【AI】智能体的上下文工程
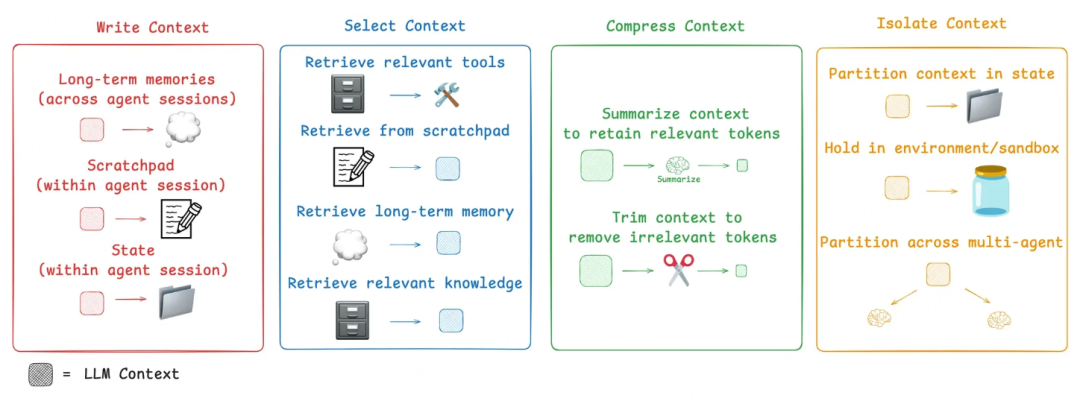
智能体(Agents)执行任务时,离不开指令说明、外部知识、工具反馈等“上下文”信息的支撑。所谓上下文工程,就是在智能体执行任务的全流程中,精准筛选合适信息填入“上下文窗口”的技术实践——既有技术规范要求,也需结合场景灵活调整。撰写上下文:把暂时不用的信息存到窗口外,留给后续任务用;筛选上下文:挑关键信息放进窗口,辅助当前任务;压缩上下文:只留任务必需的令牌(Tokens),节省窗口空间;隔离上下
一、上下文工程概述
智能体(Agents)执行任务时,离不开指令说明、外部知识、工具反馈等“上下文”信息的支撑。所谓上下文工程,就是在智能体执行任务的全流程中,精准筛选合适信息填入“上下文窗口”的技术实践——既有技术规范要求,也需结合场景灵活调整。
上下文工程的核心策略可分为四类,而 LangGraph(一款智能体开发框架)正是为支持这些策略设计的:
-
撰写上下文:把暂时不用的信息存到窗口外,留给后续任务用;
-
筛选上下文:挑关键信息放进窗口,辅助当前任务;
-
压缩上下文:只留任务必需的令牌(Tokens),节省窗口空间;
-
隔离上下文:拆分复杂信息,减少干扰,提升效率。
二、上下文工程的定义
1. 概念起源与核心类比
“上下文工程”由OpenAI联合创始人哈里森・蔡斯(Harrison Chase)提出,随后成为智能体开发领域的热点。想快速理解它的本质,AI专家卡帕西(Karpathy)的类比很直观:
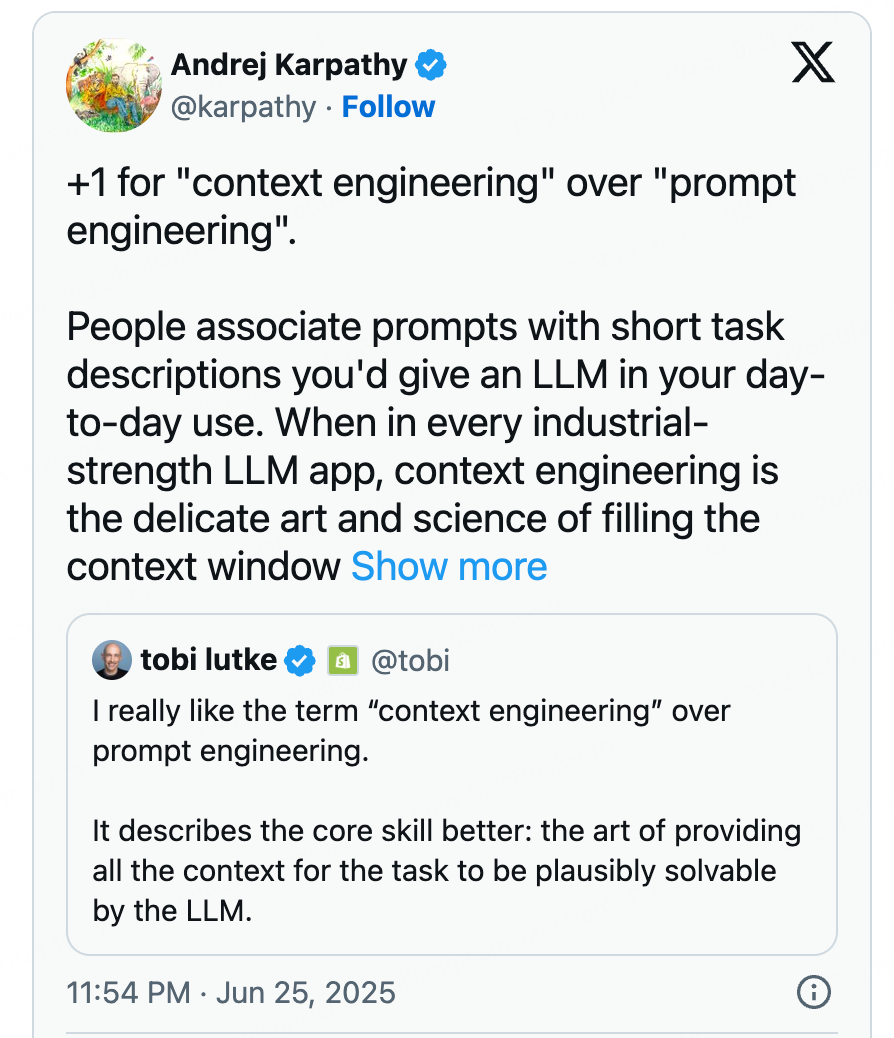
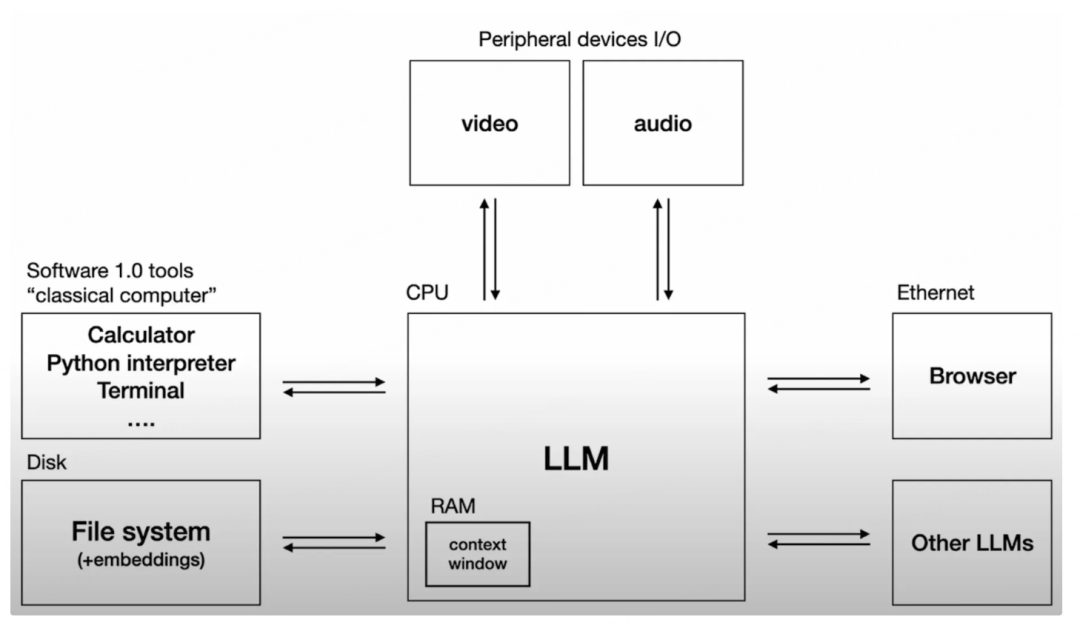
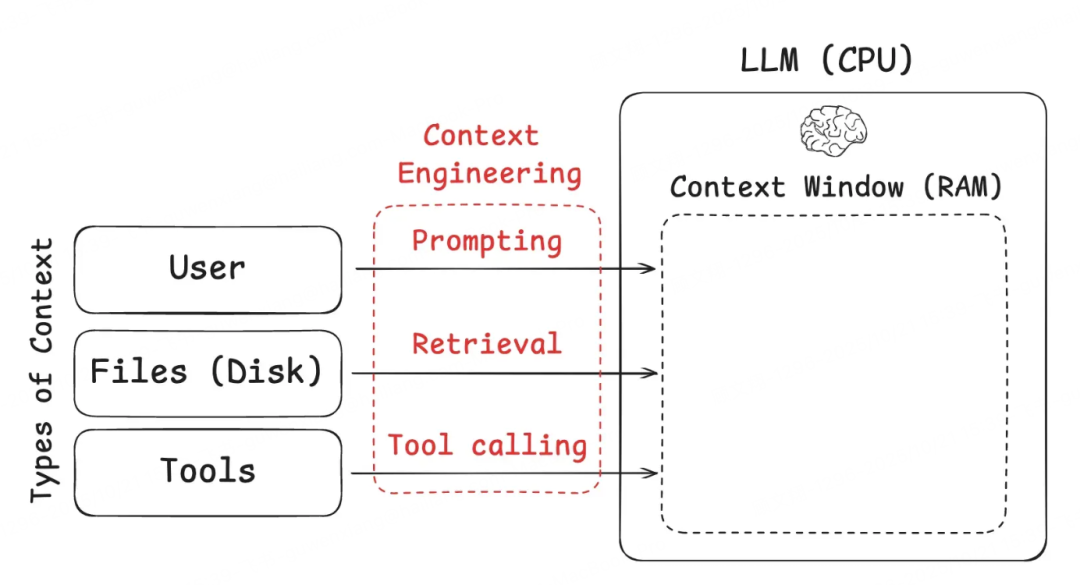
意思就是我们可以把大语言模型(LLMs)看作计算机的“CPU”,是核心运算部件;上下文窗口则像“内存(RAM)”,临时存放任务所需信息,但容量有限,不能无限制装东西。因此,上下文工程就像“内存管理”——通过筛选、整理信息,让“内存”里只留当前任务最需要的内容,不浪费空间、不造成信息拥堵。
2. 上下文的三类核心类型
上下文工程主要管理三类关键信息,它们共同构成智能体干活的“信息基础”:
-
指令类:包括提示词、历史记录、参考案例、工具使用说明等,明确“要做什么、该怎么干”;
-
知识类:包括事实数据、行业常识、过往经验等,提供解决问题的“知识库”;
-
工具类:包括API返回结果、数据库查询数据等工具反馈,帮智能体调整后续操作。
三、智能体上下文工程的难点
与只处理单一任务的语言模型相比,智能体管理上下文会更难,关键有三个原因:
-
任务周期长:智能体常处理科研分析、代码开发等多步骤任务,上下文会越积越多,容易超出窗口容量;
-
信息来源杂:要整合工具反馈、人类输入、历史记忆等多种信息,这些信息可能矛盾或重复;
-
信息易失效:工程师德鲁・布鲁尼格(Drew Breunig)总结的四类问题,会进一步增加管理难度。
任务流程示意:
人类 → 系统消息 → 智能体 → 工具调用(回合1)→ 反馈
↓
工具调用(回合2)→ 反馈
↓
人类输入 → 反馈
-
上下文污染:模型编的假信息混入上下文,导致后续决策出错;
-
上下文干扰:无关信息占满窗口,模型没法专注核心任务;
-
上下文混淆:冗余信息搅乱判断,模型抓不住关键需求;
-
上下文冲突:不同来源信息矛盾(如工具反馈和旧知识不符),模型不知该信哪个。
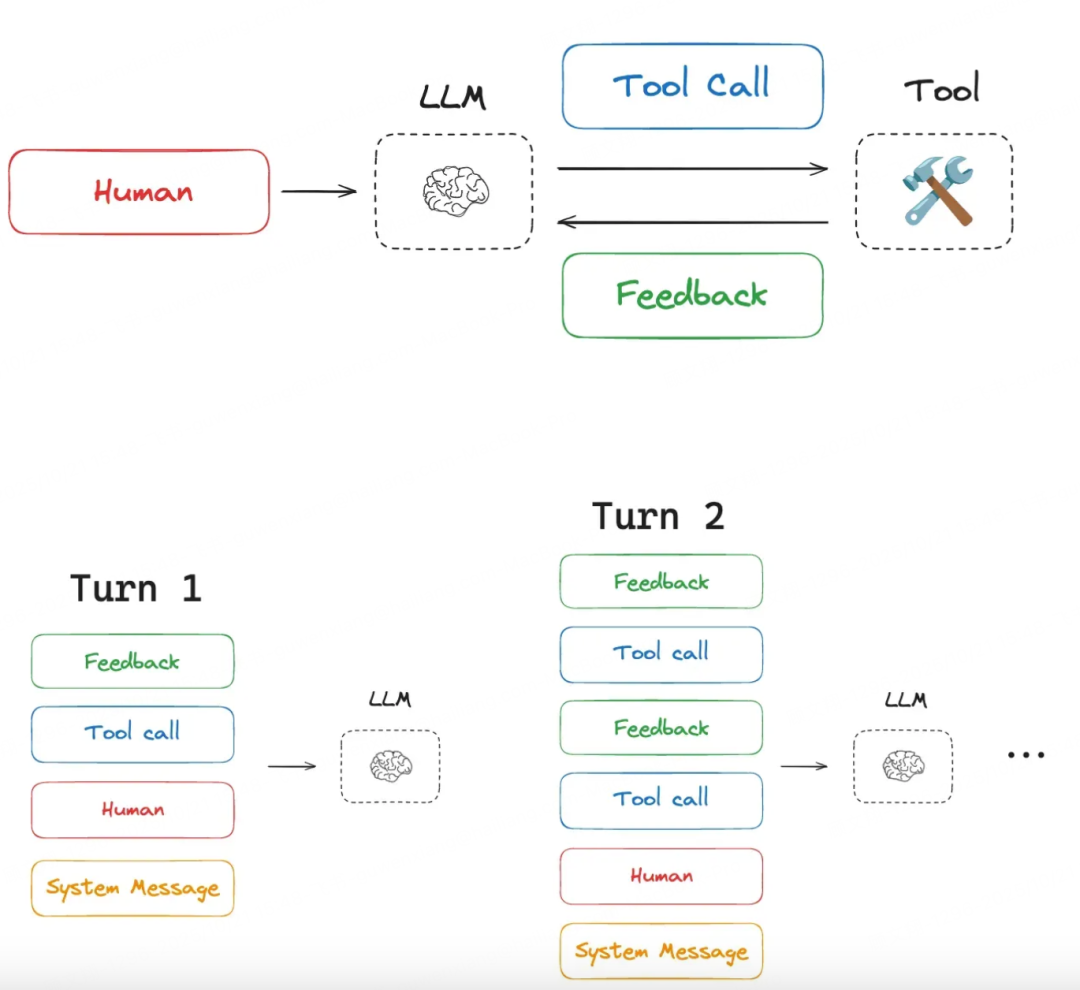
正因如此,上下文工程成为了智能体开发的核心环节。行业内有个共识:AI智能体工程师的首要工作,就是做好上下文管理。
四、上下文工程的四大核心方法
1. 撰写上下文
定义
把暂时不用、但后续可能需要的信息,存到上下文窗口外的地方,就像我们干活时“记笔记、存资料”,避免当前窗口被占满。
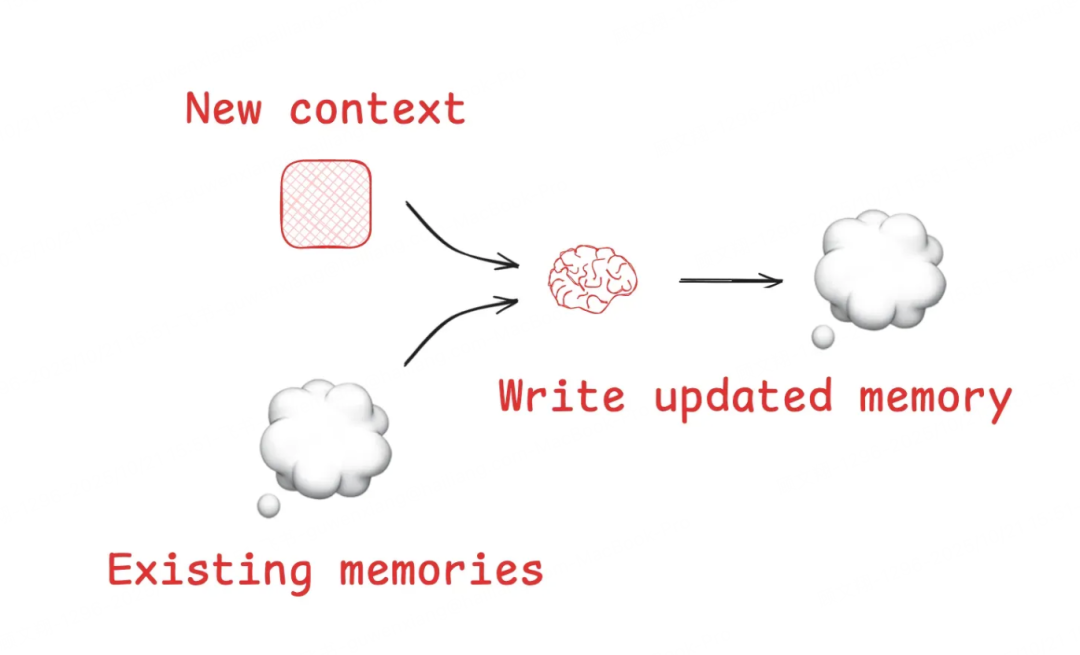
两大核心载体
-
临时记事本(Scratchpads):存当前任务的临时信息,比如任务计划、计算到一半的结果,确保干活时这些信息不会丢。 举个例子:Anthropic公司的“多智能体研究员系统”中,主导智能体先制定研究方案,然后存到临时记事本里。因为这个系统的上下文窗口最多装20万令牌,方案直接放进去的话,后面信息一多就可能被挤掉,存到外面就能全程用得上。 技术上很简单,用Python字典这类运行时对象,或者JSON、TXT等本地文件就能存。
-
长期记忆库(Memories):存跨任务、跨会话的信息,比如用户偏好、过往经验,让智能体能“越用越熟”。 比如“生成式智能体”技术能从历史反馈里提炼有用记忆;我们常用的ChatGPT、代码编辑器Cursor,都能自动记着和用户的交互内容,下次干活时更贴合需求。 原理也不复杂:有新信息产生时,系统自动更新记忆库,保证信息最新、最相关。
2. 筛选上下文
定义
从临时记事本、长期记忆库等外部存储里,挑出和当前任务最相关的信息放进窗口,避免无关信息浪费资源。
三类关键筛选对象
-
记忆类信息:主要分三种—— 一是“参考案例”,比如之前做过的类似任务记录,照着就能干; 二是“操作规则”,比如调用API的参数格式,跟着做不会错; 三是“事实数据”,比如2024年GDP数据,能支撑准确决策。 这些信息通常存在规则文件(如CLAUDE.md)或结构化数据集里,方便提取。
-
工具类信息:用检索增强生成(RAG)技术,从工具说明书里挑出功能、用法等关键信息。有研究说,这么做能让智能体选对工具的概率提高3倍。
-
知识类信息:RAG技术也是核心手段。比如代码智能体干活时,会用它从知识库中找出相关代码片段、技术文档,实时获取知识支持。
3. 压缩上下文
定义
把上下文里的信息“瘦个身”,删掉重复描述、无关细节,只留任务必需的令牌,让有限的窗口空间能装下更多关键内容。
核心逻辑与场景
-
核心逻辑:就是“提炼重点”。比如把1000字的工具反馈,总结成200字的核心结论;或者把窗口里没用的旧指令删掉。
-
常用场景:分析长论文、多轮聊天等任务中,压缩早期信息能给新内容腾出空间,避免窗口装不下。
4. 隔离上下文
定义
把复杂的上下文按任务阶段、信息类型拆成独立模块,避免不同信息互相干扰,让智能体更专注于当前需要的内容。
技术实现与场景
-
存储隔离:把不同信息存到独立“沙箱”里,比如用户需求和工具反馈分两个地方存;
-
任务隔离:多任务智能体里,给每个任务单独分配上下文模块,比如调试代码和写文档各用各的;
-
好处:能解决信息“打架”“干扰”的问题。比如调试代码时的报错信息,就不会影响写文档的语言风格了。
五、核心总结
上下文工程是智能体落地的“关键基础设施”。它通过“撰写、筛选、压缩、隔离”四大策略,解决了智能体长期任务中“信息装不下、干扰多、记不住”的核心问题。像Anthropic的多智能体系统、ChatGPT的记忆功能,本质都是上下文工程的实际应用。

助力合肥开发者学习交流的技术社区,不定期举办线上线下活动,欢迎大家的加入
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)