155934998.png)]
可以看到,使用-v选项后,iptables为我们展示的信息更多了,那么,这些字段都是什么意思呢?我们来总结一下,看不懂没关系,等到实际使用的时候,自然会明白,此处大概了解一下即可。
其实,这些字段就是规则对应的属性,说白了就是规则的各种信息,那么我们来总结一下这些字段的含义。
pkts:对应规则匹配到的报文的个数。
bytes:对应匹配到的报文包的大小总和。
·target:规则对应的target,往往表示规则对应的"动作",即规则匹配成功后需要采取的措施。
prot:表示规则对应的协议,是否只针对某些协议应用此规则。
opt:表示规则对应的选项。
in:表示数据包由哪个接口(网卡)流入,我们可以设置通过哪块网卡流入的报文需要匹配当前规则。
out:表示数据包由哪个接口(网卡)流出,我们可以设置通过哪块网卡流出的报文需要匹配当前规则。
source:表示规则对应的源头地址,可以是一个IP,也可以是一个网段。
destination:表示规则对应的目标地址。可以是一个IP,也可以是一个网段。
增加
如果报文来自"192.168.1.146",则表示满足匹配条件,而"拒绝"这个报文,就属于对应的动作,好了,那么怎样用命令去定义这条规则呢?使用如下命令即可
iptables -t filter -I INPUT -s 192.168.1.146 -j DROP
使用 -t选项指定了要操作的表,此处指定了操作filter表,与之前的查看命令一样,不使用-t选项指定表时,默认为操作filter表。
使用-I选项,指明将"规则"插入至哪个链中,-I表示insert,即插入的意思,所以-I INPUT表示将规则插入于INPUT链中,即添加规则之意。
使用-s选项,指明"匹配条件"中的"源地址",即如果报文的源地址属于-s对应的地址,那么报文则满足匹配条件,-s为source之意,表示源地址。
使用-j选项,指明当"匹配条件"被满足时,所对应的动作,上例中指定的动作为DROP,在上例中,当报文的源地址为192.168.1.146时,报文则被DROP(丢弃)。
再次查看filter表中的INPUT链,发现规则已经被添加了,在iptables中,动作被称之为"target",所以,上图中taget字段对应的动作为DROP。
** 注意**
-i 是有顺序的 先插入的规则会拦截追加的规则。
iptables -t filter -I INPUT -s 162.162.1.146 -j DROP
iptables -t filter -A INPUT -s 162.162.1.146 -j ACCEPT
这个-A追加的规则 会被之前的DROP掉,还是不能接受到
iptables -t filter -I INPUT -s 162.162.1.146 -j ACCEPT 这样会重新接收
使用–line-number选项可以列出规则的序号
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1LszQabW-1680158062100)(pic/K8S基础/image-20210209162943407.png)]
指定规则插入
iptables -t filter -I INPUT 2 -s 192.168.1.146 -j DROP
删除
[root@yq01-aip-aikefu08 ~]# iptables -L INPUT --line
Chain INPUT (policy ACCEPT)
num target prot opt source destination
1 ACCEPT all -- 162.162.1.146 anywhere
2 all -- 162.162.1.146 anywhere
3 DROP all -- 162.162.1.146 anywhere
4 KUBE-EXTERNAL-SERVICES all -- anywhere anywhere ctstate NEW /* kubernetes externally-visible service portals */
5 KUBE-FIREWALL all -- anywhere anywhere
6 ACCEPT all -- 162.162.1.146 anywhere
[root@yq01-aip-aikefu08 ~]# iptables -D INPUT 1
[root@yq01-aip-aikefu08 ~]# iptables -L INPUT --line
Chain INPUT (policy ACCEPT)
num target prot opt source destination
1 all -- 162.162.1.146 anywhere
2 DROP all -- 162.162.1.146 anywhere
3 KUBE-EXTERNAL-SERVICES all -- anywhere anywhere ctstate NEW /* kubernetes externally-visible service portals */
4 KUBE-FIREWALL all -- anywhere anywhere
5 ACCEPT all -- 162.162.1.146 anywhere
修改
[root@yq01-aip-aikefu08 ~]# iptables -L INPUT --line
Chain INPUT (policy ACCEPT)
num target prot opt source destination
1 all -- 162.162.1.146 anywhere
2 DROP all -- 162.162.1.146 anywhere
3 KUBE-EXTERNAL-SERVICES all -- anywhere anywhere ctstate NEW /* kubernetes externally-visible service portals */
4 KUBE-FIREWALL all -- anywhere anywhere
5 ACCEPT all -- 162.162.1.146 anywhere
[root@yq01-aip-aikefu08 ~]# iptables -t filter -R INPUT 1 -s 162.162.1.146 -j REJECT
[root@yq01-aip-aikefu08 ~]# iptables -L INPUT --line
Chain INPUT (policy ACCEPT)
num target prot opt source destination
1 REJECT all -- 162.162.1.146 anywhere reject-with icmp-port-unreachable
2 DROP all -- 162.162.1.146 anywhere
3 KUBE-EXTERNAL-SERVICES all -- anywhere anywhere ctstate NEW /* kubernetes externally-visible service portals */
4 KUBE-FIREWALL all -- anywhere anywhere
5 ACCEPT all -- 162.162.1.146 anywhere
保存
我们对"防火墙"所做出的修改都是"临时的",换句话说就是,当重启iptables服务或者重启服务器以后,我们平常添加的规则或者对规则所做出的修改都将消失,为了防止这种情况的发生,我们需要将规则"保存"。
centos6中,使用"service iptables save"命令即可保存规则,规则默认保存在/etc/sysconfig/iptables文件中,如果你刚刚安装完centos6,在刚开始使用iptables时,会发现filter表中会有一些默认的规则,这些默认提供的规则其实就保存在/etc/sysconfig/iptables中,
当我们对规则进行了修改以后,如果想要修改永久生效,必须使用service iptables save保存规则,当然,如果你误操作了规则,但是并没有保存,那么使用service iptables restart命令重启iptables以后,规则会再次回到上次保存/etc/sysconfig/iptables文件时的模样。
centos7中,已经不再使用init风格的脚本启动服务,而是使用unit文件,所以,在centos7中已经不能再使用类似service iptables start这样的命令了,所以service iptables save也无法执行,同时,在centos7中,使用firewall替代了原来的iptables service,不过不用担心,我们只要通过yum源安装iptables与iptables-services即可(iptables一般会被默认安装,但是iptables-services在centos7中一般不会被默认安装),在centos7中安装完iptables-services后,即可像centos6中一样,通过service iptables save命令保存规则了,规则同样保存在/etc/sysconfig/iptables文件中。
iptables应用demo
第一种
输入以下命令:
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8081-8082
iptables -t nat -A PREROUTING -p tcp --dport 8901 -j REDIRECT --to-ports 3306
[root@yq01-aip-aikefu15 ~]# iptables -t nat -L -n --line-number
Chain PREROUTING (policy ACCEPT)
num target prot opt source destination
1 cali-PREROUTING all -- 0.0.0.0/0 0.0.0.0/0 /* cali:6gwbT8clXdHdC1b1 */
2 KUBE-SERVICES all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */
3 DOCKER all -- 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL
4 REDIRECT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:8901 redir ports 3306
# 把8901端口的数据 转发到3306mysql服务上。
通过NAT表的方式吧从端口80接收到的数据随机转发到8001,8002端口
请求还是打在一台机器上,单机器性能
第二种
iptables -t nat -A PREROUTING -d 10.192.0.65/32 -p tcp -m tcp --dport 8080 -m statistic --mode nth --every 2 --packet 0 -j DNAT --to-destination 10.1.160.14:8080
iptables -t nat -A POSTROUTING -d 10.1.160.14/32 -p tcp -m tcp --dport 8080 -j SNAT --to-source 10.192.0.65
iptables -t nat -A PREROUTING -d 10.192.0.65/32 -p tcp -m tcp --dport 8080 -m statistic --mode nth --every 1 --packet 0 -j DNAT --to-destination 10.1.160.15:8080
iptables -t nat -A POSTROUTING -d 10.1.160.15/32 -p tcp -m tcp --dport 8080 -j SNAT --to-source 10.192.0.65
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3jvOFhXE-1680158062101)(pic/K8S基础/image-20210209170840720.png)]
Linux的iptable转发和nginx转发各自优势和差别,分别在什么场景下适用,怎么选择呢?
层次不一样,nginx转发属于应用层,iptables是网络层。
iptables转发一般用于nat内网服务器提供外网应用。比如一个ip做公网,服务器放在内网,公共ip就一个,把服务器就放在公网ip的电脑上话会有些问题,一般还要提供上网服务(做路由器),需要提供的服务可能也很多,比如,www,ftp,mail,那么通过iptables实现端口映射,把不同服务放到不同服务器上,又不需要很多公网ip。
nginx转发主要是负载均衡,而且比较灵活,比如部分转发,转发到不同的服务器上。iptables只能实现全部转发,按照端口,到达端口的数据全部转发给一台服务器。nginx转发http请求就灵活很多,比如对于静态内容,js,css,图片,可以利用memcache等缓存,直接提供服务,而其他复杂的请求可以转发过应用服务器,而且支持多个服务器。
第三种
iptables -t nat -A PREROUTING -d 10.200.36.6 -p tcp -m tcp --dport 3308 -j DNAT --to-destination 10.200.36.7:3309
iptables -t nat -A POSTROUTING -d 10.200.36.7 -p tcp -m tcp --dport 3309 -j SNAT --to-source 10.200.36.6:3308
# 将172.36.20.204:25009 (内网) 的请求转发至10.157.94.208:25009 (外网) @杨子哲
iptables -t nat -A OUTPUT -d 172.36.20.204 -p tcp --dport 25009 -j DNAT --to-destination 10.157.94.208:25009
此Demo 把36.6:3308 转发到 36.7的3309上 。(要在36.6的服务器上执行)
iptables在k8s的作用
kube-proxy只修改了filter和nat表,它对iptables的链进行了扩充,自定义了
KUBE-SERVICES,
KUBE-NODEPORTS,
KUBE-POSTROUTING,
KUBE-MARK-MASQ
KUBE-MARK-DROP
五个链,并主要通过为 KUBE-SERVICES链(附着在PREROUTING和OUTPUT)增加rule来配制traffic routing 规则。
kubernetes的service通过iptables来做后端pod的转发和路由,下面来跟踪具体的规则
SNAT: 改变数据包的源地址。当内网数据包到达防火墙后,防火墙会使用外部地址替换掉数据包的源IP地址(目的IP地址不变),使网络内部主机能够与网络外部主机通信。
DNAT: 改变数据包的目的地址。当防火墙收到来自外网的数据包后,会将该数据包的目的IP地址进行替换(源IP地址不变),重新转发到内网的主机。
DNAT是发送数据的时候隐藏了服务地址,与之对应的是SNAT 隐藏了客户端的ip
SNAT: Source Network Address Translation,是修改网络包源ip地址的。
DNAT: Destination Network Address Translation,是修改网络包目的ip地址的。
[root@yq01-aip-aikefu08 ~]# kubectl get svc --all-namespaces | grep redis-cluster-proxy
default redis-cluster-proxy NodePort 10.233.0.55 <none> 7777:8777/TCP
[root@yq01-aip-aikefu08 ~]# kubectl describe svc redis-cluster-proxy
Name: redis-cluster-proxy
Namespace: default
Labels: app=redis-cluster-proxy
chart=redis-cluster-0.1.1-107446491
heritage=Tiller
release=redis-cluster
Annotations: <none>
Selector: app=redis-cluster-proxy
Type: NodePort
IP: 10.233.0.55
Port: proxy 7777/TCP
TargetPort: 7777/TCP
NodePort: proxy 8777/TCP
Endpoints: 10.233.64.160:7777,10.233.64.162:7777
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
cluster ip : 10.233.0.55
pod ip : 10.233.64.160 ,10.233.64.162
查看nat转发表(KUBE-SERVICES 是k8s自定义链表)
[root@yq01-aip-aikefu08 ~]# iptables -t nat -nvL
Chain PREROUTING (policy ACCEPT 84 packets, 5040 bytes)
pkts bytes target prot opt in out source destination
5216M 752G KUBE-SERVICES all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */
37M 2240M CNI-HOSTPORT-DNAT all -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL
查看svc的链 iptables -t nat -nvL KUBE-SERVICES
[root@yq01-aip-aikefu08 ~]# iptables -t nat -nvL KUBE-SERVICES
Chain KUBE-SERVICES (2 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-MARK-MASQ tcp -- * * !10.233.64.0/18 10.233.0.55
/* default/redis-cluster-proxy:proxy cluster IP */ tcp dpt:7777
0 0 KUBE-SVC-3FNBBYIZCXANEL3B tcp -- * * 0.0.0.0/0 10.233.0.55
/* default/redis-cluster-proxy:proxy cluster IP */ tcp dpt:7777
查看 KUBE-SVC-3FNBBYIZCXANEL3B链
[root@yq01-aip-aikefu08 ~]# iptables -t nat -nvL KUBE-SVC-3FNBBYIZCXANEL3B
Chain KUBE-SVC-3FNBBYIZCXANEL3B (2 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-SEP-E3VN2RK7BFTPB2QU all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.50000000000
0 0 KUBE-SEP-QWICKHRY75ZBMBDW all -- * * 0.0.0.0/0 0.0.0.0/0
发现2个pod是随机0.5概率
查看 KUBE-SEP-E3VN2RK7BFTPB2QU自定义链
[root@yq01-aip-aikefu08 ~]# iptables -t nat -nvL KUBE-SEP-E3VN2RK7BFTPB2QU
Chain KUBE-SEP-E3VN2RK7BFTPB2QU (1 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-MARK-MASQ all -- * * 10.233.64.160 0.0.0.0/0
0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp to:10.233.64.160:7777
发现DNAT转发到10.233.64.160:7777 正是上面的 pod ip
SNAT
[root@yq01-aip-aikefu08 ~]# iptables -t nat -nvL KUBE-POSTROUTING
Chain KUBE-POSTROUTING (1 references)
pkts bytes target prot opt in out source destination
0 0 MASQUERADE all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service traffic requiring SNAT */ mark match 0x4000/0x4000
[root@yq01-aip-aikefu08 ~]#
使用IPVS替代iptables
ipvs 是的svc是可以ping通的。
Kubernetes 在版本v1.6中已经支持5000个节点,但使用 iptables 的 kube-proxy 实际上是将集群扩展到5000个节点的瓶颈。 在5000节点集群中使用 NodePort 服务,如果有2000个服务并且每个服务有10个 pod,这将在每个工作节点上至少产生20000个iptable 记录,这可能使内核非常繁忙。
启动ipvs的要求:
- k8s版本 >= v1.11
从k8s的1.8版本开始,kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于Netfilter,但是采用的hash表,因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能。
kubectl edit cm kube-proxy -n kube-system
#修改如下
kind: MasterConfiguration
apiVersion: kubeadm.k8s.io/v1alpha1
...
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
syncPeriod: 30s
kind: KubeProxyConfiguration
metricsBindAddress: 127.0.0.1:10249
mode: "ipvs" #修改
mode 改为ipvs
改为iptables 则置空字符串""
ipvsadm -L -n
TCP 10.233.64.1:intermapper rr
-> 10.233.64.72:eforward Masq 1 0 0
-> 10.233.64.79:eforward Masq 1 0 0
-> 10.233.64.242:eforward Masq 1 0 0
[root@yq01-aip-aikefu08 ~]# ifconfig | grep -C 10 10.233.64.1
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.233.64.1 netmask 255.255.255.0 broadcast 0.0.0.0
ether 0a:58:0a:e9:40:01 txqueuelen 1000 (Ethernet)
RX packets 4418588876 bytes 8583822053582 (7.8 TiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4314323081 bytes 2952794375912 (2.6 TiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.42.1 netmask 255.255.255.0 broadcast 192.168.42.255
ether 02:42:1a:b3:1e:6a txqueuelen 0 (Ethernet)
RX packets 30110698 bytes 1754904875 (1.6 GiB)
[root@yq01-aip-aikefu08 ~]# kubectl get po --all-namespaces -o wide | grep 10.233.64.72
baiyitong123 zookeeper-baiyitong123-2 2/2 Running 2 156d 10.233.64.72 yq01-aip-aikefu08.yq01 <none>
[root@yq01-aip-aikefu08 ~]# kubectl get po --all-namespaces -o wide | grep 10.233.64.79
baiyitong123 zookeeper-baiyitong123-1 2/2 Running 2 156d 10.233.64.79 yq01-aip-aikefu08.yq01 <none>
[root@yq01-aip-aikefu08 ~]# kubectl get po --all-namespaces -o wide | grep 10.233.64.242
baiyitong123 zookeeper-baiyitong123-0 2/2 Running 2 156d 10.233.64.242 yq01-aip-aikefu08.yq01 <none>
TCP 10.233.64.1:intermapper rr
-> 10.233.64.72:eforward Masq 1 0 0
-> 10.233.64.79:eforward Masq 1 0 0
-> 10.233.64.242:eforward Masq 1 0 0
# 可以发现64.1 是cni0的ip,而下面的pod的ip
参考 https://www.jianshu.com/p/9b4b700c7765
路由
路由英文route
用于多网段通讯,hub只能在通网段内交换数据,路由用于跨网段。
应该翻译成选路器,探路器
所谓“路由”,是指把数据从一个地方传送到另一个地方的行为和动作,而路由器,正是执行这种行为动作的机器,英文名称Router。
路由器的基本功能bai如下:
第一,多网络互连:路由器支持各种局域网dao和广域网shu接口,主要用于互连局域网和广域网,实现不同网络互相通信;
第二,数据处理:提供包括分组过滤、分组转发、优先级、复用、加密、压缩和防火墙等功能;
第三,网络管理:路由器提供包括路由器配置管理、性能管理、容错管理和流量控制等功能。
比如数据到tunl0后,下一步去哪里,这就要看路由表是怎么处理的(k8s上有iptables 、网桥等设备。)
[root@yq01-aip-aikefu08 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.153.204.1 0.0.0.0 UG 100 0 0 enp26s0f0
10.153.204.0 0.0.0.0 255.255.255.0 U 100 0 0 enp26s0f0
10.233.64.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
192.168.42.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0
第一行的意思就是去往所有目标地址数据包由网关10.153.204.1 通过网卡enp26s0f0来转发; #0.0.0.0代表的是匹配所有目标地址
第二行的意思就是去往10.153.204.0 地址的数据包通过enp26s0f0设备来转发
第三行的意思世所有去往10.233.64.0 地址的数据包有cni0虚拟网桥设备进行转发。
-
Destination:路由表 条目使用的网络范围。如果一个IP数据包的目的地址是route输出中某一行的网络的某个部分,那么将会使用这个条目来路由这个数据包。
-
Gateway:指的是一台主机,接受发给指定Destination的数据包。因为这个输出是发自一台主机的(而不是一个作为专门路由器的计算机的),所以路由字段可以是星号(*)或是默认网关;星号表示Destination是在主机所属的网络(因此不需要路由),默认网关指的是将所有非本地的流量都发送到的一个指定IP。
-
Flags:9个单字母的标志位,表示路由表条目的信息。U表示路由启动;G表示路由指向网关、大多数其他标志(都可以通过输入 manroute在route命令的在线帮助手册中找到)只用于专门的路由器,而不是一台单机,表示路由是如何通过路由守护进程来创建和更新。
路由表中Flags标志的含义: Uup (U) 表示当前为启动状态 Hhost (UU) 表示该路由是到一个主机 GGateway(UG) 表示该路由是到一个网关,如果没有说明目的地是直连的 DDynamicaly 表示该路由是由重定向报文创建的 M 表示该路由已被重定向报文修改 -
Metric:到达指定网络所需的中转数(路由器的数目),在Linux内核中没有用。
-
Ref:对这个路由的引用次数,在Linux内核中没有用。
-
Use:这个路由器被路由软件查寻的次数,可以粗略估计通向指定网络地址的网络流量。
-
Iface:表示目的地址,指定网络的数据包应该发往哪个网络借口
可以看到 有三个地址 enp26s0f0 cni0 docker0
calilco 路由实践
[root@node-1 export]# ip route
default via 192.168.146.2 dev ens33 proto static metric 100
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
blackhole 192.168.84.128/26 proto bird
192.168.84.153 dev cali7e70be7574c scope link # 去往 192.168.84.153 地址由cali7e70be7574c进行转发。
192.168.84.154 dev cali7b44816334b scope link
192.168.84.155 dev calib9167cdf781 scope link
192.168.84.160 dev cali58e07406cee scope link
192.168.146.0/24 dev ens33 proto kernel scope link src 192.168.146.11 metric 100
# 所有去往 192.168.146.0/24 地址由ens33进行转发。
[root@node-1 export]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.146.2 0.0.0.0 UG 100 0 0 ens33
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.84.128 0.0.0.0 255.255.255.192 U 0 0 0 *
192.168.84.153 0.0.0.0 255.255.255.255 UH 0 0 0 cali7e70be7574c
# 去往 192.168.84.153 地址由cali7e70be7574c进行转发。
192.168.84.154 0.0.0.0 255.255.255.255 UH 0 0 0 cali7b44816334b
192.168.84.155 0.0.0.0 255.255.255.255 UH 0 0 0 calib9167cdf781
192.168.84.160 0.0.0.0 255.255.255.255 UH 0 0 0 cali58e07406cee
192.168.146.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
添加到主机的路由
# route add -host 192.168.1.2 dev eth0:0
# route add -host 10.20.30.148 gw 10.20.30.40
添加到网络的路由
# route add -net 10.20.30.40 netmask 255.255.255.248 eth0
# route add -net 10.20.30.48 netmask 255.255.255.248 gw 10.20.30.41
# route add -net 192.168.1.0/24 eth1
添加默认路由
# route add default gw 192.168.1.1
删除路由
# route del -host 192.168.1.2 dev eth0:0
# route del -host 10.20.30.148 gw 10.20.30.40
# route del -net 10.20.30.40 netmask 255.255.255.248 eth0
# route del -net 10.20.30.48 netmask 255.255.255.248 gw 10.20.30.41
# route del -net 192.168.1.0/24 eth1
# route del default gw 192.168.1.1 //route del default 删除所有的默认路由
添加一条默认路由
# route add default gw 10.0.0.1 //默认只在内存中生效
开机自启动可以追加到/etc/rc.local文件里
# echo "route add default gw 10.0.0.1" >>/etc/rc.local
添加一条静态路由
# route add -net 192.168.2.0/24 gw 192.168.2.254
要永久生效的话要这样做:
# echo "any net 192.168.2.0/24 gw 192.168.2.254" >>/etc/sysconfig/static-routes
添加到一台主机的静态路由
# route add -host 192.168.2.2 gw 192.168.2.254
要永久生效的话要这样做:
# echo "any host 192.168.2.2 gw 192.168.2.254 " >>/etc/sysconfig/static-routes
注:Linux 默认没有这个文件 ,得手动创建一个
网桥
查看网桥连接容器数量
/etc/kube-` # brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02421ab31e6a no veth8fee902
vethe7ff3cb
veth737444b
vethedc5da2
cni0 8000.0a580ae94001 no veth91209a91
vethb14bfcae
vethbf55dd6e
veth30ab0bf5
veth67325729
veth5e32d144
veth7f275678
veth62bd07df
vethce4d6ffd
docker ps -a | grep http 可以查看都是哪些本地启动的docker容器
docker的网桥
的网桥名称为docker0
容器内的网卡名称
pod内部网卡名称都是eth0
[bml@monitor-6bf7d69ddf-k2tvs /]$ ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1200
inet 10.233.74.167 netmask 255.255.255.255 broadcast 0.0.0.0
ether ca:10:f9:7e:dc:3c txqueuelen 0 (Ethernet)
RX packets 199933945 bytes 281563164821 (262.2 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 328285447 bytes 32891327722 (30.6 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
问题背景
容器中的eth0实际上与宿主机上的某个vethxxxx是pair关系(一对一)。
vethxxx可以通过ifconfig 查看。
但是有没有一个办法可以知道宿主机上的vethxxx,到底是和哪个container eth0 是pair关系呢 ?
排查思路
查找veth 设备对 思路1
[root@yq01-aip-aikefu14 ~]# kubectl exec -it prometheus-operator-grafana-65754b469f-2fxl8 bash -c grafana
grafana@prometheus-operator-grafana-65754b469f-2fxl8:/usr/share/grafana$ cat /sys/class/net/eth0/iflink
797
grafana@prometheus-operator-grafana-65754b469f-2fxl8:/usr/share/grafana$ exit
[root@yq01-aip-aikefu14 ~]# kubectl exec -it prometheus-operator-grafana-65754b469f-2fxl8 bash -c grafana-sc-dashboard
I have no name!@prometheus-operator-grafana-65754b469f-2fxl8:/app$ cat /sys/class/net/eth0/iflink
797
I have no name!@prometheus-operator-grafana-65754b469f-2fxl8:/app$ exit
[root@yq01-aip-aikefu14 ~]# kubectl exec -it prometheus-operator-grafana-65754b469f-2fxl8 bash -c grafana-sc-datasources
I have no name!@prometheus-operator-grafana-65754b469f-2fxl8:/app$ cat /sys/class/net/eth0/iflink
797
可以看到上面都是797
cat /sys/class/net下面的全部目录查看子目录ifindex的值和容器里面查出来的iflink值相当的veth名字
将下面的44 换成实际容器的数字
for i in `ls /sys/class/net`;
do
a=`cat /sys/class/net/$i/ifindex`;
if [[ "797" =~ $a ]]; then
echo $i"<-->"$a
else
echo ""
fi
done;
查看全部
for i in `ls /sys/class/net`;
do
a=`cat /sys/class/net/$i/ifindex`;
echo $i"<-->"$a
done;
[bml@bml-master bin]$ for i in `ls /sys/class/net`;
> do
> a=`cat /sys/class/net/$i/ifindex`;
> echo $i"<-->"$a
> done;
cni0<-->103
docker0<-->3
dummy0<-->6
eth0<-->2
flannel.1<-->102
kube-ipvs0<-->101
lo<-->1
nodelocaldns<-->106
veth0a0ada6d<-->132
veth0f0d4111<-->107
veth15079233<-->128
veth1be34ff5<-->121
veth2040a75a<-->116
veth2f7ac10e<-->129
veth302a88fd<-->104
veth3078c771<-->127
veth36764796<-->131
veth4e6cf0cc<-->114
veth75b35148<-->130
veth7d7ff2f1<-->117
veth807be52e<-->112
veth87bef2e7<-->119
veth91e4d996<-->120
veth976426d7<-->115
veth989bd8e8<-->125
vetha0943e5<-->100
知道这样就找到了pod 和 veth pair的关系。
#!/bin/bash
for container in $(docker ps -q); do
iflink=`docker exec -it $container bash -c 'cat /sys/class/net/eth0/iflink'`
iflink=`echo $iflink|tr -d '\r'`
veth=`grep -l $iflink /sys/class/net/veth*/ifindex`
veth=`echo $veth|sed -e 's;^.*net/\(.*\)/ifindex$;\1;'`
echo $container:$veth
done
查找veth 设备对 思路2
容器里执行,ip link show eth0 命令,然后可以看到 116: eth0@if117,其中116是eth0接口的index, 117是和他pair的veth的index
~ $ ip link show eth0 116: eth0@if117: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP link/ether 02:42:0a:00:04:08 brd ff:ff:ff:ff:ff:ff
在host执行下面命令可以看到对应117的vethinterface是哪一个,这样就得到了container和veth pair关系
# ip link show | grep 117 117: veth145042b@if116: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue master docker0 state UP
pod的网络模型
网络模型概览
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y0laFrMY-1680158062101)(./pic/K8S基础/image-20210207193136449.png)]
同节点
多容器的pod ,原理是docker的 container 模式。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-syhaoBIr-1680158062102)(./pic/K8S基础/image-20210207203301934.png)]
不同的node
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TOLUma95-1680158062102)(./pic/K8S基础/image-20210207203428052.png)]
k8s网络模型
概念
二层网络 : 基于mac链路层的交换网络
三层网络 :基于ip寻址的路由网络。
第2层网络: OSI(Open Systems Interconnections,开放系统互连)网络模型的“数据链路”层。第2层网络会处理网络上两个相邻节点之间的帧传递。第2层网络的一个值得注意的示例是以太网,其中MAC表示为子层。
第3层网络: OSI网络模型的“网络”层。第3层网络的主要关注点,是在第2层连接之上的主机之间路由数据包。IPv4、IPv6和ICMP是第3层网络协议的示例。
-
每个Pod都拥有一个独立的 IP地址,而且 假定所有 Pod 都在一个可以直接连通的、扁平的网络空间中 。
-
不管它们是否运行在同 一 个 Node (宿主机)中,都要求它们可以直接通过对方的 IP 进行访问。
将IP地址和端口在Pod内部和外部都保持一致, 我们可以不使用 NAT 来进行转换,不管是不是处在一个node上,直接访问对方ip就可以访问到,地址空间也自然是平的。
通讯技术,隧道与路由
隧道技术
即node上有服务对容器发出的包进行封装,对发给容器的包进行解封。封装后的包通过node所在的网络进行传输。解封后的包通过网桥或路由直接发给容器,该方案对底层网络没有过高要求,只要求三层可达
隧道方案在 IaaS 层的网络中应用也比较多,将 Pod 分布在一个大二层的网络规模下。网络拓扑简单,但随着节点规模的增长复杂度会提升。基于隧道的overlay网络:按隧道类型来说,不同的公司或者组织有不同的实现方案。
docker原生的overlay网络就是基于vxlan隧道实现的,别的还有flannel udp/vxlan、calico ipip、open vswitch vxlan、rancher ipsec等
路由技术
即node上配置个到各个网段的路由(指向对应容器网段所部属的node IP),通过路由实现互访
路由方案一般是从3层或者2层实现隔离和跨主机容器互通的,出了问题也很容易排查。基于三层实现SDN网络:基于三层协议和路由,直接在三层上实现跨主机网络,并且通过iptables实现网络的安全隔离。没有NAT,效率高,和目前的网络能够融合在一起。代表方案: flannel host-gw, calico bgp、macvlan等
ip的分配与范围与限制
IP是由网关设置的,比如flannel1.1 和calico的tunl0 设置
参考https://kubernetes.io/zh/docs/reference/setup-tools/kubeadm/kubeadm-init/
这里会设置svc与pod IP的 范围
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BUu0y3T7-1680158062102)(./pic/K8S基础/image-20210122204200767.png)]
kubeadm init --kubernetes-version=v1.10.0 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.1.127
svc的ip
svc的ip分配svc的ip分配 是iptables规则是由kube-proxy配置,kube-proxy监视APIserver的更改,因为集群中所有service(iptables)更改都会发送到APIserver上,所以每台kubelet-proxy监视APIserver,当对service或pod虚拟IP进行修改时,kube-proxy就会更新到本地
k8s分配给Service一个固定IP,这是一个虚拟IP(也称为ClusterIP),并不是一个真实存在的IP,无法被ping,没有实体网络对象来响应,是由k8s虚拟出来的。虚拟IP的范围通过k8s API Server的启动参数 --service-cluster-ip-range=19.254.0.0/16配置,虚拟IP属于k8s内部的虚拟网络,外部是寻址不到的。在k8s系统中,实际上是由k8s Proxy组件负责实现虚拟IP路由和转发的,所以k8s Node中都必须运行了k8s Proxy,从而在容器覆盖网络之上又实现了k8s层级的虚拟转发网络
Pod IP是每个Pod的IP地址,它是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,前面我们说过,Kubernetes要求位于不同Node上的Pod能够彼此直接通信,所以Kuberntes里一个Pod里的容器访问另外一个Pod里的容器,就是通过Pod IP所在的虚拟二层网络进行通信的,而真实的TCP/IP流量则是通过Node IP所在的物理网卡流出的
podip分配
flanneld创建了一个flannel.1接口,它是专门用来封装隧道协议的,
当有容器运行后,节点之上创建一个虚拟接口cni0,它是由flanneld创建的一个虚拟网桥叫cni0,在Pod本地通信使用。
flanneld为每个Pod创建一对veth虚拟设备,一端放在容器接口上,一端放在cni0桥上。
pod的ip是overylay网络中calico或者flanel分配
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.233.64.0 netmask 255.255.255.255 broadcast 0.0.0.0
ether 36:86:fb:a5:ba:0b txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
查看pod的ip都是 10.233.64.*
pod1所在的主机的flannel子网为10.0.14.1/24,pod2所在主机的flannel子网为10.0.5.1/24。
每台主机有cni0和flannel.1虚拟网卡。
cni0为在同一主机pod共用的网桥,当kubelet创建容器时,将为此容器创建虚拟网卡vethxxx,并桥接到cni0网桥。
flannel.1是一个tun虚拟网卡,接收不在同一主机的POD的数据,然后将收到的数据转发给flanneld进程。
常见的CNI网络插件
- Flannel(重点):依赖于etcd去存储网络信息的
- Calico:网络限制,网络规则的内容
- Canal:把上面两个结合了,前半部分用F,后半部分用C(没有啥用)
- Contiv:思科开源的
- OpenContrail
- NSX-T
- kube-router:试图取代kube-proxy
flannel
Flannel 是 CoreOS 团队针对 Kubernetes 设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的 Docker 容器都具有全集群唯一的虚拟 IP 地址。
为docker分配不同的IP段
这个IP范围是由Flannel自动分配的,由Flannel通过保存在Etcd服务中的记录确保它们不会重复。
目前,Flannel支持三种不同后端实现,分别是:
UDP
VXLAN
host-gw
UDP是Flannel项目最早支持的一种方式,是性能最差的方式,目前已被废弃。
用的最多的是VXLAN和host-gw模式的部署
Fannel首先连上etcd,利用etcd来管理可分配的IP地址段资源,同时监控etcd中每个Pod的实际地址,并在内存中建立一个Pod节点路由表,将cni0发给它的数据包封装,利用物理网络的连接将数据投递到目标flannel上,从而完成Pod到Pod之间的通信。
Fannel为了不和其他节点上的Pod IP产生冲突,每次都会在etcd中获取IP,Flannel默认使用UDP作为底层传输协议。
架构说明
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IWpDUsw2-1680158062103)(pic/K8S基础/c000b8e56a881a88ef433c239c0a2ba7-20220401174021616.png)]
组件描述:
**Cni0:**网桥设备,每创建一个 Pod 都会创建一对 Veth Pair。其中一端是 Pod 中的 eth0,另一端是 cni0 网桥中的端口(网卡)。
Flannel.1: Overlay 网络的设备,用来进行 Vxlan 报文的处理(封包和解包)。
**Flanneld:**Flannel 在每个主机中运行 Flanneld 作为 Agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段 Subnet,本主机内所有容器的 IP 地址都将从中分配。 Flanneld 监听 K8S 集群数据库,为 Flannel.1 设备提供封装数据时必要的 Mac,IP 等网络数据信息。
flannel启动之前需要设置俩个步骤
添加etcd数据库内容。
etcdctl set /coreos.com/network/config '{ "Networking": "10.1.0.0/16" }'
etcd数据库地址
ExecStart=/usr/bin/flanneld -etcd-endpoints=${FLANNEL_ETCD} $FLANNEL_OPTIONS
然后 启动flannel服务 :systemctl restart flanneld
通讯过程:
flannel 本地搭建步骤
三、搭建(均使用二进制方式安装)
1. flannel需要用到etcd数据库,所以,提前把etcd安装上
1), 官网上下载指定版本的etcd二进制文件,放在/usr/bin目录下
2), 创建etcd配置文件/etc/etcd/etcd.conf文件,修改监听地址和端口
3), 创建etcd受systemctl控制的文件/usr/lib/systemd/system/etcd.service
4), 启动并开机自启,测试etcd是否健康
systemctl start etcd
systemctl enable etcd
etcdctl cluster-health
显示 healthy就代表etcd可以正常工作
2. flannel安装
1.到官网上下载指定的flannel二进制文件包,解压并拷贝到指定位置
wget https://github.com/coreos/flannel/releases/download/v0.7.0/flannel-v0.7.0-linux-amd64.tar.gz
cp flanneld mk-docker-opts.sh /usr/bin
flanneld (主要的执行文件) mk-docker-opts.sh(用于生成Docker启动参数)
2. 给flannel创建一个systemd服务
vim /usr/lib/systemd/system/flanneld.service
[Unit]
Description=flanneld overlay address etcd agent
After=network.target
Before=docker.service
[Service]
Type=notify
EnvironmentFile=/etc/sysconfig/flanneld
ExecStart=/usr/bin/flanneld -etcd-endpoints=${FLANNEL_ETCD} $FLANNEL_OPTIONS
[Install]
RequiredBy=docker.service
WantedBy=multi-user.target
3.配置flannel主配置文件/etc/sysconfig/flanneld
vim /etc/sysconfig/flanneld
# etcd的ip地址和端口
FLANNEL_ETCD="http://192.168.164.130:2379"
# 配置etcd键值对
FLANNEL_ETCD_KEY="/coreos.com/network"
4.在启动flannel之前,要在etcd中添加一条键值对
etcdctl set /coreos.com/network/config '{ "Networking": "10.1.0.0/16" }'
5.启动flannel服务
systemctl restart flanneld
6.设置docker0网桥的IP地址
mk-docker-opts.sh -i
source /run/flannel/subnet.env
7. 重启docker并设置docker0的IP地址
systemctl restart docker
ifconfig docker0 ${FLANNEL_SUBNET}
8. 查看并验证
ip a
docker0 , flannel0网段是相同的就成功了
ping 10.1.50.1 (其他机器的docker0地址) 通了,代表成功
————————————————
版权声明:本文为CSDN博主「mx_steve」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/mx_steve/article/details/103103041
查看flannel模式
进入flannel容器内部
/ # cd /etc/kube-flannel/
/etc/kube-flannel # ls
cni-conf.json net-conf.json
/etc/kube-flannel # cat net-conf.json
{
"Network": "10.233.64.0/18",
"Backend": {
"Type": "vxlan"
}
}
UDP模式
VXLAN模式
原理
在现有的物理世界三层网络之上,“覆盖”一层虚拟的、由内核VXLAN模块负责维护的二层网络,使得连接在这个VXLAN二nfcu网络上的“主机”(虚拟机或容器都可以),可以像在同一个局域网(LAN)里那样自由通信。
pod ip与物理机ip 都可以ping通 全部在一个物理链路内,所以说 " 可以像在同一个局域网(LAN)里那样自由通信。",但是svc ip 是不通的,换成ipvs就可以啦。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tkEtEb8B-1680158062103)(pic/K8S基础/image-20210302152544927.png)]
vetp:
什么是flannel.1接口
VXLAN会在宿主机上设置一个特殊的网络设备作为“隧道”的两端,叫VTEP:VXLAN Tunnel End Point(虚拟隧道端点)
flanel.1设备,就是VXLAN的VTEP,即有IP地址,也有MAC地址
一个flannel.1设备只知道另一端flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么。数据包发给本机的flannel.1接口,即进入二层隧道,然后封装VXLAN包,到达目标Node后,由目标Node上的flannel.1解封装。那这种机制(不用知道node的ipd就可以到达指定的pod)是怎么实现的?
VXLAN包
在linux内核里面,网络设备进行转发的依据,来自FDB的转发数据库,这个flannel.1网桥对应的FDB信息,是由flanneld进程维护的
linux内核再在IP包前面加上二层数据桢头,把Node2的MAC地址填进去。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C4FmrIPU-1680158062103)(pic/K8S基础/image-20210228043622527.png)]
| 数据包头 | 对应内容 |
|---|---|
| Inner Ethernet Header | 目的VTEP设备的mac地址 |
| Inner IP Header | 目的容器ip地址container2 |
| Outer Ethernet Header | 目的主机的MAC地址 or 下一跳路由设备MAC地址 |
| Outer IP Header | 目的主机的ip地址 |
| Outer UDP Header | 隧道数据包都是通过UDP发送的,可靠性由内层数据包TCP协议保证 |
| VXLAN Header | 包含VNI,标志是哪个VXLAN子网的,k8s里面只用到了一个子网,flannel.1 |
这个MAC地址本身,是Node1的ARP表要学习的,需Flannel维护,这时候Linux封装的“外部数据桢”的格式如下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AIFnagDu-1680158062104)(pic/K8S基础/image-20210220144308228.png)]
flanneld创建了一个flannel.1接口,它是专门用来封装隧道协议的,
当有容器运行后,节点之上多了个虚拟接口cni0,它是由flanneld创建的一个虚拟网桥叫cni0,在Pod本地通信使用。
flanneld为每个Pod创建一对veth虚拟设备,一端放在容器接口上,一端放在cni0桥上。
使用brctl show 命令可以查看到网桥上与虚拟网卡的连接
/etc/kube-flannel # brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02421ab31e6a no veth8fee902
vethe7ff3cb
veth737444b
vethedc5da2
cni0 8000.0a580ae94001 no veth91209a91
vethb14bfcae
vethbf55dd6e
veth30ab0bf5
veth67325729
veth5e32d144
veth7f275678
veth62bd07df
vethce4d6ffd
veth8998b075
vethaac1a974
vethf1eadfb1
veth0c1d755d
veth372c5072
veth80bc13d8
vethee459c1e
veth3630303a
veth1b357a53
veth31e13dec
veth5851dd8b
veth6ecbc8a2
vethd0924487
vethc2cc75a1
vethae946f75
veth48875062
veth950b2da3
vethfc5452da
veth3b3216c9
vethd0db59fe
vethecdc6a3e
vethd5e1802f
路由包来源查看
//首先找到pod的ip 10.233.64.48
[root@yq01-aip-aikefu08 net.d]# ip route get 10.233.64.48
10.233.64.48 dev cni0 src 10.233.64.1 uid 0
cache
[root@yq01-aip-aikefu08 net.d]# ifconfig | grep 10.233.64.1 -C 10
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.233.64.1 netmask 255.255.255.0 broadcast 0.0.0.0
ether 0a:58:0a:e9:40:01 txqueuelen 1000 (Ethernet)
RX packets 3642245018 bytes 7898115452741 (7.1 TiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3537375164 bytes 2637628509410 (2.3 TiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
flannel VXLAN网络中,两台主机上的pod间可以直接通信(ping)
跨主机通信:数据包发给本机的flannel.1接口,即进入二层隧道,然后封装VXLAN包,到达目标Node后,由目标Node上的flannel.1解封装。
flanel vxlan模式 数据包流向
通过 netlink 通知内核建立一个 VTEP 的网卡 flannel.1。netlink 是一种用户态和内核态通信的机制。
- 容器 A 通过默认路由到达物理机 A 上的 docker0 网卡。
- 在物理机 A 中,根据路由规则,将包转发给 flannel.1。
- flannel.1 是一个 VXLAN 的 VTEP,将网络包封装。内部 MAC:flannel.1 的 MAC,外加 VXLAN 头。外层 IP:物理机的 IP,外加物理机的 MAC。
- 通过 VXLAN 将包转发给另一台机器,在物理机 B 上的 flannel.1 上解包。
- 根据路由转发到 docker0,最后转发到容器 B。
[root@node-1 ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-deploy-774bdfbcc6-lp456 1/1 Running 0 24h 10.244.0.4 node-1 <none>
nginxdeploy-79cdfdcc96-m5pkh 1/1 Running 0 24h 10.244.1.2 node-2 <none>
[root@node-1 ~]# kubectl exec -it myapp-deploy-774bdfbcc6-lp456 sh
/ # ping 10.244.1.2
目的地址10.244.1.2 与10.244.0.4 不是一个网段
查看路由可以看到
[root@node-1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.146.2 0.0.0.0 UG 100 0 0 ens33
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.1.0 10.244.1.0 255.255.255.0 UG 0 0 0 flannel.1
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.84.128 0.0.0.0 255.255.255.192 U 0 0 0 *
192.168.146.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
数据包需要去走10.244.1.0 网卡,通过flannel.1 发出。
这样数据包就需要路由,查看有arp缓存表,如果没有会去arp广播 “谁是10.244.1.2”
[root@node-1 ~]# arp
Address HWtype HWaddress Flags Mask Iface
10.244.0.3 ether c2:ef:fd:c3:97:a8 C cni0
gateway ether 00:50:56:fa:6e:ae C ens33
10.244.0.4 ether f2:63:a9:ae:29:b2 C cni0
192.168.146.1 ether 00:50:56:c0:00:02 C ens33
node-2 ether 00:0c:29:21:d8:34 C ens33
10.244.1.0 ether 02:17:16:e1:91:d5 CM flannel.1
10.244.0.2 ether 1a:17:fb:4b:0a:f4 C cni0
发现路由表里的目的mac地址是" 02:17:16:e1:91:d5"
查看node-2的网络设备 看看谁是" 02:17:16:e1:91:d5"
[root@node-2 ~]# ifconfig | grep -C 10 02:17:16:e1:91:d5
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.1.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::17:16ff:fee1:91d5 prefixlen 64 scopeid 0x20<link>
ether 02:17:16:e1:91:d5 txqueuelen 0 (Ethernet)
RX packets 295 bytes 24780 (24.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 295 bytes 24780 (24.1 KiB)
TX errors 0 dropped 8 overruns 0 carrier 0 collisions 0
发现node-2的flanel.1设备,,所以发送到node-2的flannel.1上。
从node-1的pod内部ping node-2上的pod的ip,然后在node2上抓包
[root@node-2 ~]# tcpdump -i ens33 -nn icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
发现没有反应
然后换成抓取flannel.1 网关
[root@node-2 ~]# tcpdump -i flannel.1 -nn icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on flannel.1, link-type EN10MB (Ethernet), capture size 262144 bytes
15:49:34.980806 IP 10.244.0.4 > 10.244.1.2: ICMP echo request, id 25088, seq 45, length 64
15:49:34.980906 IP 10.244.1.2 > 10.244.0.4: ICMP echo reply, id 25088, seq 45, length 64
15:49:35.981160 IP 10.244.0.4 > 10.244.1.2: ICMP echo request, id 25088, seq 46, length 64
15:49:35.981385 IP 10.244.1.2 > 10.244.0.4: ICMP echo reply, id 25088, seq 46, length 64
15:49:36.981419 IP 10.244.0.4 > 10.244.1.2: ICMP echo request, id 25088, seq 47, length 64
15:49:36.981514 IP 10.244.1.2 > 10.244.0.4: ICMP echo reply, id 25088, seq 47, length 64
15:49:37.982041 IP 10.244.0.4 > 10.244.1.2: ICMP echo request, id 25088, seq 48, length 64
15:49:37.982100 IP 10.244.1.2 > 10.244.0.4: ICMP echo reply, id 25088, seq 48, length 64
^C
8 packets captured
8 packets received by filter
0 packets dropped by kernel
为什么呢 ?从物理网卡到flanel.1发生了什么?
这里是隧道技术,当物理网卡拿到包时,还是一个包装的,数据包到flannel.1的时候就拆出来为icmp包了,所以可以拿到。
建议使用加端口,数据包会少很多。
node-2上 curl 192.168.146.11:30080/helloworld
node-1上 tcpdump -i any port 30080 -w testhello.pcap
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2cTXrWki-1680158062104)(pic/K8S基础/image-20210303172845007.png)]
host-gw模式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mn7TJ6yz-1680158062104)(pic/K8S基础/662544-20191022103224393-1472403318.png)]
howt-gw模式的工作原理,就是将每个Flannel子网的下一跳,设置成了该子网对应的宿主机的IP地址,也就是说,宿主机(host)充当了这条容器通信路径的“网关”(Gateway),这正是host-gw的含义
所有的子网和主机的信息,都保存在Etcd中,flanneld只需要watch这些数据的变化 ,实时更新路由表就行了。
核心是IP包在封装成桢的时候,使用路由表的“下一跳”设置上的MAC地址,这样可以经过二层网络到达目的宿主机
三层路由方案。每个node节点上都会记录其他节点容器ip段的路由。
通过路由,node A上的容器发给node B上的容器的数据,就能在node A上进行转发,性能好,但要求所有pod在一个子网
比较
udp模式:使用设备flannel.0进行封包解包,不是内核原生支持,上下文切换较大,性能非常差
vxlan模式:使用flannel.1进行封包解包,内核原生支持,性能较强
host-gw模式:无需flannel.1这样的中间设备,直接宿主机当作子网的下一跳地址,性能最强
host-gw的性能损失大约在10%左右,而其他所有基于VXLAN“隧道”机制 的网络方案,性能损失在20%~30%左右
calico
简要
calico的pod
参考:https://blog.51cto.com/14143894/2463392
calico-node 是calico的client和felix,这个会在每个节点都启动一个
calico-kube-controllers这个是calico主要在etcd中动态的获取一些网络规则,处理一些策略都是由这个控制器去完成的,
Overlay网络和Calico网络数据包结构对比(简图):

查看当前模式
查看是否有tunl0 ,有则为ipip模式,没有则是BGP模式
架构

Calico网络模型主要工作组件:
Felix:Calico Agent,运行在每一台 Host 的 agent 进程,主要负责网络接口管理和监听、路由、ARP 管理、ACL 管理和同步、状态上报等,保证跨主机容器的网络互通。
etcd:Calico的后端存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;
BGP Client(BIRD):Calico 为每一台 Host 部署一个 BGP Client,使用 BIRD 实现,BIRD 是一个单独的持续发展的项目,实现了众多动态路由协议比如 BGP、OSPF、RIP 等。负责将Felix 在各Node上的设置通过BGP协议广播到Calico网络,从而实现网络互通。
BGP Route Reflector:在大型网络规模中,如果仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,因为所有节点之间俩俩互联,需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数。
Calico 是一个纯三层的方案,把每个 Node 节点认为是一个路由器,然后把所有的容器认为是连在这个路由器上的网络终端,在路由器之间跑标准的路由协议——BGP 的协议,然后让它们自己去学习这个网络拓扑该如何转发
巧妙的把所有二三层流量转换成三层流量,并通过 Host 上路由配置完成跨 Host 转发
IPIP模式
不要求节点必须在一个网段
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BewoT6JU-1680158062105)(pic/K8S基础/image-20210228043321742.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zS6jvxJt-1680158062105)(pic/K8S基础/image-20210220160316798.png)]
是把一个 IP 数据包放在在一个 IP 包里,即把 IP 层封装到 IP 层的一个Tunnel。而 IPIP 则是通过两端的路由做一个Tunnel,把两个本来不通的网络通过点对点连接起来。Overlay隧道,效率略低
calico-node运行,会自动建一个tunl0,这是ipip做隧道封装用的。
BGP工作模式
要求节点在一个网段
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BBrkGEXB-1680158062106)(pic/K8S基础/image-20210220160302250.png)]
通过路由将通向容器ip的请求导向veth:calic285cddbb40 ,进而让请求直达容器内的网卡。
跟flannel的host-gw模式原理相同,不同之处在于:
- 每个宿主机上的路由规则不是记录在etcd,由单独进程读取维护的,而是通过BGP进行自学习的。
- 不会在宿主机维护一个网桥,而是直接把数据包发送到容器的veth中。
跟flannel host-gw基本一样,没有arp广播的开销,没有隧道封拆包的开销,但是要求节点都在一个网段,跨网段需要上行交换机或路由器支持bgp协议
角色
概念
K8S的认证授权是基于插件的,目前用得最多的是RBAC,也就是基于角色的访问控制
who what how
谁对什么资源有什么样的权限
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Am44gkVz-1680158062106)(pic/K8S基础/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQxNTgyODgz,size_16,color_FFFFFF,t_70.png)]
原理
k8s权限使用:ServiceAccount、Role、RoleBinding使用
-
创建ServiceAccount,注意指定namespace
-
创建role,两种方式,第一种,需要依次指定apiGroups、resources和verbs,便于权限的细粒度控制,
第二种通过通用符"*"设置所有权限,非常方便。
-
RoleBinding,将创建的role和serviceaccount绑定
创建ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
name: test-deri
namespace: test-deri
创建role
创建Role第一种方式
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
namespace: test-deri
name: pod-reader
rules:
- apiGroups: [""] # The API group "" indicates the core API Group.
resources:
- configmaps
- secrets
- nodes
- nodes/metrics
- nodes/stats
- nodes/log
- nodes/spec
- nodes/proxy
- pods
- services
- resourcequotas
- replicationcontrollers
- limitranges
- persistentvolumeclaims
- persistentvolumes
- namespaces
- endpoints
- proxy
verbs:
- list
- watch
- get
- apiGroups:
- extensions
resources:
- daemonsets
- deployments
- replicasets
- ingresses
verbs:
- list
- watch
- apiGroups:
- apps
resources:
- statefulsets
- daemonsets
- deployments
- replicasets
verbs:
- list
- watch
- apiGroups:
- batch
resources:
- cronjobs
- jobs
verbs:
- list
- watch
- apiGroups:
- autoscaling
resources:
- horizontalpodautoscalers
verbs:
- list
- watch
- apiGroups:
- authentication.k8s.io
resources:
- tokenreviews
verbs:
- create
- apiGroups:
- authorization.k8s.io
resources:
- subjectaccessreviews
verbs:
- create
nonResourceURLs: []
创建Role第二种方式
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
namespace: test-deri
name: pod-reader
rules:
- apiGroups:
- '*'
resources:
- '*'
verbs:
- '*'
创建RoleBinding
将创建的role和serviceaccount绑定
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: read-pods
namespace: test-deri
subjects:
- kind: ServiceAccount # May be "User", "Group" or "ServiceAccount"
name: test-deri
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
参考
https://blog.csdn.net/wzy_168/article/details/102956392
光大dashboard只读修改
Kubernetes-dashboard权限收敛操作方法
背景
光大BML环境里kubernetes-dashboard默认有集群全局操作权限,为防止误操作,需要收敛权限
操作步骤
一、去掉skip跳过按钮
执行kubectl edit deployment kubernetes-dashboard -n kubernetes-dashboard,找到并删掉该行:
- –enable-skip-login
保存退出,容器会自动重启生效
效果:界面上去掉了skip按钮
二、创建并获取集群只读权限的token
1、创建role
新建cluster-read.yaml,编辑在里面添加如下内容:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cluster-read
rules:
- apiGroups:
- '*'
resources:
- '*'
verbs:
- 'get'
- 'watch'
- 'list'
- nonResourceURLs:
- '*'
verbs:
- 'get'
- 'watch'
- 'list'
2、创建该ClusterRole对象,执行:
kubectl apply -f cluster-read.yaml
3、创建ServiceAccount对象,执行:
kubectl create sa cluster-read
4、创建ClusterRoleBinding对象,执行:
kubectl create clusterrolebinding cluster-read --clusterrole=cluster-read --serviceaccount=default:cluster-read
5、获取拥有集群只读权限的token:
kubectl get -n default secret $(kubectl get -n default serviceaccount cluster-read -o jsonpath=‘{.secrets[].name}’) -o jsonpath=‘{.data.token}’ | base64 –decode
6、保存该token至本地,后续使用该token访问集群
效果
一、登录时,没有了skip跳过按钮,只有通过kubeconfig和token两种登录选项,可以通过上传kubeconfig文件获得全局操作权限,可以通过指定token控制特定范围内的权限。
比如按上面操作步骤获取到的token是集群全局可读权限,不可进行任何写操作。
二、当在dashboard里进行任何写操作时,会提示在该namespace里对该对象没有操作权限
操作步骤
一、去掉skip跳过按钮
执行kubectl edit deployment kubernetes-dashboard -n kubernetes-dashboard,找到并删掉该行:
- –enable-skip-login
保存退出,容器会自动重启生效
效果:界面上去掉了skip按钮
服务SVC
服务的访问流程
宿主机的ip-----(通过nodeport 到达或者loadBalancer ingress hostNetwork hostPort方式 )------>svc的ip ----(通过ep到达)—>pod的ip
服务类型
service有三种类型:ClusterIP,NodePort,LoadBalancer,
或者说2种服务类型,一种内部网络暴露服务(k8s集群内访问),第二种外部暴露服务(外部系统调用)
K8S的service外部的五种访问方式
有5种方法可以让集群外访问运行在Kubernetes集群上的应用程序(pod)。接下来我们详细讨论Kubernetes的hostNetwork,hostPort,NodePort,LoadBalancer和Ingress功能。
NodePort
NodePort 服务是引导外部流量到你的服务的最原始方式。NodePort,正如这个名字所示,在所有节点上开放一个特定端口,任何发送到该端口的流量都被转发到对应服务。
[root@node-2 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 92d
myapp NodePort 10.110.90.101 <none> 8080:30080/TCP 83d
nginx NodePort 10.98.167.51 <none> 80:32103/TCP 91d
如上图,可以通过访问 三个节点,
http://192.168.146.11:32103/
http://192.168.146.12:32103/
http://192.168.146.13:32103/
都可以访问到
LoadBalancer
LoadBalancer 服务是暴露服务到 internet 的标准方式。在 GKE(Google Kubernetes Engine) 上,这种方式会启动一个 Network Load Balancer,它将给你一个单独的 IP 地址,转发所有流量到你的服务。
Ingress
有别于以上所有例子,Ingress 事实上不是一种服务类型。相反,它处于多个服务的前端,扮演着“智能路由”或者集群入口的角色
参考:https://www.jianshu.com/p/97dd4d59ac5a
k8s 对外暴露服务(service)主要有两种方式:NotePort, LoadBalance, 此外externalIPs也可以使各类service对外提供服务,但是当集群服务很多的时候,NodePort方式最大的缺点是会占用很多集群机器的端口;LB方式最大的缺点则是每个service一个LB又有点浪费和麻烦,并且需要k8s之外的支持; 而ingress则只需要一个NodePort或者一个LB就可以满足所有service对外服务的需求。工作机制大致可以用下图表示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pBIz0fOs-1680158062106)(./pic/K8S技术总结/QQ20200628-120921@2x.png)]
实际上,ingress相当于一个7层的负载均衡器,是k8s对反向代理的一个抽象。大概的工作原理也确实类似于Nginx,可以理解成在 Ingress 里建立一个个映射规则 , ingress Controller 通过监听 Ingress这个api对象里的配置规则并转化成 Nginx 的配置(kubernetes声明式API和控制循环) , 然后对外部提供服务。ingress包括:ingress controller和ingress resources
ingress controller:核心是一个deployment,实现方式有很多,比如nginx, Contour, Haproxy, trafik, Istio,需要编写的yaml有:Deployment, Service, ConfigMap, ServiceAccount(Auth),其中service的类型可以是NodePort或者LoadBalancer。
ingress resources:这个就是一个类型为Ingress的k8s api对象了,这部分则是面向开发人员
hostNetwork
hostNetwork设置适用于Kubernetes pod。当pod配置为hostNetwork:true时,在此类pod中运行的应用程序可以直接查看启动pod的主机的网络接口。配置为侦听所有网络接口的应用程序,又可以在主机的所有网络接口上访问
当pod 设置hostNetwork: true时候,Pod中的所有容器就直接暴露在宿主机的网络环境中,这时候,Pod的PodIP就是其所在Node的IP。
对于同Deployment下的hostNetwork: true启动的Pod,每个node上只能启动一个。也就是说,Host模式的Pod启动副本数不可以多于“目标node”的数量,“目标node”指的是在启动Pod时选定的node,若未选定(没有指定nodeSelector),“目标node”的数量就是集群中全部的可用的node的数量。当副本数大于“目标node”的数量时,多出来的Pod会一直处于Pending状态,因为schedule已经找不到可以调度的node了。
hostPort
这是一种直接定义Pod网络的方式。hostPort是直接将容器的端口与所调度的节点上的端口路由,这样用户就可以通过宿主机的IP加上来访问Pod了,如:
apiVersion: v1
kind: Pod
metadata:
name: influxdb
spec:
containers:
- name: influxdb
image: influxdb
ports:
- containerPort: 8086
hostPort: 8086
这样做有个缺点,因为Pod重新调度的时候该Pod被调度到的宿主机可能会变动,这样就变化了,用户必须自己维护一个Pod与所在宿主机的对应关系。
使用了 hostPort 的容器只能调度到端口不冲突的 Node 上,除非有必要(比如运行一些系统级的 daemon 服务),不建议使用端口映射功能。如果需要对外暴露服务,建议使用 NodePort Service。
CSI 原理
摘要
CSI是 Container Storage Interface 的简称,旨在能为容器编排引擎和存储系统间建立一套标准的存储调用接口,通过该接口能为容器编排引擎提供存储服务。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3mUNWlLO-1680158062107)(pic/K8S基础/image-20210305111815890.png)]
out-of-tree 存储插件现在分为 FlexVolume 和 CSI 两大类。
CSI架构
总结: 按照官方提供的接口 实现后 就开发完成了csi
Kubernetes的CSI架构如下,包含三个部分:
- Kubernetes Core:Kubernetes核心组件
- Kubernetes External Component:Kubernetes官方支持CSI的扩展组件
- External Component:第三方存储厂商开发(开发人员自己实现的接口。)
开发csi插件需要注意两部分:
分别为下图中间与右边的组件
-
由k8s官方维护的一系列external组件负责注册CSI driver 或监听k8s对象资源,从而发起csi driver调用,比如
node-driver-registrar,
external-attacher,
external-provisioner,
external-resizer,
external-snapshotter,
livenessprobe
-
各云厂商or开发者自行开发的组件(需要实现CSI Identity,CSI Controller,CSI Node 接口)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fWZvPDW0-1680158062107)(pic/K8S基础/image-20210304193314751.png)]
架构分析
上图左边是k8s核心组件。
上图中间的是 k8s官方提供 : Kubernetes External Component
上图右边是需要实现的组件接口。
bml 对应上面三个
csi-attacher-bd9d4f4b-wxxrn (这个是官方插件)
csi-provisioner-776f9d4cc5-hrgw9 (这个是官方插件)
bml-csi-plugin-g47p8 包含下面俩个容器,其中一个是官方提供,另一个是bml自己实现。
csi-driver-registrar:1.2.0 (这个是官方插件) 这三个插件正是三个独立的外部组件
bml-storage-csi:46.0.0.34
三个独立的外部组件(External Components),即:Driver Registrar、External Provisioner 、 External Attacher,对应的正是从 Kubernetes 项目里面剥离出来的那部分存储管理功能。
在CSI的框架里,Kubernetes本身需要提供以下三类插件:
Driver registrar
一个Sidecar Container,向Kubernetes注册CSI Driver,添加Drivers的一些信息。
源码: https://github.com/kubernetes-csi/driver-registrar
External provisioner
一个Sidecar Container,监控Kubernetes系统里的PVC对象,调用对应CSI的Volume创建、删除等接口。
源码: https://github.com/kubernetes-csi/external-provisioner
External attacher
一个Sidecar Container,监控Kubernetes系统里的VolumeAttachment对象,调用对应CSI的接口。
源码: https://github.com/kubernetes-csi/external-attacher
下载地址:
https://quay.io/organization/k8scsi
external component(实现如下接口)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BX7RFnnj-1680158062107)(pic/K8S基础/1424868-20210202101223210-714970210.png)]
CSI Identity
负责认证插件的状态信息,实现如下接口:
service Identity {
rpc GetPluginInfo(GetPluginInfoRequest)
returns (GetPluginInfoResponse) {}
rpc GetPluginCapabilities(GetPluginCapabilitiesRequest)
returns (GetPluginCapabilitiesResponse) {}
rpc Probe (ProbeRequest)
returns (ProbeResponse) {}
}
CSI Controller
负责实际创建和管理volumes,实现如下接口:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xdQF4oOY-1680158062108)(pic/K8S基础/image-20210420200514249.png)]
type ControllerServer interface {
CreateVolume(context.Context, *CreateVolumeRequest) (*CreateVolumeResponse, error)
DeleteVolume(context.Context, *DeleteVolumeRequest) (*DeleteVolumeResponse, error)
ControllerPublishVolume(context.Context, *ControllerPublishVolumeRequest) (*ControllerPublishVolumeResponse, error)
ControllerUnpublishVolume(context.Context, *ControllerUnpublishVolumeRequest) (*ControllerUnpublishVolumeResponse, error)
ValidateVolumeCapabilities(context.Context, *ValidateVolumeCapabilitiesRequest) (*ValidateVolumeCapabilitiesResponse, error)
ListVolumes(context.Context, *ListVolumesRequest) (*ListVolumesResponse, error)
GetCapacity(context.Context, *GetCapacityRequest) (*GetCapacityResponse, error)
ControllerGetCapabilities(context.Context, *ControllerGetCapabilitiesRequest) (*ControllerGetCapabilitiesResponse, error)
CreateSnapshot(context.Context, *CreateSnapshotRequest) (*CreateSnapshotResponse, error)
DeleteSnapshot(context.Context, *DeleteSnapshotRequest) (*DeleteSnapshotResponse, error)
ListSnapshots(context.Context, *ListSnapshotsRequest) (*ListSnapshotsResponse, error)
ControllerExpandVolume(context.Context, *ControllerExpandVolumeRequest) (*ControllerExpandVolumeResponse, error)
ControllerGetVolume(context.Context, *ControllerGetVolumeRequest) (*ControllerGetVolumeResponse, error)
}
CSI Node
负责在Kubernetes Node上volume相关的功能,实现如下接口:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-crbKxuvY-1680158062108)(pic/K8S基础/image-20210420200751322.png)]
type NodeServer interface {
//如果存储卷没有格式化,首先要格式化。然后把存储卷mount到一个临时的目录(这个目录通常是节点上的一个全局目录)。再通过NodePublishVolume将存储卷mount到pod的目录中。mount过程分为2步,原因是为了支持多个pod共享同一个volume(如NFS)。
NodeStageVolume(context.Context, *NodeStageVolumeRequest) (*NodeStageVolumeResponse, error)
//NodeStageVolume的逆操作,将一个存储卷从临时目录umount掉
NodeUnstageVolume(context.Context, *NodeUnstageVolumeRequest) (*NodeUnstageVolumeResponse, error)
//将存储卷从临时目录mount到目标目录(pod目录)
NodePublishVolume(context.Context, *NodePublishVolumeRequest) (*NodePublishVolumeResponse, error)
//将存储卷从pod目录umount掉
NodeUnpublishVolume(context.Context, *NodeUnpublishVolumeRequest) (*NodeUnpublishVolumeResponse, error)
//返回可用于该卷的卷容量统计信息。
NodeGetVolumeStats(context.Context, *NodeGetVolumeStatsRequest) (*NodeGetVolumeStatsResponse, error)
//node上执行卷扩容
NodeExpandVolume(context.Context, *NodeExpandVolumeRequest) (*NodeExpandVolumeResponse, error)
//返回Node插件的功能点,如是否支持stage/unstage功能
NodeGetCapabilities(context.Context, *NodeGetCapabilitiesRequest) (*NodeGetCapabilitiesResponse, error)
//返回节点信息
NodeGetInfo(context.Context, *NodeGetInfoRequest) (*NodeGetInfoResponse, error)
}
K8S资源对象
首先从整体上对架构图进行一个描述,Master和Node:Kubernetes将集群中的机器划分为一个Master节点和一群工作节点(Node)。其中,Master节点上运行着集群管理相关的一组进程etcd、API Server、Controller Manager、Scheduler,后三个组件构成了Kubernetes的总控中心,这些进程实现了整个集群的资源管理、Pod调度、弹性伸缩、安全控制、系统监控和纠错等管理功能,并且全都是自动完成。在每个Node上运行Kubelet、Proxy、Docker daemon三个组件,负责对本节点上的Pod的生命周期进行管理,以及实现服务代理的功能。下边对一些重要的概念进行叙述,k8s既然是容器管理系统,就先从容器相关的概念开始:
pod
使用的是docker的container模式
这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。
参考https://blog.csdn.net/weixin_35691526/article/details/112955108
pod有多个容器,它们之间怎么通信?
pod中每个docker容器和pod在一个网络命名空间内,所以ip和端口等等网络配置,都和pod一样,主要通过一种机制就是,docker的一种网络模式,container,新创建的Docker容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等
pod 的网络模型
共享网络空间,但是不共享文件系统,pod 多个容器底层是利用docker的container网络模式
详细参考docker的网络模型中的container模式。
pod的端口 后面是物理端口,是可以在浏览器访问。前面的端口是pod端口
在 kubernetes 的设计中,最基本的管理单位是 pod,而不是 container。pod 是 kubernetes 在容器上的一层封装,由一组运行在同一主机的一个或者多个容器组成。
如果把容器比喻成传统机器上的一个进程(它可以执行任务,对外提供某种功能),那么 pod 可以类比为传统的主机:它包含了多个容器,为它们提供共享的一些资源。Pod包含一个或者多个相关的容器,Pod可以认为是容器的一种延伸扩展,一个Pod也是一个隔离体,而Pod内部包含的一组容器又是共享的(包括PID、Network、IPC、UTS)。除此之外,Pod中的容器可以访问共同的数据卷来实现文件系统的共享。
通过下边这个豆荚的图我们可以看出来pod和container的关系
k8s pod内部容器是共享网络空间的,所以容器直接可以使用localhost访问其他容器
k8s官方推荐的是使用flannel组建一个网络,pod的ip分配由flannel统一分配,通讯过程也是走flannel的网桥
通过下边这个图可以看到pod的几种形式,以及通过加卷的方式共享数据方式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3d712Y1P-1680158062108)(pic/K8S技术总结.assets/pod.png)]
Pod 异常状态
Pending状态
Pending 说明 Pod 还没有调度到某个 Node 上面。可以通过
kubectl describe pod <pod-name> 命令查看到当前 Pod 的事件,进而判断为什么没有调度。可能的原因包括
资源不足,集群内所有的 Node 都不满足该 Pod 请求的 CPU、内存、GPU 等资源
HostPort 已被占用,通常推荐使用 Service 对外开放服务端口
Waiting 或 ContainerCreating状态
首先还是通过 kubectl describe pod <pod-name> 命令查看到当前 Pod 的事件。可能的原因包括
镜像拉取失败,比如配置了镜像错误、Kubelet 无法访问镜像、私有镜像的密钥配置错误、镜像太大,拉取超时等
CNI 网络错误,一般需要检查 CNI 网络插件的配置,比如无法配置 Pod 、无法分配 IP 地址
容器无法启动,需要检查是否打包了正确的镜像或者是否配置了正确的容器参数
ImagePullBackOff状态
这也是我们测试环境常见的,通常是镜像拉取失败。这种情况可以使用 docker pull <image> 来验证镜像是否可以正常拉取。
或者docker images | grep <images>查看镜像是否存在(系统有时会因为资源问题自动删除一部分镜像),
CrashLoopBackOff状态
CrashLoopBackOff 状态说明容器曾经启动了,但可能又异常退出了。此时可以先查看一下容器的日志
kubectl logs <pod-name> kubectl logs --previous <pod-name>
这里可以发现一些容器退出的原因,比如
容器进程退出
健康检查失败退出
Error 状态
通常处于 Error 状态说明 Pod 启动过程中发生了错误。常见的原因包括
依赖的 ConfigMap、Secret 或者 PV 等不存在
请求的资源超过了管理员设置的限制,比如超过了 LimitRange 等
违反集群的安全策略,比如违反了 PodSecurityPolicy 等
容器无权操作集群内的资源,比如开启 RBAC 后,需要为 ServiceAccount 配置角色绑定
Terminating 或 Unknown 状态
从 v1.5 开始,Kubernetes 不会因为 Node 失联而删除其上正在运行的 Pod,而是将其标记为 Terminating 或 Unknown 状态。想要删除这些状态的 Pod 有三种方法:
从集群中删除该 Node。使用公有云时,kube-controller-manager 会在 VM 删除后自动删除对应的 Node。而在物理机部署的集群中,需要管理员手动删除 Node(如 kubectl delete node <node-name>。
Node 恢复正常。Kubelet 会重新跟 kube-apiserver 通信确认这些 Pod 的期待状态,进而再决定删除或者继续运行这些 Pod。
用户强制删除。用户可以执行 kubectl delete pods <pod> --grace-period=0 --force 强制删除 Pod。除非明确知道 Pod 的确处于停止状态(比如 Node 所在 VM 或物理机已经关机),否则不建议使用该方法。
特别是 StatefulSet 管理的 Pod,强制删除容易导致脑裂或者数据丢失等问题。
Evicted状态
出现这种情况,多见于系统内存或硬盘资源不足,可df-h查看docker存储所在目录的资源使用情况,如果百分比大于85%,就要及时清理下资源,尤其是一些大文件、docker镜像。
清除状态为Evicted的pod:
kubectl get pods | grep Evicted | awk '{print $1}' | xargs kubectl delete pod
删除所有状态异常的pod:
kubectl delete pods $(kubectl get pods | grep -v Running | cut -d ' ' -f 1)
删除集群中没有在使用的docker镜像(慎用):
docker system prune -a
查看pod对应的服务(镜像)版本:
kubectl --server=127.0.0.1:8888 get rc -o yaml | grep image: |uniq | sort | grep ecs-core
Service(svc)
pod的dns解析
https://kubernetes.io/zh/docs/concepts/services-networking/dns-pod-service/
在集群中定义的每个 Service(包括 DNS 服务器自身)都会被指派一个 DNS 名称。
“正常” Service会以 my-svc.my-namespace.svc.cluster.local 这种名字的形式被指派一个 DNS A 记录。这会解析成该 Service 的 Cluster IP。
个人认为这是k8s重要性仅次于pod的概念,众所周知,pod生命周期短,状态不稳定,pod异常后新生成的pod ip会发生变化,之前pod的访问方式均不可达。
通过service对pod做代理,service有固定的ip和port,ip:port组合自动关联后端pod,即使pod发生改变,kubernetes内部更新这组关联关系,使得service能够匹配到新的pod。这样,通过service提供的固定ip,用户再也不用关心需要访问哪个pod,以及pod是否发生改变,大大提高了服务质量。如果pod使用rc创建了多个副本,那么service就能代理多个相同的pod,所以service可以认为是一组pod的代理或者是更高层的抽象,其他的service通过本service提供的虚拟IP进行访问,也可以在service中对代理的一组pod提供负载服务。
现在,假定有2个后台Pod,并且定义后台Service的名称为‘backend-service’,lable选择器为(tier=backend, app=myapp)。backend-service 的Service会完成如下两件重要的事情:会为Service创建一个本地集群的DNS入口,因此前端(frontend)Pod只需要DNS查找主机名为 ‘backend-service’,就能够解析出前端应用程序可用的IP地址。现在前端已经得到了后台服务的IP地址,但是它应该访问2个后台Pod的哪一个呢?Service在这2个后台Pod之间提供透明的负载均衡,会将请求分发给其中的任意一个(如下面的动画所示)。通过每个Node上运行的代理(kube-proxy)完成。
创建一个service代理外部的服务
(1条消息) k8s中service代理外部的服务_MssGuo的博客-CSDN博客_k8s访问外部服务
[root@master endpoint]# cat outside_agent_nginx.yaml
---
apiVersion: v1
kind: Service
metadata:
name: outside-agent-svc #service的名称叫做outside-agent-svc
namespace: default
spec:
ports:
- name: out-agent-port #service端口的名称
port: 8056 #service的端口
protocol: TCP #端口协议
# targetPort: 80 #目标端口可以不定义,因为我们代理的不是pod,不定义targetPort,其默认等于port
sessionAffinity: None
type: ClusterIP
---
apiVersion: v1
kind: Endpoints
metadata:
name: outside-agent-svc #endpoint的名称一定要与service的名称一致
namespace: default
subsets:
- addresses:
- ip: 192.168.118.129 #定义外部服务地址
ports:
- port: 80 #外部服务的端口
name: out-agent-port #端口的name,这个名称一定要与service端口的名称
protocol: TCP #端口协议,这个协议一定要与service的端口协议一致
[root@master endpoint]#
Endpoints(ep)
当有连接通过ClusterIP 到达Service的时候,service将根据endpoints提供的信息进行路由请求pod,Endpoints的变化可以通过k8s中的selectors手动或自动的被发现.
如下,可以查看到get ep 与svc的服务是一致的
kubectl get ep --all-namespaces
[root@node-2 ~]# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 192.168.146.11:6443 92d
myapp 10.244.1.121:8080,10.244.2.218:8080 83d
nginx 10.244.2.217:80 91d
[root@node-2 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 92d
myapp NodePort 10.110.90.101 <none> 8080:30080/TCP 83d
nginx NodePort 10.98.167.51 <none> 80:32103/TCP 91d
headless service
参考 :kubernetes: headless service_feiger的专栏-CSDN博客_headless service
有时候我们创建的服务不想走 负载均衡,想直接通过 pod-ip 链接后端, 怎么办呢, 使用headless service接可以解决。
1.什么是headless service
headless service 是将service的发布文件中的clusterip=none ,不让其获取clusterip , DNS解析的时候直接走pod
原文链接:https://blog.csdn.net/textdemo123/article/details/102954489
root@gzbh-intel006.gzbh.baidu.com:/root # kubectl get svc | grep redis
det-registry-externalredis-master ClusterIP 10.233.9.70 <none> 6379/TCP 163d
det-registry-externalredis-slave ClusterIP 10.233.53.182 <none> 6379/TCP 163d
easydata-redis-statefulset ClusterIP 10.233.56.175 <none> 6379/TCP 163d
redis-cluster ClusterIP 10.233.33.45 <none> 6379/TCP 163d
redis-cluster-headless ClusterIP None <none> 6379/TCP,16379/TCP 163d
redis-cluster-metrics ClusterIP 10.233.0.238 <none> 9121/TCP 163d
tn-redis-service ClusterIP 10.233.50.151 <none> 6379/TCP 163d
可以看到上面的headless 没有clusterip
root@gzbh-intel006.gzbh.baidu.com:/root # kubectl describe svc redis-cluster-headless
Name: redis-cluster-headless
Namespace: default
Labels: app.kubernetes.io/instance=redis-cluster
app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=redis-cluster
helm.sh/chart=redis-cluster-6.2.5-v1.2.1.14
Annotations: <none>
Selector: app.kubernetes.io/instance=redis-cluster,app.kubernetes.io/name=redis-cluster
Type: ClusterIP
IP: None
Port: tcp-redis 6379/TCP
TargetPort: tcp-redis/TCP
Endpoints: 10.233.64.169:6379,10.233.64.181:6379,10.233.64.23:6379 + 3 more...
Port: tcp-redis-bus 16379/TCP
TargetPort: tcp-redis-bus/TCP
Endpoints: 10.233.64.169:16379,10.233.64.181:16379,10.233.64.23:16379 + 3 more...
Session Affinity: None
Events: <none>
可以看到ip为none,说明没有ClusterIP
root@gzbh-intel006.gzbh.baidu.com:/root # kubectl describe ep redis-cluster-headless
Name: redis-cluster-headless
Namespace: default
Labels: app.kubernetes.io/instance=redis-cluster
app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=redis-cluster
helm.sh/chart=redis-cluster-6.2.5-v1.2.1.14
service.kubernetes.io/headless=
Annotations: endpoints.kubernetes.io/last-change-trigger-time: 2022-06-27T08:16:36Z
Subsets:
Addresses: 10.233.64.169,10.233.64.181,10.233.64.23,10.233.64.231,10.233.64.47,10.233.64.53
NotReadyAddresses: <none>
Ports:
Name Port Protocol
---- ---- --------
tcp-redis-bus 16379 TCP
tcp-redis 6379 TCP
Events: <none>
root@gzbh-intel006.gzbh.baidu.com:/root # kubectl get po -o wide | grep redis
det-registry-externalredis-master-0 1/1 Running 0 2d10h 10.233.64.39 gzbh-intel006.gzbh.baidu.com <none> <none>
det-registry-externalredis-slave-69fb4658d6-slnzx 1/1 Running 3 2d9h 10.233.64.2 gzbh-intel006.gzbh.baidu.com <none> <none>
easydata-redis-statefulset-0 1/1 Running 0 2d9h 10.233.64.13 gzbh-intel006.gzbh.baidu.com <none> <none>
easydata-redis-statefulset-1 1/1 Running 0 2d4h 10.233.64.100 gzbh-intel006.gzbh.baidu.com <none> <none>
easydata-redis-statefulset-2 1/1 Running 0 2d4h 10.233.64.118 gzbh-intel006.gzbh.baidu.com <none> <none>
redis-cluster-0 2/2 Running 1 2d10h 10.233.64.47 gzbh-intel006.gzbh.baidu.com <none> <none>
redis-cluster-1 2/2 Running 2 2d10h 10.233.64.169 gzbh-intel006.gzbh.baidu.com <none> <none>
redis-cluster-2 2/2 Running 1 2d10h 10.233.64.231 gzbh-intel006.gzbh.baidu.com <none> <none>
redis-cluster-3 2/2 Running 1 2d10h 10.233.64.53 gzbh-intel006.gzbh.baidu.com <none> <none>
redis-cluster-4 2/2 Running 2 2d10h 10.233.64.181 gzbh-intel006.gzbh.baidu.com <none> <none>
redis-cluster-5
可以看到直接访问到pod上。
Node
Node是Kubernetes中的工作节点,最开始被称为minion。一个Node可以是VM或物理机。每个Node(节点)具有运行pod的一些必要服务,并由Master组件进行管理,Node节点上的服务包括Docker、kubelet和kube-proxy。目前Kubernetes支持docker和rkt两种容器
StatefulSet
(用来部署有状态的服务)
mysql 多个部署
三个mysql的pvc是独立的,名称是独立的,如果是deployment ,挂载的卷,则不会创建多个pv
step1:创建mysql的命名空间、sc
cat << EOF > mysql-ns.yaml
apiVersion: v1
kind: Namespace
metadata:
name: mysql-sts
EOF
cat << EOF > mysql-sc.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: mysql-nfs-storage
provisioner: fuseim.pri/ifs # or choose another name, must match deployment's env PROVISIONER_NAME'
parameters:
archiveOnDelete: "false" # # When set to "false" your PVs will not be archived
# by the provisioner upon deletion of the PVC.
EOF
step2:部署mysql的statefulset
cat << EOF > mysql-ss.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
namespace: mysql-sts
spec:
selector:
matchLabels:
app: mysql #必须匹配 .spec.template.metadata.labels
serviceName: "mysql" #声明它属于哪个Headless Service.
replicas: 3 #副本数
template:
metadata:
labels:
app: mysql # 必须配置 .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mysql
image: www.my.com/sys/mysql:5.7
ports:
- containerPort: 3306
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
volumeMounts:
- name: mysql-pvc
mountPath: /var/lib/mysql
volumeClaimTemplates: #可看作pvc的模板
- metadata:
name: mysql-pvc
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "mysql-nfs-storage" #存储类名,改为集群中已存在的
resources:
requests:
storage: 1Gi
EOF
创建svc
cat << EOF > mysql-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: mysql
namespace: mysql-sts
labels:
app: mysql
spec:
ports:
- port: 3306
name: mysql
clusterIP: None
selector:
app: mysql
EOF
三个mysql的pvc是独立的,名称是独立的,如果是deploy ,则不会创建多个pv
三个mysql的pod数据是相互独立的
在Deployment中,与之对应的服务是service,而在StatefulSet中与之对应的headless service,headless service,即无头服务,与service的区别就是它没有Cluster IP,解析它的名称时将返回该Headless Service对应的全部Pod的Endpoint列表
为什么需要 headless service 无头服务?
在用Deployment时,每一个Pod名称是没有顺序的,是随机字符串,因此是Pod名称是无序的,但是在statefulset中要求必须是有序 ,每一个pod不能被随意取代,pod重建后pod名称还是一样的。而pod IP是变化的,所以是以Pod名称来识别。pod名称是pod唯一性的标识符,必须持久稳定有效。这时候要用到无头服务,它可以给每个Pod一个唯一的名称 。
参考:
Kubernetes——StatefulSet详解 - 简书 (jianshu.com)
k8s之StatefulSet详解_最美dee时光的博客-CSDN博客
部署多个nginx,并且互相独立
nginx-ss.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
namespace: nginx-ss
spec:
selector:
matchLabels:
app: nginx #必须匹配 .spec.template.metadata.labels
serviceName: "nginx" #声明它属于哪个Headless Service.
replicas: 3 #副本数
template:
metadata:
labels:
app: nginx # 必须配置 .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: www.my.com/web/nginx:v1
ports:
- containerPort: 80
name: web
volumeMounts:
- name: nginx-pvc
mountPath: /usr/share/nginx/html
volumeClaimTemplates: #可看作pvc的模板
- metadata:
name: nginx-pvc
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "nginx-nfs-storage" #存储类名,改为集群中已存在的
resources:
requests:
storage: 1Gi
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2pLsVVHL-1680158062108)(pic/K8S基础/image-20211207154540609.png)]
#第一个是创建web-0
$ kubectl get pod
web-0 1/1 ContainerCreating 0 51s
#待web-0 running且ready时,创建web-1
$ kubectl get pod
web-0 1/1 Running 0 51s
web-1 0/1 ContainerCreating 0 42s
#待web-1 running且ready时,创建web-2
$ kubectl get pod
web-0 1/1 Running 0 1m
web-1 1/1 Running 0 45s
web-2 1/1 ContainerCreating 0 36s
#最后三个Pod全部running且ready
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 4m
web-1 1/1 Running 0 3m
web-2 1/1 Running 0 1m
根据volumeClaimTemplates自动创建的PVC
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-web-0 Bound pvc-ecf003f3-828d-11e8-8815-000c29774d39 2G RWO gluster-heketi 7m
www-web-1 Bound pvc-0615e33e-828e-11e8-8815-000c29774d39 2G RWO gluster-heketi 6m
www-web-2 Bound pvc-43a97acf-828e-11e8-8815-000c29774d39 2G RWO gluster-heketi 4m
本质上是Deployment的一种变体
RC、Deployment、DaemonSet都是面向无状态的服务,它们所管理的Pod的IP、名字,启停顺序等都是随机的,而StatefulSet是什么?顾名思义,有状态的集合,管理所有有状态的服务,比如MySQL、MongoDB集群等。
Pod一致性:包含次序(启动、停止次序)、网络一致性。此一致性与Pod相关,与被调度到哪个node节点无关;
稳定的次序:对于N个副本的StatefulSet,每个Pod都在[0,N)的范围内分配一个数字序号,且是唯一的;
稳定的网络:Pod的hostname模式为( s t a t e f u l s e t 名 称 ) − (statefulset名称)-(statefulset名称)−(序号);
稳定的存储:通过VolumeClaimTemplate为每个Pod创建一个PV。删除、减少副本,不会删除相关的卷。
daemonsets
(每个节点有一个)
Deployment
(用来部署无状态的服务)
k8s–基础–15–Deployment和ReplicaSet的区别 周飞的博客-CSDN博客
- Deployment控制器是工作在ReplicaSet之上的,Deployment通过控制ReplicaSet来控制pod,并不是直接控制pod。
Replication Controller(RC)或者 ReplicaSet (RS)
kubernetes RC(Replication Controller)和RS(Replicaset)的作用和区别_软件工程小施同学的博客-CSDN博客
rs是通过=号的 rc可以通过集合lable
kubectl get rc
kubectl get rs
是Kubernetes中的另一个核心概念,它的职责是确保集群中有且仅有N个Pod实例,N是RC中定义的Pod副本数量。通过调整RC中的spec.replicas属性值来实现系统扩容或缩容。通过改变RC中的Pod模板来实现系统的滚动升级。
Replication Controller确保任意时间都有指定数量的Pod“副本”在运行。如果为某个Pod创建了Replication Controller并且指定3个副本,它会创建3个Pod,并且持续监控它们。如果某个Pod不响应,那么Replication Controller会替换它,保持总数为3.如果之前不响应的Pod恢复了,现在就有4个Pod了,那么Replication Controller会将其中一个终止保持总数为3。如果在运行中将副本总数改为5,Replication Controller会立刻启动2个新Pod,保证总数为5。
kubectl get deploy
可以直接删除某个Deployment 来释放这个应用
参考:https://www.cloudcared.cn/2969.html
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VPGW6eXK-1680158062109)(pic/K8S技术总结.assets/deploy.png)]
IP
宿主机的ip-----(通过nodeport 到达或者loadBalancer ingress hostNetwork hostPort方式 )------>svc的ip ----(通过ep到达)—>pod的ip
Node IP:Node节点的物理IP地址
Pod IP:Pod的IP地址
Cluster IP:Service的IP地址
k8s分配给Service一个固定IP,这是一个虚拟IP(也称为ClusterIP),并不是一个真实存在的IP,无法被ping,没有实体网络对象来响应,是由k8s虚拟出来的。虚拟IP的范围通过k8s API Server的启动参数 --service-cluster-ip-range=19.254.0.0/16配置,虚拟IP属于k8s内部的虚拟网络,外部是寻址不到的。在k8s系统中,实际上是由k8s Proxy组件负责实现虚拟IP路由和转发的,所以k8s Node中都必须运行了k8s Proxy,从而在容器覆盖网络之上又实现了k8s层级的虚拟转发网络
Pod IP是每个Pod的IP地址,它是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,前面我们说过,Kubernetes要求位于不同Node上的Pod能够彼此直接通信,所以Kuberntes里一个Pod里的容器访问另外一个Pod里的容器,就是通过Pod IP所在的虚拟二层网络进行通信的,而真实的TCP/IP流量则是通过Node IP所在的物理网卡流出的
Label
参考:https://www.cnblogs.com/benjamin77/p/9901912.html
Label机制是Kubernetes中的一个重要设计,通过Label进行对象的弱关联,可以灵活地进行分类和选择,Label是识别Kubernetes对象(Pod、Service、RC、Node)的标签,以key/value的方式附加到对象上,Label不提供唯一性,比如可以关联Service和Pod。Label定义好后其他对象可以使用Label Selector来选择一组相同label的对象。
Label是Kubernetes系统中的一个核心概念。Label以key/value键值对的形式附加到任何对象上,如Pod,Service,Node,RC(ReplicationController)/RS(ReplicaSet)等。
Label可以在创建对象时就附加到对象上,也可以在对象创建后通过API进行额外添加或修改。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cyx4HEOd-1680158062109)(./pic/K8S技术总结/17993869-ea1ea593da2ffd51.png)]
如上图
spec.selector.matchLabels 字段来指定这个deploy管理哪些Pod。
通过template.metadata.labels字段为即将新建的Pod附加Label
这样就可以保证deploy控制console这个pod了
[root@yq01-aip-det-cpu01 ~]# kubectl get deployments.apps bdl-console -o yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2020-12-09T17:52:59Z"
generation: 1
name: bdl-console
namespace: default
resourceVersion: "9270"
selfLink: /apis/apps/v1/namespaces/default/deployments/bdl-console
uid: 65c77c40-4884-411d-b5ab-39ee360c94d3
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: bdl-console
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: bdl-console
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- yq01-aip-det-cpu01.yq01
weight: 1
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/cluster-role
operator: NotIn
values:
- slave
containers:
- command:
- /bin/sh
- -c
- 'source ~/.bashrc && mkdir -p /home/bml/bdl-console/tmp/ && cp -R /home/bml/bdl-console/frontend
/home/bml/bdl-console/frontend-mem && cd /home/bml/bdl-console/bin && /opt/jdk1.8.0_111/bin/java
-Djava.io.tmpdir=/home/bml/bdl-console/tmp/ -Dspring.config.location=/home/bml/bdl-console/conf/application.properties
-Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8 -Dloader.path=./lib/ -Xmx$MAX_MEMORY
-XX:MaxPermSize=512M -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCDateStamps
-Xloggc:gc.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=20M
-jar $APPLICATION '
env:
- name: STORAGE_PATH_PREFIX
value: /home/bml/storage/mnt
- name: SYSTEM_VOLUME_ID
value: v-system-volume
- name: PVC_NAME
value: bml-all-pvc
image: 10.233.0.100:5000/bdl-console:4.4.4.10
imagePullPolicy: IfNotPresent
name: bdl-console
resources:
limits:
cpu: "2"
memory: 2Gi
requests:
cpu: 250m
memory: 512Mi
securityContext:
privileged: true
runAsNonRoot: true
runAsUser: 601
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /home/bml/bdl-console/log
name: bdl-console-log
- mountPath: /etc/hosts
name: host-name
- mountPath: /home/bml/bdl-console/conf/application.properties
name: config-volume
subPath: application.properties
- mountPath: /home/bml/bdl-console/conf/logback.xml
name: config-volume
subPath: logback.xml
- mountPath: /etc/resolv.conf
name: config-volume
subPath: resolv.conf
- mountPath: /home/bml/storage/mnt
mountPropagation: HostToContainer
name: bml-storage
- mountPath: /home/bml/bdl-console/frontend-mem
name: frontend-mem
dnsPolicy: ClusterFirst
hostNetwork: true
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
- name: bml-storage
persistentVolumeClaim:
claimName: bml-all-pvc
- hostPath:
path: /mnt/log/bdl-console
type: ""
name: bdl-console-log
- hostPath:
path: /etc/hosts
type: ""
name: host-name
- configMap:
defaultMode: 420
name: bdl-console-config
name: config-volume
- emptyDir:
medium: Memory
name: frontend-mem
status:
availableReplicas: 1
conditions:
- lastTransitionTime: "2020-12-09T17:53:41Z"
lastUpdateTime: "2020-12-09T17:53:41Z"
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: "2020-12-09T17:52:59Z"
lastUpdateTime: "2020-12-09T17:53:41Z"
message: ReplicaSet "bdl-console-bc5845f99" has successfully progressed.
reason: NewReplicaSetAvailable
status: "True"
type: Progressing
observedGeneration: 1
readyReplicas: 1
replicas: 1
updatedReplicas: 1
[root@yq01-aip-det-cpu01 ~]#
demo
文件名:service-svc-hello.yaml
apiVersion: v1
kind: Service
metadata:
name: hello
labels:
app: hello
spec:
ports:
- port: 80
targetPort: 80
selector:
app: hello
Service 的 spec 部分就是它的主要信息,主要包含以下内容:
-
ports: 是一个端口信息列表,也就是说一个 Service 可以管理多个端口的访问。本身 Pod 可以对外暴露多个端口
port: service 绑定的端口,也就是这个 Service 所对应的 ip 监听的端口targetPort: backend 的端口,也就是 Pod 所暴露的端口
-
selector: 标签选择,符合这个标签的 Pod 会作为这个 Service 的 backend。
Pod DNS 策略
POD里的DNS策略可以对每个pod进行设置,他支持四种策略default,ClusterFirst,ClusterFirstWithHostNet,None:
default: 表示 Pod 里面的 DNS 配置继承了宿主机上的 DNS 配置。简单来说,就是该 Pod 的 DNS 配置会跟宿主机完全一致。也就是和node上的dns配置是一样的
ClusterFirst:相对于上述的 Default,ClusterFirst 是完全相反的操作,它会预先把 kube-dns(或 CoreDNS)的信息当作预设参数写入到该 Pod 内的 DNS 配置。ClusterFirst 是默认的pod设置,若没有在 Pod 內特別描述 PodPolicy, 则会将 dnsPolicy 预设为 ClusterFirst.不过ClusterFirst 还有一个冲突,如果你的 Pod 设置了 HostNetwork=true,则 ClusterFirst 就会被强制转换成 Default。
ClusterFirstWithHostNet:如果pod是桥接的模式, dnsPolicy 将设置为ClusterFirstWithHostNet,他将同时解决default和ClusterFirst的DNS解析。
None: 表示会清除 Pod 预设的 DNS 配置,当 dnsPolicy 设置成这个值之后,Kubernetes 不会为 Pod 预先载入任何自身逻辑判断得到的 DNS 配置。因此若要将 dnsPolicy 的值设为 None,为了避免 Pod 里面没有配置任何 DNS,最好再添加 dnsConfig 来描述自定义的 DNS 参数
ConfigMap
kubectl get cm
很多生产环境中的应用程序配置较为复杂,可能需要多个config文件、命令行参数和环境变量的组合。使用容器部署时,把配置应该从应用程序镜像中解耦出来,以保证镜像的可移植性。尽管Secret允许类似于验证信息和秘钥等信息从应用中解耦出来,但在K8S1.2前并没有为了普通的或者非secret配置而存在的对象。在K8S1.2后引入ConfigMap来处理这种类型的配置数
建立configMap
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EALwYB8G-1680158062110)(.pic/K8S技术总结.assets/编写.png)]
创建pod的时候定义卷
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VJQ5TKTp-1680158062110)(pic/K8S技术总结.assets/定义卷.png)]
pod 挂载卷
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SzunVGnc-1680158062110)(pic/K8S技术总结.assets/挂载.png)]
进入pod 查看文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5afbCGlW-1680158062111)(pic/K8S技术总结.assets/查看.png)]
Secret
Secret 为什么安全?
主要是 Kubernetes 对 Secret对象采取额外了预防措施。
-
传输安全
在大多数 Kubernetes 项目维护的发行版中,用户与 API server 之间的通信以及从 API server 到 kubelet 的通信都受到 SSL/TLS 的保护。对于开启 HTTPS 的 Kubernetes 来说 Secret 受到保护所以是安全的。 -
存储安全
只有当挂载 Secret 的POD 调度到具体节点上时,Secret 才会被发送并存储到该节点上。但是它不会被写入磁盘,而是存储在 tmpfs 中。一旦依赖于它的 POD 被删除,Secret 就被删除。
由于节点上的 Secret 数据存储在 tmpfs 卷中,因此只会存在于内存中而不会写入到节点上的磁盘。以避免非法人员通过数据恢复等方法获取到敏感信息.
- 访问安全
同一节点上可能有多个 POD 分别拥有单个或多个Secret。但是 Secret 只对请求挂载的 POD 中的容器才是可见的。因此,一个 POD 不能访问另一个 POD 的 Secret。
————————————————
版权声明:本文为CSDN博主「kunyus」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/kunyus/article/details/94392696
k8s Operator
Kubernetes 中我们使用的 Deployment, DamenSet,StatefulSet, Service,Ingress, ConfigMap, Secret 这些都是资源,而对这些资源的创建、更新、删除的动作都会被称为为事件(Event),Kubernetes 的 Controller Manager 负责事件监听,并触发相应的动作来满足期望(Spec),这种方式也就是声明式,即用户只需要关心应用程序的最终状态。
当我们在使用中发现现有的这些资源不能满足我们的需求的时候,Kubernetes 提供了自定义资源(Custom Resource)和 opertor 为应用程序提供基于 kuberntes 扩展。
Volume
Volume可以支持`local`、`nfs`、`cephfs`、`glusterfs`以及各种云计算平台
容器和 Pod它们的生命周期可能很短,会被频繁地销毁和创建。容器销毁时,保存在容器内部文件系统中的数据都会被清除。
为了持久化保存容器的数据,可以使用 Kubernetes Volume。
Volume 的生命周期独立于容器,Pod 中的容器可能被销毁和重建,但 Volume 会被保留。
emptyDir
当 Pod 从节点删除时,Volume 的内容也会被删除。但如果只是容器被销毁而 Pod 还在,则 Volume 不受影响。emptyDir 是宿主机 文件系统里的目录,其效果相当于执行了 docker run -v /producer_dir 和 docker run -v /consumer_dir,通过 docker inspect 查看容器的详细配置信息,可以看到挂载到宿主机的目录
hostPath Volume
将 宿主机文件系统中已经存在的目录 mount 给 Pod 的容器,这实际上增加了 Pod 与节点的耦合,限制了 Pod 的使用。如果 Pod 被销毁了,hostPath 对应的目录也还会被保留,从这点看,hostPath 的持久性比 emptyDir 强。
PV与PVC
PersistentVolume & PersistentVolumeClaim
在 k8s-master 节点上搭建了一个 NFS 服务器,目录为 /nfsdata:
创建一个 PV mypv,配置文件 nfs-pv.yml 如下:
kubectl appy -f nfs-pv.yml
STATUS 为 Available,表示 mypv 就绪,可以被 PVC 申请。
apiVersion: v1
kind: PersistentVolume
metadata:
name: mypv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: nfs
nfs:
path: /nfsdata/pv1
server: 172.28.2.210
① capacity 指定 PV 的容量为 1G。
② accessModes 指定访问模式为 ReadWriteOnce,支持的访问模式有:
ReadWriteOnce-该卷可以被单个节点以读写方式挂载
ReadOnlyMany-该卷可以被许多节点以只读方式挂载
ReadWriteMany-该卷可以被多个节点以读写方式挂载
③ persistentVolumeReclaimPolicy 指定当 PV 的回收策略为 Recycle,
支持的策略有:
Retain – 需要管理员手工回收。
Recycle – 清除 PV 中的数据,效果相当于执行 rm -rf /thevolume/*。
Delete – 删除 Storage Provider 上的对应存储资源,例如 AWS EBS、GCE PD、Azure Disk、OpenStack Cinder Volume 等。
④ storageClassName 指定 PV 的 class 为 nfs。相当于为 PV 设置了一个分类,PVC 可以指定 class 申请相应 class 的 PV。
⑤ 指定 PV 在 NFS 服务器上对应的目录。
创建 mypvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: nfs
从 kubectl get pvc 和 kubectl get pv 的输出可以看到 mypvc 已经 Bound 到 mypv,申请成功
接下来就可以在 Pod 中使用存储了,Pod 配置文件 pod.yml 如下:
pod-pvc.yml
apiVersion: v1
kind: Pod
metadata:
name: mypod1
spec:
containers:
- name: mypod1
image: busybox
args:
- /bin/sh
- -c
- sleep 30000
volumeMounts:
- mountPath: "/mydata"
name: mydata
volumes:
- name: mydata
persistentVolumeClaim:
claimName: mypvc
Storageclass
PV和PVC模式是需要运维人员先创建好PV,然后开发人员定义好PVC进行一对一的Bond,但是如果PVC请求成千上万,那么就需要创建成千上万的PV,对于运维人员来说维护成本很高,Kubernetes提供一种自动创建PV的机制,叫StorageClass,它的作用就是创建PV的模板。
具体来说,StorageClass会定义一下两部分:
- PV的属性 ,比如存储的大小、类型等;
- 创建这种PV需要使用到的存储插件,比如Ceph等;
LoadBalancer
LoadBalancer 服务是暴露服务到 internet 的标准方式。在 GKE 上,这种方式会启动一个 Network Load Balancer[2],它将给你一个单独的 IP 地址,转发所有流量到你的服务。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MSzqWDgI-1680158062111)(pic/K8S基础/58241dd10a9618e5e8054ebdad729b8d.png)]
何时使用这种方式?
如果你想要直接暴露服务,这就是默认方式。所有通往你指定的端口的流量都会被转发到对应的服务。它没有过滤条件,没有路由等。这意味着你几乎可以发送任何种类的流量到该服务,像 HTTP,TCP,UDP,Websocket,gRPC 或其它任意种类。
这个方式的最大缺点是每一个用 LoadBalancer 暴露的服务都会有它自己的 IP 地址,每个用到的 LoadBalancer 都需要付费,这将是非常昂贵的。
Ingress
问题:
ingress 与nodeport的区别,以及它是解决什么问题的 。
node port 每个服务都要一个端口,如果服务超级多的时候就需要进行找到可以用的端口,管理起来也比较复杂。
ingress 类似服务器上的nginx
何时使用这种方式?
Ingress 可能是暴露服务的最强大方式,但同时也是最复杂的。Ingress 控制器有各种类型,包括 Google Cloud Load Balancer, Nginx,Contour,Istio,等等。它还有各种插件,比如 cert-manager,它可以为你的服务自动提供 SSL 证书。
如果你想要使用同一个 IP 暴露多个服务,这些服务都是使用相同的七层协议(典型如 HTTP),那么Ingress 就是最有用的。如果你使用本地的 GCP 集成,你只需要为一个负载均衡器付费,且由于 Ingress是“智能”的,你还可以获取各种开箱即用的特性(比如 SSL,认证,路由,等等)。
————————————————
版权声明:本文为CSDN博主「等风来也chen」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44267608/article/details/102728050
Ingress 事实上不是一种服务类型。相反,它处于多个服务的前端,扮演着“智能路由”或者集群入口的角色。
你可以用 Ingress 来做许多不同的事情,各种不同类型的 Ingress 控制器也有不同的能力。
GKE 上的默认 ingress 控制器是启动一个 HTTP(S) Load Balancer[3]。它允许你基于路径或者子域名来路由流量到后端服务。例如,你可以将任何发往域名 foo.yourdomain.com 的流量转到 foo 服务,将路径 yourdomain.com/bar/path 的流量转到 bar 服务。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Sb2nQDGQ-1680158062111)(pic/K8S基础/2d8f2dfed90094f7fda6e784563e07e4.png)]
下面是一个将所有流量都发送到同一 Service 的简单 Ingress 示例:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eT5vrIis-1680158062112)(pic/K8S基础/image-20220303113937526.png)]
与所有其他 Kubernetes 资源一样,Ingress 需要使用 apiVersion、kind 和 metadata 字段。 Ingress 对象的命名必须是合法的 DNS 子域名名称。 有关使用配置文件的一般信息,请参见部署应用、 配置容器、 管理资源。 Ingress 经常使用注解(annotations)来配置一些选项,具体取决于 Ingress 控制器,例如 重写目标注解。 不同的 Ingress 控制器 支持不同的注解。查看文档以供你选择 Ingress 控制器,以了解支持哪些注解。
Ingress 规约 提供了配置负载均衡器或者代理服务器所需的所有信息。 最重要的是,其中包含与所有传入请求匹配的规则列表。 Ingress 资源仅支持用于转发 HTTP 流量的规则。
ServiceAccount
参考k8s原理:角色
参考
https://blog.csdn.net/wzy_168/article/details/102956392
创建RoleBinding,将创建的role和serviceaccount绑定
Service account是为了方便Pod里面的进程调用Kubernetes API或其他外部服务而设计的。它与User account不同
1.User account是为人设计的,而service account则是为Pod中的进程调用Kubernetes API而设计;
2.User account是跨namespace的,而service account则是仅局限它所在的namespace;
3.每个namespace都会自动创建一个default service account
4.Token controller检测service account的创建,并为它们创建secret
5.开启ServiceAccount Admission Controller后
1.每个Pod在创建后都会自动设置spec.serviceAccount为default(除非指定了其他ServiceAccout)
2.验证Pod引用的service account已经存在,否则拒绝创建
3.如果Pod没有指定ImagePullSecrets,则把service account的ImagePullSecrets加到Pod中
4.每个container启动后都会挂载该service account的token和ca.crt到/var/run/secrets/kubernetes.io/serviceaccount/
job
在下面这个 Job 的例子中,Pod 执行了一个跟 π 相关的计算,并打印出最终结果,该计算大约需要 10 秒钟执行结束。
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
namespace
如何在不同团队之间取得资源的公平,不会因为某个流氓团队占据了所有资源,从而导致其他团队无法使用k8s。
kubernetes提供了两种资源限制的方式:ResourceQuota 和LimitRange。
其中ResourceQuota 是针对namespace做的资源限制,而LimitRange是针对namespace中的每个组件做的资源限制。
[root@instance-q2pzfrcc ~]# kubectl describe ns cr-vyzlwpfkixvrngjz
Name: cr-vyzlwpfkixvrngjz
Labels: compute-resource/name=ve_test_resource
owner=bml
Annotations: <none>
Status: Active
Resource Quotas
Name: cr-vyzlwpfkixvrngjz
Resource Used Hard
-------- --- ---
cpu 8 33
limits.cpu 8 33
limits.memory 55120Mi 140116Mi
memory 55120Mi 140116Mi
requests.nvidia.com/gpu 2 4
No resource limits.
一、ResourceQuota是什么
当多个namespace共用同一个集群的时候可能会有某一个namespace使用的资源配额超过其公平配额,导致其他namespace的资源被占用。
这个时候我们可以为每个namespace创建一个ResourceQuota,
- 用户在namespace中创建资源时,quota 配额系统跟踪使用情况,以确保不超过ResourceQuota的限制值。
- 如果创建或更新资源违反配额约束,则HTTP状态代码将导致请求失败403 FORBIDDEN。
- 资源配额的更改不会影响到已经创建的pod。
- apiserver的启动参数通常kubernetes默认启用了ResourceQuota.在apiserver的启动参数–enable-admission-plugins=中如果有ResourceQuota便为启动。
二、使用ResourceQuota
1、首先创建一个namespace
> kubectl create ns gkn
namespace/gkn created
> kubectl get ns
NAME STATUS AGE
default Active 12d
dev Active 10d
gkn Active 13s
1234567
2、创建一个ResourceQuota
> cat gkn-resources.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: gkn-resources
namespace: gkn
spec:
hard:
pods: "4"
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
> kubectl apply -f gkn-resources.yaml
resourcequota/gkn-resources created
> kubectl get resourcequota -n gkn
NAME CREATED AT
gkn-resources 2019-08-02T01:24:24Z
> kubectl describe resourcequota -n gkn
Name: gkn-resources
Namespace: gkn
Resource Used Hard
-------- ---- ----
limits.cpu 0 2
limits.memory 0 2Gi
pods 0 4
requests.cpu 0 1
requests.memory 0 1Gi
3、创建一个deployment并限制资源
> cat <<EOF > k8s-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: crm-portal-deployment
namespace: gkn
labels:
app: crm-portal
spec:
replicas: 1
selector:
matchLabels:
app: crm-portal
template:
metadata:
labels:
app: crm-portal
spec:
imagePullSecrets:
- name: registry
containers:
- name: crm-portal
image: 10.18.37.2:5000/dev/crm-portal:0.1
env:
- name: JAVA_OPTS
value: -Dspring.config.location=/etc_app/application.properties
resources:
requests:
memory: "100Mi"
cpu: "100m"
limits:
memory: "200Mi"
cpu: "500m"
EOF
> kubectl apply -f k8s-deployment.yaml
deployment.apps/crm-portal-deployment created
> kubectl get po -n gkn
NAME READY STATUS RESTARTS AGE
crm-portal-deployment-7f748cd688-spqzq 1/1 Running 0 6s
123456789101112131415161718192021222324252627282930313233343536373839404142
4、多创建几个deployment,使pod使用的资源总和超出resourcequota的限制后再创建deployment,就会发现deployment无法创建pod,并且报错。
首先查看现在的资源使用情况。
> kubectl describe resourcequota -n gkn
Name: gkn-resources
Namespace: gkn
Resource Used Hard
-------- ---- ----
limits.cpu 2 2
limits.memory 2Gi 2Gi
pods 2 4
requests.cpu 200m 1
requests.memory 200Mi 1Gi
12345678910
发现资源已经使用完了,这时再创建一个deployment试试.
> kubectl apply -f k8s-deployment-2.yml -n gkn
deployment.apps/crm-portal-deployment-2 created
> kubectl get po -n gkn
NAME READY STATUS RESTARTS AGE
crm-portal-deployment-1-7f7944cf67-kz8qb 1/1 Running 6 10m
crm-portal-deployment-7f748cd688-c4h6z 1/1 Running 6 9m32s
> kubectl get deployment -n gkn
NAME READY UP-TO-DATE AVAILABLE AGE
crm-portal-deployment 1/1 1 0 5h51m
crm-portal-deployment-1 1/1 1 0 79m
crm-portal-deployment-2 0/1 0 0 46m
12345678910111213
我们发现虽然deployment创建成功了 但是却没有创建对应的pod,我们可以查看deployment报错。
> kubectl describe deployment crm-portal-deployment-2 -n gkn
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 9m13s deployment-controller Scaled up replica set crm-portal-deployment-2-7f748cd688 to 1
1234567
可见是由于已经创建的pod的总和已经超过的namespace总的资源总量限制值而导致的无法创建pod。
总结
在工作中如果有多个环境通过命名空间的方式使用同一个集群资源,可以通过这种方式进行资源限制,避免不同环境之间进行资源争抢。
常用资源类型
| 资源名称 | 描述 |
|---|---|
| limits.cpu | namespace下所有pod的CPU限制总和 |
| limits.memory | 内存限制总和 |
| requests.cpu | CPU请求总和 |
| requests.memory | 内存限制总和 |
| requests.storage | PVC请求的存储值的总和 |
| persistentvolumeclaims | PVC的数量 |
| requests.ephemeral-storage | 本地临时存储请求总和 |
| limits.ephemeral-storage | 本地临时存储限制总和 |
https://ieevee.com/tech/2018/05/14/k8s-quota.html
k8s的解决方法是,通过RBAC将不同团队(or 项目)限制在不同的namespace下,通过resourceQuota来限制该namespace能够使用的资源。资源分为以下三种。
helm(类似与linux上的yum)
Helm 包含两个组件:Helm 客户端 和 Tiller 服务器。
chart 是创建一个应用的信息集合,包括各种 Kubernetes 对象的配置模板、参数定义、依赖关系、文档说明等。chart 是应用部署的自包含逻辑单元。可以将 chart 想象成 apt、yum 中的软件安装包
定义
helm提供了一个应用所需要的所有清单文件。比如对于一个nginx,我们需要一个deployment的清单文件、一个service的清单文件、一个hpa的清单文件。我们把这三个文件打包到一起,就是一个应用程序的程序包,我们称之为Chart。
release 是 chart 的运行实例,代表了一个正在运行的应用。当 chart 被安装到 Kubernetes 集群,就生成一个 release。chart 能够多次安装到同一个集群,每次安装都是一个 release。
helm是k8s的另外一个项目,相当于linux的yum,在yum仓库中,yum不光要解决包之间的依赖关系,还要提供具体的程序包,helm仓库里面只有配置清单文件,而没有镜像,镜像还是由镜像仓库来提供,比如hub.docker.com、私有仓库.
原理
helm是工作在k8s集群之外的。
helm不直接操作apiserver,而是和Tiller交互。Tlller再和apiserver交互,
最后由Apiserver把chart使用config赋值(值文件),最后部署成为release

在 Helm 2 中,Tiller 是作为一个 Deployment 部署在 kube-system 命名空间中,很多情况下,我们会为 Tiller 准备一个 ServiceAccount ,这个 ServiceAccount 通常拥有集群的所有权限。用户可以使用本地 Helm 命令,自由地连接到 Tiller 中并通过 Tiller 创建、修改、删除任意命名空间下的任意资源。
然而在多租户场景下,这种方式也会带来一些安全风险,我们即要对这个 ServiceAccount 做很多剪裁,又要单独控制每个租户的控制,这在当前的 Tiller 模式下看起来有些不太可能。
于是在 Helm 3 中,Tiller 被移除了。新的 Helm 客户端会像 kubectl 命令一样,读取本地的 kubeconfig 文件,使用我们在 kubeconfig 中预先定义好的权限来进行一系列操作。这样做法即简单,又安全。
虽然 Tiller 文件被移除了,但 Release 的信息仍在集群中以 ConfigMap 的方式存储,因此体验和 Helm 2 没有区别。
例子
安装 helm3 install wlog-collect ./wlog-collect
卸载 helm3 delete wlog-collect
1.部署helm
2.部署tiller
helm常用命令
helm search mysql
#helm install --name mysql1 stable/mysql
#helm list
helm ls --all
#helm status mysql1
下载仓库的一个chart
helm fetch stable/mysql
# helm install -n local-path-storage -f ./prometheus-operator/values.yaml prometheus-operator ./prometheus- operator --debug --dry-run
--debug --dry-run 这个是 调试模式
# helm upgrade prometheus-operator -f ./prometheus-operator/values.yaml ./prometheus-operator
1007 helm delete storage
这里的删除其实没有完全删除。
1009 helm ls --all
1010 helm status storage
1014 helm rollback storage 1
1015 helm status storage
在我们install或者fetch时,都会把安装包下载到当前用户的家目录下:
[root@master archive]# ll /root/.helm/cache/archive/
-rw-r--r-- 1 root root 5536 Oct 17 04:50 mysql-0.3.5.tgz
[root@master archive]# cd /root/.helm/cache/archive
[root@master archive]# ls
mysql-0.3.5.tgz
[root@master archive]# tar -xvf mysql-0.3.5.tgz
[root@master archive]# tree mysql
mysql
├── Chart.yaml #描述chart的
├── README.md
├── templates #模板文件
│ ├── configmap.yaml
│ ├── deployment.yaml
│ ├── _helpers.tpl
│ ├── NOTES.txt
│ ├── pvc.yaml
│ ├── secrets.yaml
│ └── svc.yaml
└── values.yaml #自己修改这个文件的相应参数,可以自定义安装包的内容
Helm 常用命令
查看版本
#helm version
查看当前安装的charts
#helm list
查询 charts
helm ls --all
#helm search redis
安装charts
#helm install --name redis --namespaces prod bitnami/redis
查看charts状态
#helm status redis
删除charts
#helm delete --purge redis
增加repo
#helm repo add stable https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
#helm repo add --username admin --password password myharbor https://harbor.qing.cn/chartrepo/charts
更新repo仓库资源
#helm repo update
创建charts
#helm create helm_charts
测试charts语法
#helm lint
打包charts
#cd helm_charts && helm package ./
查看生成的yaml文件
#helm template helm_charts-0.1.1.tgz
更新image
#helm upgrade --set image.tag='v2019-05-09-18-48-40' study-api-en-oral myharbor/study-api-en-oral
回滚relase
#helm hist study-api-en-oral
#helm rollback study-api-en-oral 4
对象关系demo
查看svc与pod与容器三者的关系
[root@node-1 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 138d
nginx NodePort 10.98.167.51 <none> 80:32103/TCP 137d
[root@node-1 ~]# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 192.168.146.11:6443 138d
nginx 10.244.1.62:80 137d
[root@node-1 ~]# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-56f766d96f-4v5nv 1/1 Running 1 15h 10.244.1.62 node-3
k8s 集群只有三个ip
宿主机的ip-----(通过nodeport到达)------>svc的ip ----(通过ep到达)—>pod的ip
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OhdZS3b6-1680158062114)(pic/K8S技术总结.assets/1584523291546.png)]
下图就是2个pod
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hg5MoSlY-1680158062114)(pic/K8S技术总结.assets/1584523753671.png)]
根据 svc 去找pod,可以发现这个俩个pod里面有3个容器
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MO9waSOH-1680158062114)(pic/K8S技术总结.assets/1584524264908.png)]
根据pod 去查看docker镜像
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SPxJnIid-1680158062115)(pic/K8S技术总结.assets/1584524354874.png)]
利用容器服务代理本地服务
spring项目在cm里面读取mysql
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2xuFGs4n-1680158062115)(pic/K8S技术总结.assets/1584526244106.png)]
根据ip找到svc
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tq7053Pm-1680158062116)(pic/K8S技术总结.assets/1584526480396.png)]
根据svc找到pod,然后找到配置文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VogqcUjh-1680158062116)(pic/K8S技术总结.assets/1584526858135.png)]
查看应用的配置文件,如下可以看出代理了三台宿主机mysql
kubectl edit cm haproxy-config
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-frRPRLwA-1680158062116)(pic/K8S技术总结.assets/1584527007467.png)]
K8S yaml 字段说明
yaml 可以 转换成json 查看 ,这样比较方便
有 “-” 是json 的数组
没有的是对象
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
replicas: 3
selector:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
下面简要解释一下上述ReplicationController描述文件中的关键点:
- spec.selector字段指定为你需要管理的Pod的label(label的意义体现在此处)。这儿将spec.selector设置为app: nginx,意味着所有包含label为app: nginx的Pod都将被这个RC管理。
- spec.replicas字段代表了受此RC管理的Pod,需要运行的副本数。
- template模块用于定义Pod,包括Pod的名字,Pod拥有的label以及Pod中运行的应用。
K8S 部署一个应用
使用下面这种打包方式,可以使用 kubectl logs -f ${podname} 查看日志
[root@node-1 mydir]# cd v1/
[root@node-1 v1]# ll
total 33112
-r-------- 1 root root 33898556 Dec 25 18:21 accountmanger.jar
-rw-r--r-- 1 root root 324 Dec 26 14:50 Dockerfile
[root@node-1 v1]# cat Dockerfile
# 拉取JDK8的系统镜像
From openjdk:8-jdk-alpine
# 设置时区
ENV TZ=Asia/Shanghai
# 时区写入系统文件
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezon
VOLUME /tmp
ADD ./accountmanger.jar /
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/accountmanger.jar"]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LKnv5hIK-1680158062117)(pic/K8S技术总结.assets/1588569010446.png)]
访问流程
mysql
node 端口 -> cluster ip 端口 - > pod 的ip端口 ->容器端口
[root@node-2 v1]# cat svc-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: myapp
release: stabel
template:
metadata:
labels:
app: myapp
release: stabel
env: test
spec:
containers:
- name: myapp
image: 192.168.146.12:5000/first:v1.0
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 8080 #容器端口
---
[root@node-2 v1]# cat svc-nodePort.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
type: NodePort
selector:
app: myapp
release: stabel
ports:
- name: http
port: 8080 #service暴露在cluster ip上的端口
targetPort: 8080 #Pod的外部访问端口,数据通过这个端口进入到Pod内部
nodePort: 30080 #Node节点的端口,nodePort 是提供给集群外部客户访问service的入口
nginx
[root@node-1 export]# cat nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginxdeploy
spec:
replicas: 1
selector:
matchLabels:
name: nginxdeploy
template:
metadata:
labels:
name: nginxdeploy
spec:
containers:
- name: nginxdeploy
image: nginx
ports:
- containerPort: 80
[root@node-1 export]# cat nginx-service1.yaml
apiVersion: v1
kind: Service
metadata:
name: nginxdeploy
spec:
type: NodePort
ports:
- port: 82
protocol: TCP
targetPort: 80
name: http
nodePort: 30055
selector:
name: nginxdeploy
myrestful-app
这里使用wangjinlong/helloword8080:v1 镜像测试
默认端口是8080,直接访问就会查看到页面的helloworld
或者访问xx.xx.x.x:8080/helloworld,也可以看到接口返回的hello world
[root@node-1 export]# cat myrestful-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: myapp
release: stabel
template:
metadata:
labels:
app: myapp
release: stabel
env: test
spec:
nodeSelector:
kubernetes.io/hostname: node-1
containers:
- name: myapp
image: wangjinlong/helloword8080:v1
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 8080 #容器端口
[root@node-1 export]# cat myrestful-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
type: NodePort
selector:
app: myapp
release: stabel
ports:
- name: http
port: 8080 #service暴露在cluster ip上的端口
targetPort: 8080 #Pod的外部访问端口,数据通过这个端口进入到Pod内部
nodePort: 30080 #Node节点的端口,nodePort 是提供给集群外部客户访问service的入口
kubernetes GPU
简介
device-plugin、network-plugin、csi-plugin都是k8s推出的插件,都是使用daemonsets方式部署。
需要使用显卡的Pod 怎么使用k8s集群的GPU?
CUDA:是Nvidia推出的只能用于自家GPU的并行计算框架。只有安装这个框架才能够进行复杂的并行计算。主流的深度学习框架也都是基于CUDA进行GPU并行加速的,几乎无一例外。还有一个叫做cudnn,是针对深度卷积神经网络的加速库。
device-plugins
简介
拥有device plugin 时,你可以通过请求 nvidia.com/gpu 资源来使用 GPU 设备,就像pod申请 CPU 和内存资源那样。
从kubernetes1.8版本开始,提供了设备插件框架,设备厂商无需修改kubernetes核心代码就可以将自己生产的设备的资源(kubernetes可管理的资源包括CPU、内存和存储资源)可以让kubelet使用(这一点与操作系统一样,所有设备厂商自己实现驱动)。设备厂商可以自己人工或者以DaemonSet方式部署,而不是定制kubernetes代码。目标设备包括GPU、高性能NIC(网络接口卡)、FPGA、InfiniBand以及其他类似的需要厂商指定初始化和安装的计算资源。
驱动通过plugin 实现了人们通过k8s操作硬件的需求
比如部队使用一个100导弹群,中控室可以在页面控制哪台炮发射。只需要安装device plugin 开放的接口来操作PLC,到达开炮的目的。
比如多个显卡厂商可以按照这个接口实现他们自己的GPU ,以供k8s使用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZjkthTXz-1680158062117)(pic/K8S基础/70.png)]
kubernetes有设备插件框架,那这个框架又是什么样的呢?说白了也很简单,就是kubernetes定义了一套机制和接口,各设备厂商按照协议开发就可以了,这个和Linux驱动原理是一样的,只是实现方式不一样而已。我们来看看kubernetes是怎么实现的,首先我们先说说机制:
厂商自行实现一个管理设备资源的程序,部署到相应的节点上,我们称之为插件;
插件需要向kubelet注册,注册内容要包含自己的endpoint(endpoint就是一个用于通信的地址)以及一些其他信息(后面会说明);
kubelet连接插件的endpoint,就此kubelet和插件就建立了联系;
kubelet监听/var/lib/kubelet/device-plugins/kubelet.sock(unix sockets)这个地址,插件监听的也是类似的地址,只是地址变成了/var/lib/kubelet/device-plugins/gpu.sock(举个例子)
原理
对于每一个硬件设备,都需要它所对应的 Device Plugin 进行管理,这些 Device Plugin 以客户端的身份通过 GRPC 的方式对 kubelet 中的 Device Plugin Manager 进行连接,并且将自己监听的 Unis socket api 的版本号和设备名称比如 GPU,上报给 kubelet。
我们来看一下 Device Plugin 资源上报的整个流程。总的来说,整个过程分为四步,其中前三步都是发生在节点上,第四步是 kubelet 和 api-server 的交互。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g4T3UxyK-1680158062118)(pic/K8S基础/up-a3bc9694d2156f4023f15a94e1bb670464e.png)]
-
第一步是 Device Plugin 的注册,需要 Kubernetes 知道要跟哪个 Device Plugin 进行交互。这是因为一个节点上可能有多个设备,需要 Device Plugin 以客户端的身份向 Kubelet 汇报三件事情:我是谁?就是 Device Plugin 所管理的设备名称,是 GPU 还是 RDMA;我在哪?就是插件自身监听的 unis socket 所在的文件位置,让 kubelet 能够调用自己;交互协议,即 API 的版本号;
-
第二步是服务启动,Device Plugin 会启动一个 GRPC 的 server。在此之后 Device Plugin 一直以这个服务器的身份提供服务让 kubelet 来访问,而监听地址和提供 API 的版本就已经在第一步完成了;
-
第三步,当该 GRPC server 启动之后,kubelet 会建立一个到 Device Plugin 的 ListAndWatch 的长连接, 用来发现设备 ID 以及设备的健康状态。当 Device Plugin 检测到某个设备不健康的时候,就会主动通知 kubelet。
如果这个设备处于空闲状态,kubelet 会将其移除可分配的列表。但是当这个设备已经被某个 Pod 所使用的时候,kubelet 就不会做任何事情,如果此时杀掉这个 Pod 是一个很危险的操作;
-
第四步,kubelet 会将这些设备暴露到 Node 节点的状态中,把设备数量发送到 Kubernetes 的 api-server 中。后续调度器可以根据这些信息进行调度。
Kubernetes如何部署 GPU
部署
- 首先安装 Nvidia 驱动
由于 Nvidia 驱动需要内核编译,所以在安装 Nvidia 驱动之前需要安装 gcc 和内核源码。
- 第二步通过 yum 源,安装 Nvidia Docker2
安装完 Nvidia Docker2 需要重新加载 docker,可以检查 docker 的 daemon.json 里面默认启动引擎已经被替换成了 nvidia,也可以通过 docker info 命令查看运行时刻使用的 runC 是不是 Nvidia 的 runC。
- 第三步是部署 Nvidia Device Plugin
从 Nvidia 的 git repo 下去下载 Device Plugin 的部署声明文件,并且通过 kubectl create 命令进行部署。
如下:
查看物理机依赖包
[root@instance-q2pzfrcc ~]# rpm -qa | grep docker
docker-ce-18.09.7-3.el7.x86_64
docker-ce-cli-18.09.7-3.el7.x86_64
nvidia-container-runtime-2.0.0-3.docker18.09.7.x86_64
nvidia-docker2-2.0.3-3.docker18.09.7.ce.noarch
CPU机器
[root@instance-asdsadsadcds ~]# rpm -qa | grep docker
docker-ce-18.09.7-3.el7.x86_64
docker-ce-cli-18.09.7-3.el7.x86_64
CPU的daemon.json是这样的
[root@gzbh-intelmbx001 images]# cat /etc/docker/daemon.json
{
"hosts": ["tcp://10.36.252.167:8137", "unix:///var/run/docker.sock"],
"init": true,
"init-path": "/usr/bin/docker-init",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
GPU 的daemon.json是这样的
Nvidia-docker
GitHub: https://github.com/NVIDIA/nvidia-docker
Nvidia提供Nvidia-docker项目,它是通过修改Docker的Runtime为nvidia runtime工作,当我们执行 nvidia-docker create 或者 nvidia-docker run 时,它会默认加上 --runtime=nvidia 参数。将runtime指定为nvidia。
当然,为了方便使用,可以直接修改Docker daemon 的启动参数,修改默认的 Runtime为 nvidia-container-runtime
[root@gzbh-intel003 ~]# cat /etc/docker/daemon.json
{
"hosts": ["tcp://10.36.245.149:8137", "unix:///var/run/docker.sock"],
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
GPU镜像原理
下图左边所示,最底层是先安装 Nvidia 硬件驱动;再到上面是通用的 Cuda 工具库;最上层是 PyTorch、TensorFlow 这类的机器学习框架。
上两层的 CUDA 工具库和应用的耦合度较高,应用版本变动后,对应的 CUDA 版本大概率也要更新;而最下层的 Nvidia 驱动,通常情况下是比较稳定的,它不会像 CUDA 和应用一样,经常更新。
同时 Nvidia 驱动需要内核源码编译,如上图右侧所示,英伟达的 GPU 容器方案是:在宿主机上安装 Nvidia 驱动,而在 CUDA 以上的软件交给容器镜像来做。同时把 Nvidia 驱动里面的链接以 Mount Bind 的方式映射到容器中。
这样的一个好处是:当你安装了一个新的 Nvidia 驱动之后,你就可以在同一个机器节点上运行不同版本的 CUDA 镜像了。
nvcc -V 查看cuda版本
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2BqEddgu-1680158062119)(pic/K8S基础/up-30729960fa6829bb9e2f525ee18c4cfa66d.png)]
Device Plugin 异构资源调度流程如下:
- Device plugin 向kubelet上报当前节点资源情况
- 用户通过yaml文件创建负载,定义Resource Request
- kube-scheduler根据从kubelet同步到的资源信息和Pod的资源请求,为Pod绑定合适的节点
- kubelet监听到绑定到当前节点的Pod,调用Device plugin的allocate接口为Pod分配设备
- kubelet启动Pod内的容器,将设备映射给容器
kubernetes如何使用物理GPU
k8s是如何使用nvidia GPU资源。
首先,官方的 NVIDIA GPU 设备插件有以下要求:
- Kubernetes 的节点必须预先安装了 NVIDIA 驱动
- Kubernetes 的节点必须预先安装 nvidia-docker 2.0
- Docker 的默认运行时必须设置为 nvidia-runtime,而不是 runc
- NVIDIA 驱动版本 ~= 384.81
说明
如果你的集群已经启动并且满足上述要求的话,就可以部署 NVIDIA 设备插件,部署完插件之后Kubernetes 将暴露 nvidia.com/gpu 为 可调度的资源。
你可以通过请求 nvidia.com/gpu 资源来使用 GPU 设备,就像pod申请 CPU 和内存资源那样。
不过,使用 GPU 时,在如何指定资源需求有一些限制:
-
GPU只能设置在limits部分,这意味着:
-
- 你可以指定 GPU 的
limits而不指定其requests,Kubernetes 将使用限制值作为默认的请求值; - 你可以同时指定
limits和requests,不过这两个值必须相同。 - 你不可以仅指定
requests而不指定limits值。
- 你可以指定 GPU 的
-
容器(以及 Pod)之间是不共享 GPU 的,GPU 也不可以超配(Overcommitting)。
-
每个容器可以请求一个或者多个 GPU,但是不能使用小数值来请求部分 GPU资源,比如0.2、0.7等 。
-
如果集群内部的不同节点上有不同类型的 NVIDIA GPU,那么你可以使用 节点标签和节点选择器 来将 pod 调度到合适的节点上,并不能自动化的在申请资源的时候指定型号。
查看bml demo
可以看到notebook的限制
Limits:
cpu: 1
memory: 1Gi
nvidia.com/gpu: 1
Requests:
cpu: 1
memory: 1Gi
nvidia.com/gpu: 1
Controlled By: StatefulSet/jupyter-fcb8aw9qsicwqnct
Containers:
notebook:
Container ID: docker://1b790cb68e06580ea562ed120c64ec5aa9f3d78ba32ed5494033a305c7eae6fc
Image: 10.233.0.100:5000/jupyterlab-tensorflow:1.15-cuda10-cudnn7-py36_79fbdbf1-973c-461a-8a72-675c3ce5a9ad
Image ID: docker-pullable://10.233.0.100:5000/jupyterlab-tensorflow@sha256:660e4662284adc28e74a1427b822526f1f664bf51016529cf78304c3144e4cc1
Port: 8888/TCP
Host Port: 0/TCP
Args:
start-singleuser.sh
--ip="0.0.0.0"
--port=8888
--allow-root --debug
State: Running
Started: Tue, 01 Jun 2021 11:40:07 +0800
Ready: True
Restart Count: 0
Limits:
cpu: 1
memory: 1Gi
nvidia.com/gpu: 1
Requests:
cpu: 1
memory: 1Gi
nvidia.com/gpu: 1
Environment:
JUPYTERHUB_API_TOKEN: 8281dccb8a5546d3be3b46ad42598ffe
JPY_API_TOKEN: 8281dccb8a5546d3be3b46ad42598ffe
JUPYTERHUB_ADMIN_ACCESS: 1
JUPYTERHUB_CLIENT_ID: user-85cd0ec2-38cc-45fc-8619-496393a34179-cr-dvh4vfoqlj8esdgt_notebook_test_1622518803
JUPYTERHUB_HOST:
kubernetes如何使用VGPU
背景
用户希望使用Pod A占用半张GPU卡,这在目前Kubernetes的架构设计中无法实现资源分配的记录和调用。这里挑战是多卡GPU共享是实际矢量资源问题,而Extened Resource是标量资源的描述。
针对此问题,我们设计了一个outoftree的共享GPU调度方案,该方案依赖于Kubernetes的现有工作机制:
- Extended Resource定义
- Scheduler Extender机制
- Device Plugin机制
首先是定义了两个新的Extended Resource: 第一个是gpu-mem, 对应的是GPU显存;第二个是gpu-count,对应的是GPU卡数。 通过两个标量资源描述矢量资源, 并且结合这一资源,提供支持共享GPU的工作机制。下面是基本的架构图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-su1vI2O1-1680158062119)(pic/K8S基础/351de72a3a6464189e70ce56b6de0087.jpg)]
方案设计
如上所述,k8s场景下GPU共享方案主要包含三个关键问题,解决思路分别如下:
- 算力共享:初期使用GPU硬件的分时复用功能,后续再根据需求进行优化;只需将同一张卡指定给不同的容器,即可达到共享算力的目的。
- 显存共享:在平台层实现显存切分的功能,根据分配结果对容器内显存使用量进行控制。
- GPU资源调度:用户按照显存申请GPU资源,相比于原生k8s中单一维度的GPU卡分配,扩展分配结果为(GPU卡,显存量)。
整体架构图如图3.1所示,其中灰色部分是需要更改或者添加的模块:
GPU Device Plugin负责采集底层GPU资源的信息,通过Kubelet汇报给ApiServer;
GPU Scheduler根据ApiServer中各节点GPU资源的使用情况对pod进行调度;
GPU Manager负责管理容器的显存使用,在超出上限时不允许再申请显存;
BCuda则代表修改后的cuda库,主要涉及显存相关的API,通过与GPU Manager交互实现显存控制。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cf6xuDOv-1680158062120)(pic/K8S基础/image-20210606202653515.png)]
用户向ApiServer提交pod创建请求后,执行流程如下:
- GPU Scheduler监听到新的pod创建事件,根据显存请求量为其选择合适的节点,并为其分配GPU卡,分配结果为(GPU卡标识,显存量)列表
- 被分配节点上的Kubelet接收到新的pod,通过GPU Device Plugin检查分配结果是否可行,可行时设置容器的NVIDIA_VISIABLE_DEVICES变量
- Kubelet根据分配结果创建容器,启动容器时向GPU Manager注册其可以使用的GPU资源上限limit,同样为(GPU卡标识,显存量)列表
- 容器中运行用户进程,当需要申请显存时,调用BCuda库,BCuda向GPU Manager发送请求,以校验请求量request是否小于容量显存剩余量(资源上限-使用量),若校验成功,则更新GPU Manager中容量显存使用量,然后再通过原生的Cuda逻辑申请显存,否则,向上层返回显存申请失败信息;同理,当进程释放显存时,也需要更新GPU Manager中容器的显存使用量。
- 容器运行结束后,向GPU Manager发送信号,以删除GPU Manager维护的容器显存信息。
核心功能模块
- GPU Share Scheduler Extender: 利用Kubernetes的调度器扩展机制,负责在全局调度器Filter和Bind的时候判断节点上单个GPU卡是否能够提供足够的GPU Mem,并且在Bind的时刻将GPU的分配结果通过annotation记录到Pod Spec以供后续Filter检查分配结果。
- GPU Share Device Plugin: 利用Device Plugin机制,在节点上被Kubelet调用负责GPU卡的分配,依赖scheduler Extender分配结果执行。
具体流程:
- 资源上报
GPU Share Device Plugin 利用 nvml 库查询到 GPU 卡的数量和每张 GPU 卡的显存, 通过ListAndWatch()将节点的 GPU 总显存(数量 显存)作为另外 Extended Resource 汇报给 Kubelet; Kubelet 进一步汇报给 Kubernetes API Server。 举例说明,如果节点含有两块 GPU 卡,并且每块卡包含 16276MiB,从用户的角度来看:该节点的 GPU 资源为 16276 2 = 32552; 同时也会将节点上的 GPU 卡数量 2 作为另外一个 Extended Resource 上报。 - 扩展调度
GPU Share Scheduler Extender 可以在分配 gpu-mem 给 Pod 的同时将分配信息以 annotation 的形式保留在 Pod spec 中,并且在过滤时刻根据此信息判断每张卡是否包含足够可用的 gpu-mem 分配。
————————————————
版权声明:本文为CSDN博主「阿里云云栖号」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yunqiinsight/article/details/88103952
bml的
#找到bml-device-plugin对应的daemonset资源
kubectl get ds -n kube-system | grep bml-device-plugin
# 备份
kubectl get ds -n kube-system bml-device-plugin -oyaml > /data/bml-device-plugin-ds.yaml
# 删除
kubectl delete ds -n kube-system bml-device-plugin
# 找到bml-extender-scheduler对应的daemonset资源
kubectl get ds -n kube-system | grep bml-extender-scheduler
# 备份
kubectl get ds -n kube-system bml-extender-scheduler -oyaml > /data/bml-extender-scheduler-ds.yaml
# 删除
kubectl delete ds -n kube-system bml-extender-scheduler
Scheduler Extender
对Pod进行Vgpu调度
Kubernetes 默认调度器在进行完所有过滤(filter)行为后会通过 http 方式调用 GPU Share Scheduler Extender的filter 方法, 这是由于默认调度器计算 Extended Resource 时,只能判断资源总量是否有满足需求的空闲资源,无法具体判断单张卡上是否满足需求;所以就需要由 GPU Share Scheduler Extender 检查单张卡上是否含有可用资源。
以下图为例, 在由 3 个包含两块 GPU 卡的节点组成的 Kubernetes 集群中,当用户申请gpu-mem=8138时,默认调度器会扫描所有节点,发现 N1 所剩的资源为 (16276 * 2 - 16276 -12207 = 4069 )不满足资源需求,N1 节点被过滤掉。
而 N2 和 N3 节点所剩资源都为 8138MiB,从整体调度的角度看,都符合默认调度器的条件;此时默认调度器会委托 GPU Share Scheduler Extender 进行二次过滤,在二次过滤中,GPU Share Scheduler Extender 需要判断单张卡是否满足调度需求,在查看 N2 节点时发现该节点虽然有 8138MiB 可用资源,但是落到每张卡上看,GPU0 和分别 GPU1 只有 4069MiB 的可用资源,无法满足单卡 8138MiB 的诉求。而 N3 节点虽然也是总共有 8138MiB 可用资源,但是这些可用资源都属于 GPU0,满足单卡可调度的需求。由此,通过 GPU Share Scheduler Extender 的筛选就可以实现精准的条件筛选。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E5vowvzK-1680158062120)(pic/K8S基础/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3l1bnFpaW5zaWdodA==,size_16,color_FFFFFF,t_70.png)]
当调度器找到满足条件的节点,就会委托 GPU Share Scheduler Extender 的 bind 方法进行节点和 Pod 的绑定,这里 Extender 需要做的是两件事情
1、以 binpack 的规则找到节点中最优选择的 GPU 卡 id,此处的最优含义是对于同一个节点不同的 GPU 卡,以 binpack 的原则作为判断条件,优先选择空闲资源满足条件但同时又是所剩资源最少的 GPU 卡,并且将其作为ALIYUN_COM_GPU_MEM_IDX保存到 Pod 的 annotation 中;同时也保存该 Pod 申请的 GPU Memory 作为ALIYUN_COM_GPU_MEM_POD和ALIYUN_COM_GPU_MEM_ASSUME_TIME保存至 Pod 的 annotation 中,并且在此时进行 Pod 和所选节点的绑定
2、调用 Kubernetes API 执行节点和 Pod 的绑定
以下图为例,当 GPU Share Scheduler Extender 要把 gpu-mem:8138 的 Pod 和经过筛选出来的节点 N1 绑定,首先会比较不同 GPU 的可用资源,分别为 GPU0(12207),GPU1(8138),GPU2(4069),GPU3(16276),其中 GPU2 所剩资源不满足需求,被舍弃掉;而另外三个满足条件的 GPU 中, GPU1 恰恰是符合空闲资源满足条件但同时又是所剩资源最少的 GPU 卡,因此 GPU1 被选出。
kubectl配置自动补全
yum install bash-completion
source /usr/share/bash-completion/bash_completion
echo 'source <(kubectl completion bash)' >>~/.bashrc
echo 'source <(kubectl completion bash)' >>~/.bashrc
source ~/.bashrc
kubectl completion bash >/etc/bash_completion.d/kubectl

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HFDUAKTz-1680158068161)(null)]](http://dockone.io/uploads/article/20200323/b4624c80c3f5a6d425838ef519bec32e.jpg){kind=link}
所有评论(0)