如何使用 Keda 自动扩展 Kubernetes Pod - 使用 k6 进行测试
概述 本文演示如何对部署在 Kubernetes 集群中的应用程序进行负载测试,验证自动缩放是否正常工作,并识别潜在的性能瓶颈。 当您在 Kubernetes 上将应用程序部署到生产环境时,您需要监控流量并扩展应用程序以满足一天中不同时间的繁重工作负载。您还需要缩减您的应用程序,以避免产生不必要的成本。手动执行此操作是不切实际的,因为任何时候都可能出现拥堵,包括整个团队都在睡觉的深夜。即使你醒着,
概述
本文演示如何对部署在 Kubernetes 集群中的应用程序进行负载测试,验证自动缩放是否正常工作,并识别潜在的性能瓶颈。
当您在 Kubernetes 上将应用程序部署到生产环境时,您需要监控流量并扩展应用程序以满足一天中不同时间的繁重工作负载。您还需要缩减您的应用程序,以避免产生不必要的成本。手动执行此操作是不切实际的,因为任何时候都可能出现拥堵,包括整个团队都在睡觉的深夜。即使你醒着,在你有机会解决它之前,一个尖峰可能会来来去去。
最好的方法是自动扩展。这可以通过监视自定义指标(例如cpu usage、network bandwidth或http requests per second)来触发。扩展在 Kubernetes 平台上运行的应用程序可以通过以下方式完成:
-
Horizontal : 调整副本数(pods)
-
垂直:调整对容器施加的资源请求和限制
在本文中,我们将重点关注基于自定义指标的水平缩放。您应该选择哪个指标来触发扩展超出了本文的范围。在此示例中,我们将使用http request rate指标,但也可以使用其他指标类型。我们将介绍如何获取这些指标并将它们可视化以进行分析。我们将使用以下内容来执行此任务:
-
k6 OSS:开源负载测试工具。我们将使用它来模拟 Kubernetes 应用程序的繁重流量(负载)。还有k6 cloud,您可以使用它来扩展负载测试,使其超出本地计算和网络基础设施的限制。
-
Prometheus:开源监控平台。当负载测试工具正在运行时,我们将使用它从我们的应用程序和 Kubernetes API 中实时抓取指标。
-
Grafana:开源分析平台。我们将使用它来可视化 Prometheus 收集的实时指标,以便我们可以看到我们的应用程序在一段时间内的性能。下面是如何在 Grafana 仪表板上可视化指标的屏幕截图。
[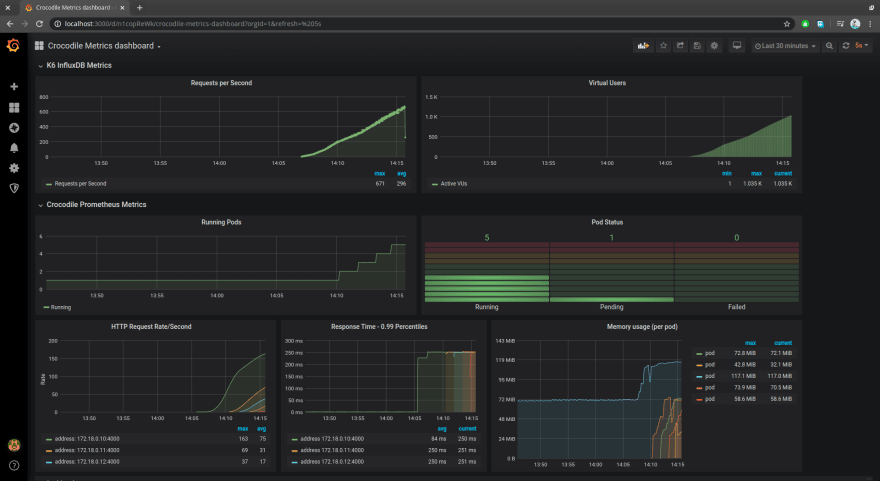 ](https://res.cloudinary.com/practicaldev/image/fetch/s--hD70vm9A--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/ https://dev-to-uploads.s3.amazonaws.com/i/oux0n6prkxndz534oaqj.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--hD70vm9A--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/ https://dev-to-uploads.s3.amazonaws.com/i/oux0n6prkxndz534oaqj.png)
本教程的大纲如下:
-
应用部署
-
Prometheus、Kube 状态指标和 KEDA 部署
-
InfluxDB 和 Grafana 设置
-
使用Keda配置水平Pod Autoscaling
您可以在一台机器上完成整个教程。请注意,结果会出现偏差,因为您的 CPU 将同时处理运行应用程序和对其进行负载测试。为了获得准确的结果,这些任务需要在不同的机器上执行。出于学习和简单的目的,一台机器就足够了。
我们将进行负载测试的应用程序的源代码在我们的GitHub 存储库中提供。负载测试脚本也包含在其中。
下面是整个设置的完整说明:
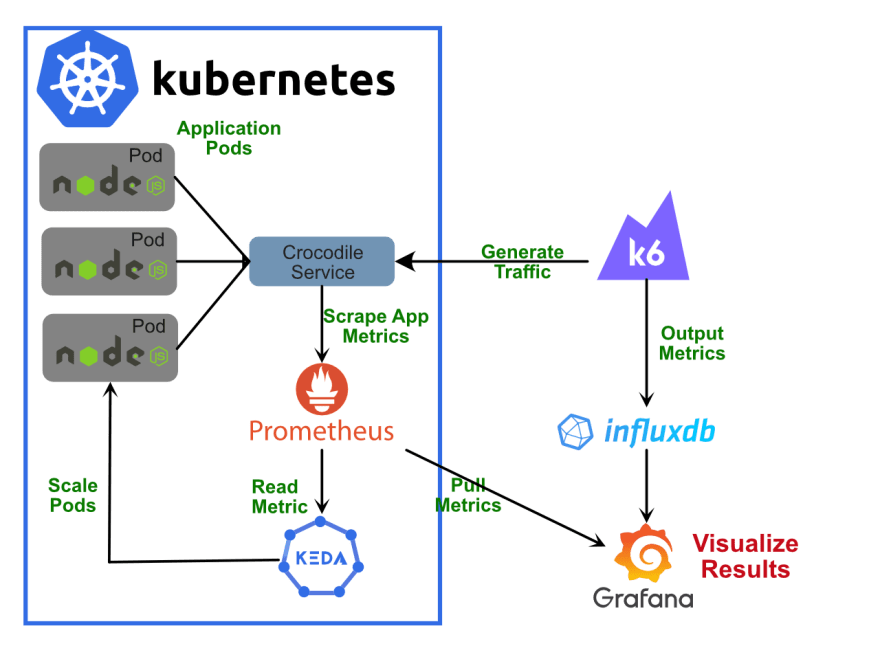
先决条件
本文假设您至少具备运行和配置 Kubernetes 集群的一些基本知识。我们将在本指南中使用Minikube。但是,请随意使用可以在您的计算机上运行的任何其他 k8s 实现。
在我们继续之前,您需要在您的机器上安装以下内容。对于 windows 用户,可以使用Chocolatey包管理器来安装这些需求中的大部分。对于 macOS,请使用brew。对于 Linux,请使用以下链接中提供的说明:
-
ksh
-
Node.js
-
码头工人
-
GNU Make(Linux 预装,macOS 用户安装
xcode) -
kubectl
-
丑
应用程序设置和部署
如果还没有,请立即将示例项目下载到您的工作区:
# Download project
git clone git@github.com:k6io/example-kubernetes-autoscaling-nodejs-api.git
cd example-kubernetes-autoscaling-nodejs-api
# Install dependencies
npm install
# Run development server
npm run dev
进入全屏模式 退出全屏模式
打开 URLhttp://localhost:4000/以确认应用程序正在运行。如果您单击鳄鱼 API 链接或访问 urlhttp://localhost:4000/crocodiles,您应该会看到以下内容:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--6yPZb_RS--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev -to-uploads.s3.amazonaws.com/i/mpow2gpmgewtuz5zdtku.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--6yPZb_RS--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev -to-uploads.s3.amazonaws.com/i/mpow2gpmgewtuz5zdtku.png)
让我们快速检查一下代码。在您喜欢的代码编辑器中打开文件db.json。这是存储数据的地方。如果需要,您可以添加更多记录。接下来打开server.js。这是服务器逻辑所在的完整项目代码。你会看到这是一个简单的项目,它使用json-server包来提供 CRUD API 服务。
如果您观察这部分代码,您会注意到已经实现了人为延迟。由于 API 应用程序非常简单,我们需要将其放慢一点,以帮助我们模拟真实应用程序的结果。
const minDelay = 30;
const maxDelay = 250;
// Add a delay to /crocodiles requests only
app.use('/crocodiles', function (req, res, next) {
let delay = Math.floor(Math.random() * (maxDelay - minDelay)) + minDelay;
setTimeout(next, delay);
});
进入全屏模式 退出全屏模式
我想向您展示的下一部分代码是如何将指标从我们的应用程序导出到 Prometheus。稍后,我们将查询这些指标来监控应用程序的状态。
const prometheusExporter = require('@tailorbrands/node-exporter-prometheus');
const options = {
appName: 'crocodile-api',
collectDefaultMetrics: true,
ignoredRoutes: ['/metrics', '/favicon.ico', '/__rules'],
};
const promExporter = prometheusExporter(options);
app.use(promExporter.middleware);
app.get('/metrics', promExporter.metrics);
进入全屏模式 退出全屏模式
如果您愿意,您可以为您的应用程序定义其他指标。上面的代码将输出几个默认指标。在您的浏览器中,打开 URLhttp://localhost:4000/metrics以查看这些指标:
[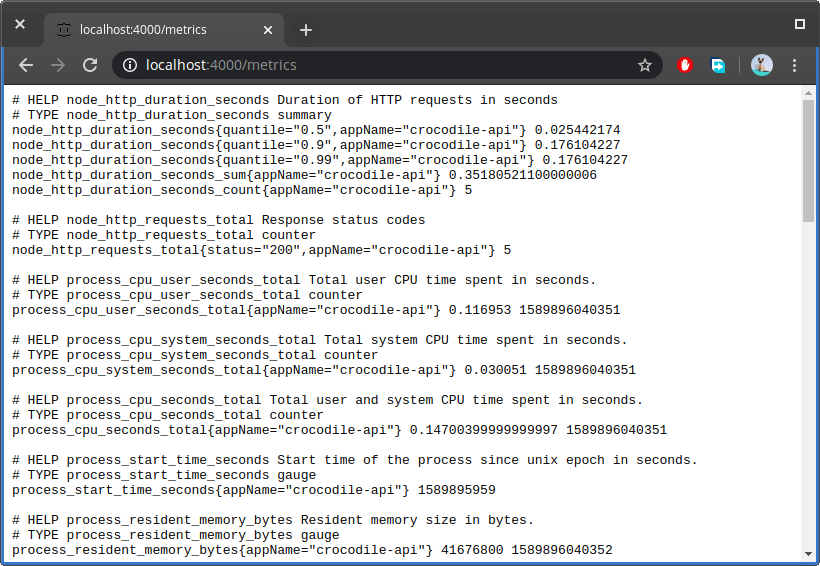 ](https://res.cloudinary.com/practicaldev/image/fetch/s--LgJo10G0--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// /dev-to-uploads.s3.amazonaws.com/i/wpwhc638tuha8xniyxn1.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--LgJo10G0--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// /dev-to-uploads.s3.amazonaws.com/i/wpwhc638tuha8xniyxn1.png)
对于这个应用程序,我们使用 npm 包@tailorbrands/node-exporter-prometheus来帮助我们以与 Prometheus 抓取要求兼容的格式从应用程序中导出指标,而我们几乎不需要付出任何努力。您可以在npmjs 注册表存储库中找到其他适用于 Node.js 应用程序的 Prometheus 客户端库。如果您使用不同的编程语言,您可以在Prometheus 网站上找到官方和非官方的 Prometheus 客户端库。
上面屏幕截图中显示的指标将在您与应用程序交互时更新。只需在浏览器中刷新 URLhttp://localhost:4000/crocodiles或在站点上执行curl命令将导致指标值更新。例如,指标node_http_requests_total跟踪在应用程序上执行 HTTP 请求的次数。请注意指标页面不使用 AJAX。因此,您必须不时刷新才能看到结果。
当您设置 Prometheus 时,它将每 5 到 15 秒获取此指标的值并将其存储在时间序列数据库中。这就是所谓的刮擦。有了这些信息,Prometheus 可以为您绘制图表,以便您查看指标值如何随时间变化。
如果您检查我们的应用程序提供的指标,您会注意到我们有不同的指标类型。对于本指南,我们将重点关注 counter 类型的指标node_http_requests_total。计数器是一个不断上升的累积指标。如果应用程序重新启动,它可以重置为 0。
现在,我们运行 k6 负载测试工具来生成一些流量,我们将可视化这个计数器指标如何随时间变化。在应用程序项目的根目录下,找到脚本performance-script.js,其中包含有关如何执行负载测试的说明。
以下是 k6 负载测试配置的 2 个示例。第一个选项是一个快速的 3 分钟负载测试,可用于快速确认正在捕获指标。第二个选项允许我们在 12 分钟的时间内扩展虚拟用户的数量。这将为我们提供足够的数据来分析我们的自动缩放配置的性能和行为。
// First Load Testing Option : Quick Test with fixed no. of virtual users
export let options = {
duration: '3m',
vus: 200,
thresholds: {
http_req_duration: ['p(95)<700'],
},
};
// Second Load Testing Option : Long Test with varying no. of virtual users
export let options = {
stages: [
{ duration: '1m', target: 50 },
{ duration: '1m', target: 150 },
{ duration: '1m', target: 300 },
{ duration: '2m', target: 500 },
{ duration: '2m', target: 800 },
{ duration: '3m', target: 1200 },
{ duration: '3m', target: 50 },
],
};
进入全屏模式 退出全屏模式
在我们可以运行负载测试脚本之前,我们需要部署 Prometheus 来抓取应用程序的指标。我们的应用程序也需要部署,以便 Prometheus 发现我们的应用程序。要将我们的项目部署到我们的 Kubernetes(minikube) 节点,只需执行以下命令:
# Build the application's docker image inside the minikube's environment
make image
# Deploy the application
make apply
进入全屏模式 退出全屏模式
如果您在执行上述命令时遇到问题,只需访问文件Makefile并执行image和apply部分下的命令即可。下面应该是最后一个命令的输出:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--LHr6soeS--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https ://dev-to-uploads.s3.amazonaws.com/i/30yluiblh7857ptgwog5.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--LHr6soeS--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https ://dev-to-uploads.s3.amazonaws.com/i/30yluiblh7857ptgwog5.png)
记下 IP 地址和端口。在上述情况下,我们可以使用以下地址通过 Web 浏览器访问我们的应用程序:http://10.98.55.109:4000。不幸的是,页面可能会拒绝加载,因为我们尚未完全配置负载均衡器将如何公开我们的服务。一个快速的解决方法是通过在单独的终端中运行以下命令来创建隧道:
minikube tunnel
进入全屏模式 退出全屏模式
一旦隧道启动并运行,您应该能够在浏览器中访问该应用程序。继续下一部分并部署 Prometheus。
部署 Prometheus、Kube State Metrics 和 KEDA
要将 Prometheus 部署到我们的 minikube 节点,请遵循此指南。您还需要部署Kube State 指标。这是一项访问 Kubernetes API 并为 Prometheus 提供与 API 对象(例如部署和 Pod)相关的指标的服务。我们需要这个服务来跟踪正在运行的 pod 的数量。
由于我们正在部署,所以我们还要部署KEDA,这是一个 Kubernetes 事件驱动的自动缩放服务。它与Horizontal Pod Autoscaler一起工作,以根据我们需要指定的阈值向上和向下扩展 Pod。使用 YAML 文件进行部署的说明可以在本页中找到。为方便起见,以下是部署 KEDA 时需要执行的命令:
git clone https://github.com/kedacore/keda && cd keda
kubectl apply -f deploy/crds/keda.k8s.io_scaledobjects_crd.yaml
kubectl apply -f deploy/crds/keda.k8s.io_triggerauthentications_crd.yaml
kubectl apply -f deploy/
进入全屏模式 退出全屏模式
使用命令kubectl get po -A确保我们部署的所有 Pod 都在运行。使用命令kubectl get service -n monitoring查找可以访问 Prometheus 仪表盘的 ip 地址和端口。构建 URL 并在浏览器中启动 Prometheus 仪表板。首先让我们确认 Prometheus 已经从我们的应用程序中发现了指标。从顶部菜单中,转到 Status > Targets 页面并向下滚动到底部并查找标签crocodile-service:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--US7o499n--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https ://dev-to-uploads.s3.amazonaws.com/i/s61m5tidvptlllsdsm9k.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--US7o499n--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https ://dev-to-uploads.s3.amazonaws.com/i/s61m5tidvptlllsdsm9k.png)
如果您看到与上述类似的状态,则可以继续下一步。您还应该确认服务kube-state-metrics也已被发现。在顶部菜单上,单击 Graph 链接以转到图形页面。这是我们输入查询表达式以访问 Prometheus 当前正在抓取的大量信息的地方。
在我们执行查询之前,启动 k6 负载测试工具以获取一些数据来处理。您需要像这样执行加载测试脚本:
ENDPOINT=10.98.55.109:4000/crocodiles k6 run performance-test.js # replace ip address with yours
进入全屏模式 退出全屏模式
在 Graph 页面上,输入此表达式:node_http_requests_total。它应该会在您键入时自动填充。单击 Graph 选项卡,您应该会看到以下输出。
[](https://res.cloudinary.com/practicaldev/image/fetch/s--US7o499n--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880 /https://dev-to-uploads.s3.amazonaws.com/i/s61m5tidvptlllsdsm9k.png)
这是测试完成后结果的可视化方式。注意它在顶部是如何变平的。这是因为测试结束时指标停止增加。如果单击 Table 选项卡,您应该会看到两个如下所示的字段:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--dEgpocwH--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880 /https://dev-to-uploads.s3.amazonaws.com/i/nvvxokpgrim9vlp49n3u.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--dEgpocwH--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880 /https://dev-to-uploads.s3.amazonaws.com/i/nvvxokpgrim9vlp49n3u.png)
node_http_requests_total指标跟踪每个 HTTP 状态代码的请求总数。如果您要运行测试,折线图将从其左侧开始向上拍摄。该指标在当前形式下似乎没有用。
幸运的是,我们可以应用一个函数来使它有用。我们可以使用rate()函数来计算指定持续时间内每秒的请求数。更新表达式如下:
rate(node_http_requests_total[2m])
此函数将为我们提供 2 分钟窗口内每秒的请求数。基本上,它计算增量每秒增加的速度。当增量停止时,rate()函数将为我们提供 0。以下是在表达式中应用rate函数的负载测试结果:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--Rf707Z74--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https ://dev-to-uploads.s3.amazonaws.com/i/rf2kmuxwof3hb55th9lo.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--Rf707Z74--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https ://dev-to-uploads.s3.amazonaws.com/i/rf2kmuxwof3hb55th9lo.png)
如您所见,我们的加载测试脚本以每秒大约 65 个请求的速度达到峰值。当负载测试脚本完成时,曲线回到 0。现在这是一个有用的指标,我们可以使用它来确定是否需要扩展我们的 pod。
在下一节中,我们将设置一个更高级的可视化仪表板,它可以一次显示多个指标并具有自动刷新率。
安装 InfluxDB 和 Grafana
在本节中,我们将安装 InfluxDB,它是一个开源时间序列数据库。 k6 目前不支持将指标数据导出到 Prometheus。但是,k6 支持将指标导出到 Grafana 支持的InfluxDB。
InfluxDB 得到许多工具和应用程序的广泛支持。这为从其他来源(例如Telegraf)收集其他指标数据提供了新的机会。
Grafana是一个开源分析和监控平台,允许工程师构建仪表板,以实时监控来自多个来源的指标。它支持使用表达式将原始度量数据插入到易于使用的信息中。
InfluxDB 和 Grafana 都可以部署在 Kubernetes 节点上。但是,在本地安装它们更容易和更快。不要使用 Docker 选项,因为容器与 Kubernetes 服务通信并不容易。以下是下载链接:
-
下载 InfluxDB: 获取 1.8 OSS 版本
-
下载 Grafana: 获取最新版本
安装这两个应用程序后,请确保服务正在运行。对于 Ubuntu:
sudo systemctl start influxdb grafana-server
进入全屏模式 退出全屏模式
您可以通过influx命令行界面与 influxDB 数据库服务器进行交互。您还可以通过传递查询参数通过http://localhost:8086与 influxDB 进行交互。
通过访问http://localhost:3000访问 Grafana。默认用户名和密码应为admin``admin。如果这不起作用,只需编辑文件/etc/grafana/grafana.ini并确保启用以下行:
[security]
# default admin user, created on startup
admin_user = admin
# default admin password, can be changed before first start of grafana, or in profile settings
admin_password = admin
进入全屏模式 退出全屏模式
您需要重新启动 grafana 服务器才能使更改生效。登录后,您需要转到Configuration>Data Sources并添加以下来源:
-
InfluxDB K6 数据库
-
普罗米修斯数据源
随意使用其他来源。在提供的屏幕截图中,我还安装了Telegraf,这是一项从其他数据库系统、物联网传感器和 CPU、内存、磁盘和网络组件的系统性能指标收集实时指标的服务。我们不会在本文中使用它。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--AghgZII_--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// /dev-to-uploads.s3.amazonaws.com/i/t2b6qpv9h37llheodqlz.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--AghgZII_--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// /dev-to-uploads.s3.amazonaws.com/i/t2b6qpv9h37llheodqlz.png)
以下是我用于 InfluxDB 数据源的设置。此处未提及的其余字段留空或处于默认设置:
-
名称:
InfluxDB-K6 -
网址:
http://localhost:8086 -
访问:
Server -
数据库:
k6 -
HTTP 方法:
GET -
最小时间间隔:
5s
单击Save & Test按钮。如果它说“数据源不工作”,那是因为尚未创建数据库。当您运行以下 k6 命令时,将自动创建数据库:
# replace IP address
ENDPOINT=10.98.55.109:4000/crocodiles k6 run -o influxdb=http://localhost:8086/k6 performance-test.js
进入全屏模式 退出全屏模式
以下是我用于 Prometheus 数据源的设置。
-
姓名:
InfluxDB-K6 -
网址:
http://<prometheus ip address>:8080/ -
访问:
Server -
刮擦间隔:
5s -
查询超时:
30s -
HTTP 方法:
GET
单击Save & Test并确保您收到消息“数据源正在工作”。否则,您将无法进行下一步。
下一步是通过从这个链接导入 Crocodile Metrics Dashboard 创建一个新的仪表板。复制并粘贴 JSON 代码并点击保存。此自定义仪表板将允许您直观地跟踪:
-
HTTP 请求率(来自 k6 和通过 Prometheus 的应用程序)
-
虚拟用户数
-
活动应用程序 pod 的数量及其状态
-
第 99 个百分位响应时间(以毫秒为单位)
-
每个 pod 的内存使用量(以兆字节为单位)
所有面板都易于配置。您可以更改小部件类型、调整查询并显示更多值。您还可以重新组织布局并添加新面板。下面是鳄鱼指标仪表板在安装后的样子:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--TvOVd00V--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https ://dev-to-uploads.s3.amazonaws.com/i/z4llqkicu9bp1sbsiani.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--TvOVd00V--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https ://dev-to-uploads.s3.amazonaws.com/i/z4llqkicu9bp1sbsiani.png)
在下一节中,我们将配置 KEDA 来监控和扩展我们的应用程序。
使用Keda配置Pod水平伸缩
在我们配置 Auto Scaling 之前,让我们运行一个快速的负载测试。打开performance-test.js并确保以下代码处于活动状态:
export let options = {
stages: [
{ duration: '1m', target: 50 },
{ duration: '1m', target: 150 },
{ duration: '1m', target: 300 },
{ duration: '2m', target: 500 },
{ duration: '2m', target: 800 },
{ duration: '3m', target: 1200 },
{ duration: '3m', target: 50 },
],
};
进入全屏模式 退出全屏模式
使用以下命令运行 k6 脚本,确保 InfluxDB 正在收集 K6 指标:
# replace IP address
ENDPOINT=10.98.55.109:4000/crocodiles k6 run -o influxdb=http://localhost:8086/k6 performance-test.js
进入全屏模式 退出全屏模式
Grafana 仪表板应该开始填充数据。随着每秒 http 请求数量的增加,Pod 的数量保持不变。您可以等待负载测试完成,也可以中途取消。
现在让我们配置 KEDA 来监控和扩展我们的应用程序。打开位于项目中的 YAML 配置文件keda/keda-prometheus-scaledobject并分析它:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: default
labels:
deploymentName: crocodile-api
spec:
scaleTargetRef:
deploymentName: crocodile-api
pollingInterval: 10 # Optional. Default: 30 seconds
cooldownPeriod: 15 # Optional. Default: 300 seconds
minReplicaCount: 1 # Optional. Default: 0
maxReplicaCount: 10 # Optional. Default: 100
triggers:
- type: prometheus
metadata:
# Required
serverAddress: http://10.103.240.12:8080
metricName: access_frequency
threshold: '50'
query: sum(rate(node_http_requests_total[2m]))
进入全屏模式 退出全屏模式
记下我们提供的查询:
sum(rate(node_http_requests_total[2m]))
KEDA 将每 10 秒在 Prometheus 上运行一次此查询。我们在表达式中添加了 sum 函数,以便包含来自所有正在运行的 pod 的数据。它将根据我们提供的阈值 50 检查该值。如果该值超过此数量,KEDA 会将正在运行的 Pod 数量增加到最多 10 个。如果该值小于该值,KEDA 会将我们的应用程序 Pod 缩减为 1。要部署此配置,请执行以下命令:
kubectl apply -f keda/keda-prometheus-scaledobject
进入全屏模式 退出全屏模式
再次像以前一样运行 k6 脚本测试,观察 pod 的数量如何随着每秒请求数的增加而增加。以下是测试完成后的最终结果。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--Cf4JjMiV--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// /dev-to-uploads.s3.amazonaws.com/i/ow1mrzrwjczlyh85nfnx.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--Cf4JjMiV--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// /dev-to-uploads.s3.amazonaws.com/i/ow1mrzrwjczlyh85nfnx.png)
请注意 Running Pods 图表。应用程序 pod 的数量随着负载的增加而增加。当负载降低时,pod 的数量也会减少。这就是自动化的美妙之处。
结论
如何使用 Keda 自动扩展 Kubernetes Pod - 使用 k6 进行测试
-
如何使用 KEDA 和 Prometheus 自动缩放 Pod
-
如何使用 Grafana 分析和可视化指标
-
如何从应用程序和服务中提取指标
使用您手头的信息,您可以对任何应用程序进行基准测试并准确监控性能。除了应用程序指标,您还可以使用:
-
CPU 使用率
-
内存使用情况
-
网络使用情况
-
磁盘使用情况
-
数据库性能
-
温度
但是,我想指出一些我们在这里没有涉及到的重要事实,您需要了解:
-
对于现实世界的应用程序,您将拥有一个包含数据库的单独 pod。此类 Pod 的数据在横向扩展时需要同步。
-
您需要确定对扩展有意义的请求率阈值
您可以监控的指标越多,就越容易识别影响应用程序性能的瓶颈。例如,如果您的应用程序的 CPU 使用率很高,则优化代码可以大大提高性能。如果磁盘使用率很高,那么使用内存缓存解决方案会大有帮助。
关键是,在处理繁重的流量时,扩展应用程序 pod 的数量不应该是唯一的解决方案。应考虑垂直扩展或增加节点数量,这样可以大大提高重负载时的性能。通过使用 k6 负载测试工具,并使用 Grafana 分析结果,您可以发现应用程序的瓶颈所在。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献4375条内容
已为社区贡献4375条内容

所有评论(0)